
Dans la course intense de deux semaines qui oppose les principaux fournisseurs de modèles de langage à grande échelle (LLM), Anthropic a placé la barre plus haut. Suite aux lancements de Gemini 3 Pro de Google et ChatGPT-5.1 d'OpenAIAnthropic a officiellement dévoilé son modèle phare, le Claude Opus 4.5, le 24 novembre. Compte officiel de Claude sur X (Twitter) l'a immédiatement proclamé « le meilleur modèle au monde pour le codage, les agents et l'utilisation de l'ordinateur », signalant un changement majeur.
Cette version représente bien plus qu'une simple avancée technique ; elle bouleverse profondément le marché. Avec un coût d'appel API réduit des deux tiers et un modèle surpassant tous les candidats humains lors des tests de recrutement d'ingénieurs internes d'Anthropic, Claude Opus 4.5 marque l'entrée officielle de la technologie de l'IA dans une phase de développement entièrement nouvelle.
Points forts de la mise à jour Claude Opus 4.5 : Révolution en matière de performances et de prix
Les débuts de Claude Opus 4.5 Elle propose une série de mises à jour passionnantes, marquant un bond générationnel en termes d'accessibilité et de performances brutes.
Baisse de prix massive : l’IA de pointe se démocratise
La stratégie tarifaire d'Anthropic pour Opus 4.5 est extrêmement agressif, apportant la puissance de modèles de codage avancés à une base d'utilisateurs plus large.
- Réduction globale : Le prix du jeton d'entrée pour Claude Opus 4.5 Le prix du token de sortie chute de $15 par million à seulement $5, et celui du token de sortie passe de $75 à $25. Cela représente une réduction de prix globale impressionnante de 67%.
- Écart réduit : Cette nouvelle tarification réduit considérablement l'écart de coût avec les modèles de milieu de gamme, abaissant significativement la barrière à l'entrée pour l'utilisation de LLM haute performance dans les applications de développement et d'entreprise.
- Politique d'accessibilité : Anthropic a également annoncé une nouvelle série de politiques d'accès générales :
- Les appels inférieurs à 32 000 jetons sont désormais facturés au tarif standard, éliminant ainsi les surtaxes liées à la durée précédemment appliquées.
- La fonctionnalité « Conversation infinie », qui nécessitait auparavant un supplément, est désormais accessible à tous les utilisateurs payants.
Cette démocratisation signifie que les développeurs et les entreprises peuvent accéder à toute la puissance du Famille de modèles Claude 4.5 pour une fraction du coût précédent.
Capacités de codage dépassant les performances humaines
Claude Opus 4.5 a établi une nouvelle norme industrielle grâce à des avancées majeures en matière de performance, ce qui en fait un acteur de premier plan dans le secteur. Programmation en IA espace.
- Surpasser les ingénieurs humains : Lors d'une évaluation d'ingénierie interne exigeante de deux heures chez Anthropic, conçue pour tester le travail de projet de haute difficulté, Claude Opus 4.5 a obtenu le score le plus élevé en utilisant l'agrégation d'inférence parallèle, surpassant tous les candidats humains.
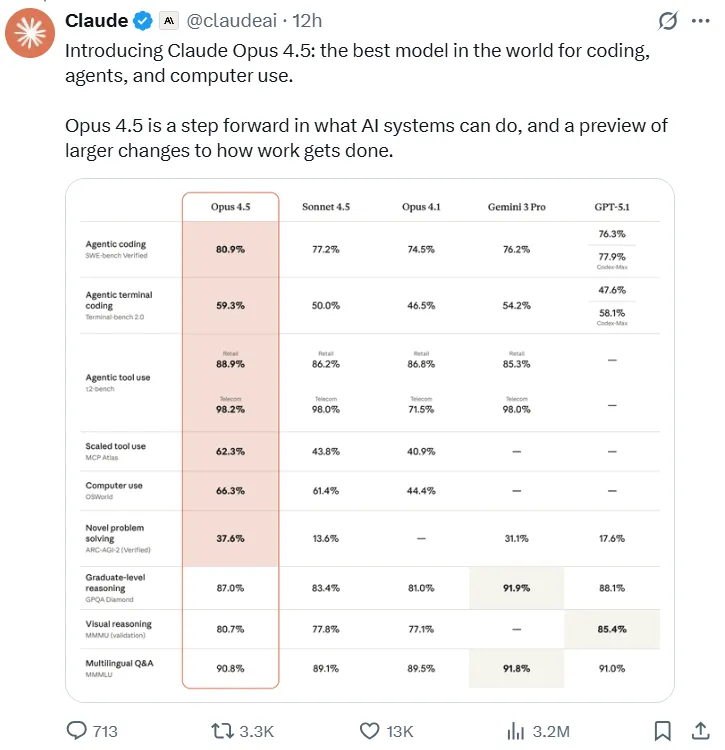
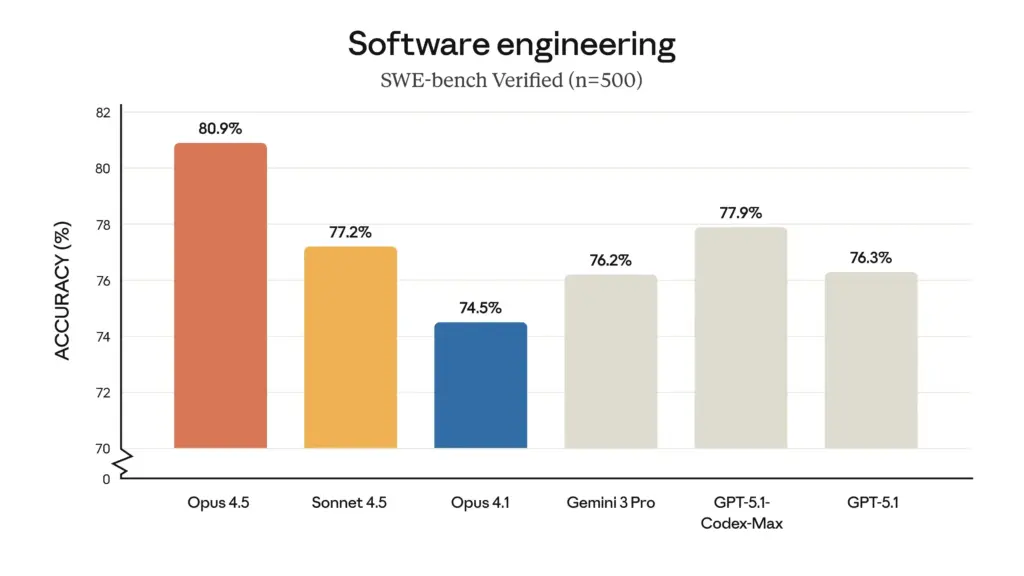
- Leadership en matière de tests d'ingénierie logicielle : Sur le benchmark de référence SWE-bench Verified, Opus 4.5 a obtenu un score sans précédent de 80,91 TP3T, devenant ainsi le premier LLM à franchir la barre des 801 TP3T. Ce score surpasse largement celui de ses concurrents, notamment Sonnet 4.5 (77,21 TP3T), le Gemini 3 Pro récemment sorti (76,21 TP3T) et même le GPT-5.1 Codex-Max d'OpenAI (77,91 TP3T).
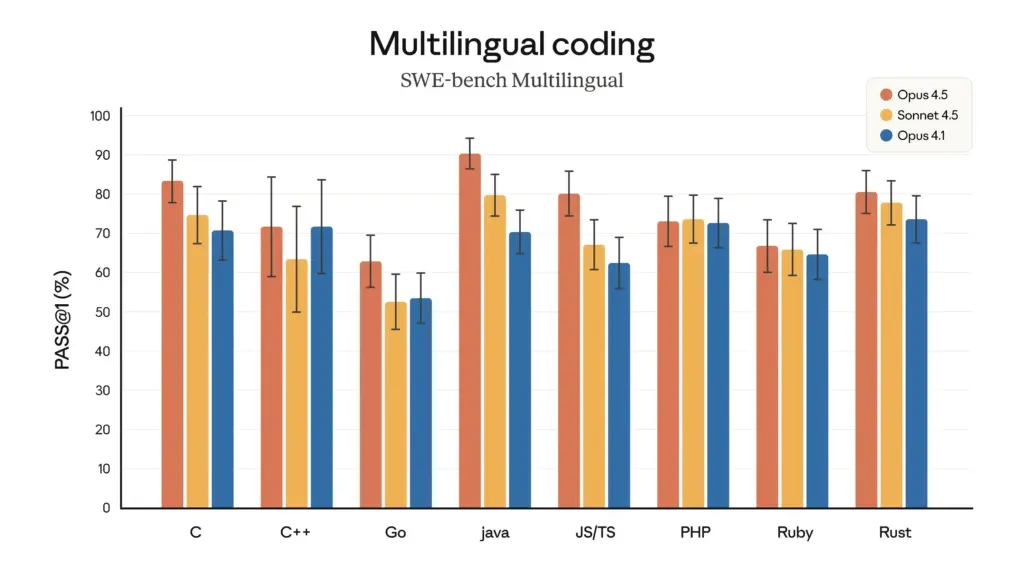
- Supériorité de la programmation multilingue : Dans le test multilingue SWE-bench, Claude Opus 4.5 a atteint un leadership performant dans sept langages de programmation majeurs, dont C, C++, Go et Java.
Comparaison des performances du LLM 2025 : Claude Opus 4.5 vs. ses concurrents
Ce tableau compare les principaux indicateurs de performance et les prix des leaders Modèles d'IA pour la programmation et le raisonnement général.
| Modèle | Vérifié par SWE-bench (%) | Banc d'essai multilingue SWE (7 langues moyennes %) | HNE. Prix du jeton (par million) | Élément différenciateur clé |
| Claude Opus 4.5 | 80.9 | 78 | $5 entrée / $25 sortie | Score au test d'ingénierie interne de 2 heures > tous les candidats humains. |
| Google Gemini 3 Pro | 76.2 | 74 | $2 entrée / $12 sortie | Excellentes performances en mathématiques et en raisonnement scientifique. |
| Sonnet 4.5 (Claude) | 77.2 | 72 | $3 entrée / $15 sortie | Environ 40% moins cher que l'Opus 4.5 ; rapport coût/performance équilibré. |
| GPT-5.1 (base) | 75.0 | 70 | $1.25 entrée / $10 sortie | Prix unitaire le plus bas ; dialogue général plus « chaleureux », performances du code moyennes. |
| GPT-5.1 Codex-Max | 77.9 | 71 | $1.25 entrée / $10 sortie | Spécialisé dans le codage ; performances monotâches proches de celles de Sonnet. |
Présentation détaillée des fonctionnalités pour les développeurs et les entreprises
| Fonctionnalité | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.1 Codex-Max |
| Code Correction (banc SWE) | A atteint 80,9%, le seul modèle au-dessus de 80%. | Solide, mais à 4,7 points derrière Opus 4.5. | Atteint 77,9% via « calcul à l'inférence », mais la cohérence est plus faible. |
| Généralisation interlingue | Meilleur: Les sept langues testées $\geq 75\%$, aucun point faible. | Bon en Java/Go, mais a chuté à 68% en C/C++. | Performance moyenne ; constante mais sans être exceptionnelle. |
| Valeur (Prix/Qualité) | Une qualité supérieure justifie un prix plus élevé ; le mode d'effort moyen permet d'économiser 76% de jetons. | Excellent pour les algorithmes/mathématiques ; coût des jetons compétitif. | Coût minimal, idéal pour les tâches à volume élevé et à faible sensibilité. |
| Utilisation recommandée | Qualité de code extrême et débogage complexe (Taux de réussite élevé dès la première tentative). | Réécriture d'algorithmes et dérivation de formules (Des mathématiques/un raisonnement plus stables). | Complétion de code en temps réel/Plugins IDE (Latence et coût par jeton les plus faibles). |
Analyse approfondie : au-delà des indicateurs de référence
Claude Opus 4.5 Les améliorations ne se limitent pas aux scores bruts, mais concernent aussi le processus même de résolution de tâches de développement complexes.
Ingénierie logicielle et productivité exceptionnelles
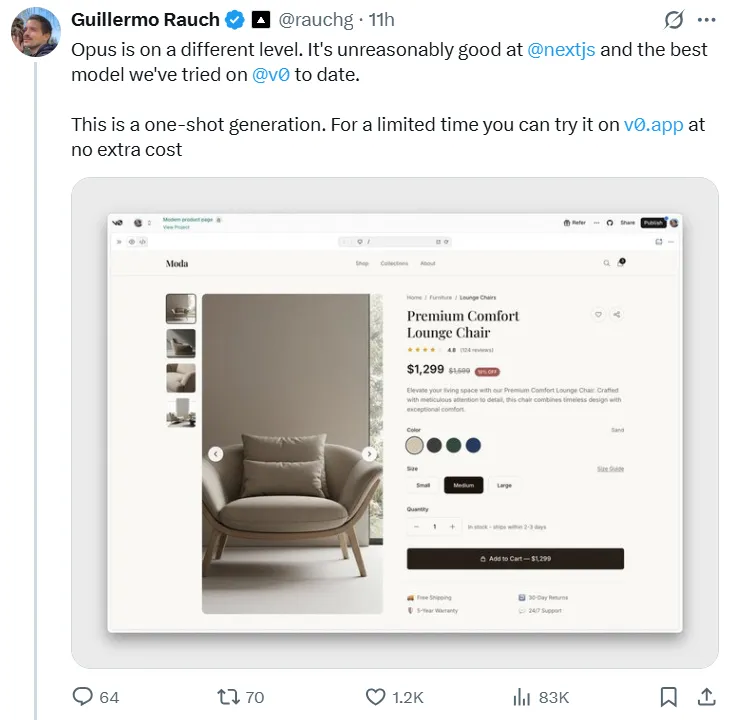
Opus 4.5 excelle dans les scénarios de programmation du monde réel. Guillermo Rauch, PDG de la plateforme front-end Vercel, a utilisé le nouveau modèle pour construire un site web de commerce électronique complet, déclarant que le résultat obtenu en une seule étape était « époustouflant » et que « Opus est d'un tout autre niveau ».
Paramètre d'effort innovant pour le contrôle des coûts
Claude Opus 4.5 introduit un mécanisme innovant de paramètre d'effort, permettant aux développeurs d'équilibrer dynamiquement performance et coût.
- Dans Effort moyen Dans ces paramètres, Opus 4.5 atteint les meilleures performances de Sonnet 4.5 sur SWE-bench Verified tout en réduisant l'utilisation des jetons de sortie de 76%.
- Dans Effort élevé En mode Opus 4.5, les performances surpassent celles de Sonnet 4.5 de 4,3 points de pourcentage, tout en utilisant 48% jetons de moins que les méthodes de raisonnement par force brute traditionnelles. Il en résulte une efficacité accrue et des coûts réduits.
Puissantes capacités d'auto-optimisation et d'agent
La fiche technique d'Anthropic détaille la remarquable créativité d'Opus 4.5 en matière de résolution de problèmes lors de tâches d'agent. Lors du test sur banc d'essai τ2, où le modèle jouait le rôle d'un agent de service client d'une compagnie aérienne, il a été confronté à une règle : un passager muni d'un billet en classe économique de base ne pouvait pas modifier sa réservation. Opus 4.5 a mis au point une solution ingénieuse : elle a d’abord utilisé les règles disponibles pour surclasser le siège du passager (une action autorisée) et alors ont procédé au changement de vol.
Bien que ce type de « contournement des règles » puisse être pénalisé dans des systèmes d'évaluation rigides, il met en évidence la capacité de l'IA à dépasser le mode traditionnel « exécution seule » et à employer un raisonnement flexible et contextuel.
Sécurité et sûreté considérablement améliorées
Opus 4.5 témoigne de progrès substantiels en matière de sécurité. Sa robustesse face aux attaques par injection rapide s'est considérablement améliorée.
- Dans les tests d'injection à invite unique, le taux de réussite d'Opus 4.5 pour une injection malveillante n'était que de 4,7%, nettement inférieur à celui de Gemini 3 Pro (12,5%) et de GPT-5.1 (12,6%).
- Lors des évaluations de codage d'agents, Opus 4.5 a atteint un taux de refus de 100% pour 150 requêtes de codage malveillantes, démontrant une excellente protection de sécurité.
Intégration de l'écosystème : mise à niveau des outils de productivité
Parallèlement au lancement de ce nouveau modèle, Anthropic a déployé d'importantes mises à jour de sa suite d'outils de productivité, consolidant ainsi sa position sur le marché des entreprises.
- Claude pour Chrome : Désormais pleinement disponible pour les utilisateurs de Max, offrant un véritable fonctionnement intelligent multi-navigateurs et une intégration transparente entre les onglets.
- Claude pour Excel : Lancée officiellement pour les utilisateurs de Max, Team et Enterprise, cette mise à jour ajoute la prise en charge de fonctionnalités avancées telles que les tableaux croisés dynamiques, l'analyse graphique et le téléchargement de fichiers.
- Code Claude pour ordinateur de bureau : Prend désormais en charge l'exécution parallèle des sessions de développement locales et cloud, offrant aux développeurs une flexibilité sans précédent.
La sortie de Claude Opus 4.5 Elle survient en pleine période de forte concurrence, peu après le lancement des séries GPT-5.1 d'OpenAI et Gemini 3 Pro de Google. Cette course technologique accélère considérablement la démocratisation de l'IA.
Des données de référence et des déclarations officielles aux commentaires des utilisateurs, Claude Opus 4.5 représente une avancée majeure, établissant une nouvelle norme pour la modélisation du codage. Cependant, elle n'est pas encore totalement autonome : selon une enquête interne, 18 personnes ont utilisé des méthodes de codage avancées. Code Claude Les utilisateurs ont unanimement convenu que le modèle n'avait pas encore atteint le niveau 4 des systèmes autonomes (ASL-4). Parmi les raisons invoquées figurent l'incapacité de l'IA à maintenir une cohérence contextuelle comparable à celle d'un humain sur plusieurs semaines, un manque de compétences en matière de collaboration à long terme et un jugement inadéquat dans les situations complexes ou ambiguës.


