
Le 27 janvier, DeepSeek a publié OCR 2 en tant que modèle open source. Après avoir analysé leurs rapport techniqueJe pense que cela représente un changement systémique dans la façon dont l'IA appréhende les données visuelles. Au lieu de simplement augmenter le nombre de paramètres, DeepSeek s'est concentré sur des modifications architecturales fondamentales afin d'améliorer les performances au-delà des limites des modèles vision-langage (VLM) traditionnels.
DeepSeek OCR 2 est bien plus qu'un simple logiciel de reconnaissance de texte.
DeepSeek OCR 2 est un modèle vision-langage de nouvelle génération doté de 3 milliards de paramètres. Il se distingue nettement des outils traditionnels comme Tesseract ou des modèles visuels de base. OCR 2 privilégie deux objectifs spécifiques :
- Ordre de lecture correct : Il assure le maintien de la séquence appropriée pour les textes à plusieurs colonnes, les notes de bas de page et la relation entre les titres et le corps du texte.
- Structure de mise en page stable : Il garantit que les tableaux, les listes et les contenus mixtes sont formatés en structures utilisables.
Si vous devez traiter des numérisations PDF pour la saisie dans une base de données, nettoyer des données pour des systèmes RAG ou analyser des rapports financiers complexes, OCR 2 offre un haut niveau de précision et de reconstruction logique.
Innovation architecturale : pourquoi DeepSeek OCR 2 est-il si efficace ?
Remplacer CLIP par un modèle de langage
La plupart des anciens modèles visuels utilisent CLIP comme composant de traitement d'images. CLIP a été conçu pour associer des images à des étiquettes textuelles. Cependant, il ne permet pas de comprendre la relation logique entre les différentes parties d'un document dense.
La Recherche Profonde Solution: Ils ont utilisé Qwen2-0,5B (une architecture basée sur LLM) comme cœur de l'encodeur de vision.
L'avantage : L'encodeur étant basé sur un modèle de langage, les jetons visuels possèdent une capacité de raisonnement rudimentaire dès la phase initiale. Le modèle peut identifier les pixels appartenant à un en-tête et ceux appartenant à une bordure de tableau, ce qui permet un traitement des données plus précis.
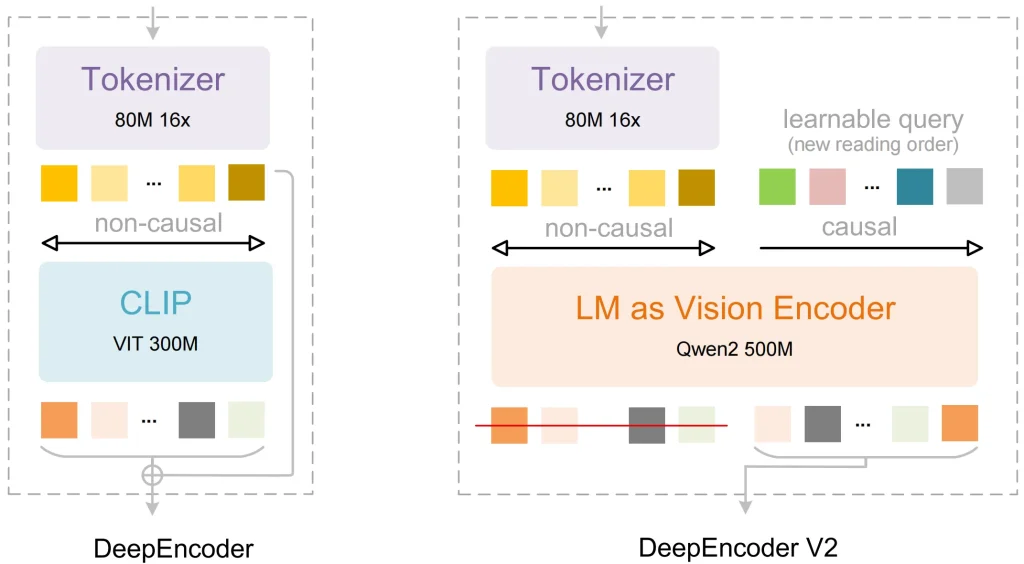
DeepEncoder V2 et flux causal visuel
Il s'agit de l'avancée technique la plus significative en matière de reconnaissance optique de caractères (OCR) 2. De nombreux modèles traitent les images selon une grille fixe, de haut en bas et de gauche à droite. Cet ordre fixe est souvent source d'erreurs lorsque le modèle rencontre des tableaux complexes ou des pages à plusieurs colonnes.
La Recherche Profonde Solution: Ils ont ajouté Flux causal visuel au composant DeepEncoder V2 :
- Le modèle commence par collecter les informations globales de la page entière.
- Il utilise des requêtes apprenables pour réorganiser les jetons visuels.
- Il envoie cette séquence organisée logiquement au décodeur pour générer du texte.
Cela permet au modèle de recueillir des informations en fonction du sens réel des données. Comme les informations sont organisées selon une structure et une sémantique précises lors de l'encodage, le résultat final est très stable.
| Métrique | Modèles OCR traditionnels | DeepSeek OCR 2 |
| Erreur d'ordre de lecture | Élevé (difficultés avec les colonnes) | Nettement inférieur (distance d'édition réduite à 0,057) |
| Compression de jetons | Faible (milliers de jetons par page) | Très élevé (256 à 1120 jetons par page) |
| Stabilité/Précision | Sujet aux répétitions ou aux erreurs | Précision du 97% (à une compression de 10x) |
Faire évoluer l'encodage visuel vers le raisonnement
Les experts décrivent OCR 2 comme un « encodeur de vision piloté par un modèle de langage ». Cela signifie que l'encodeur se concentre sur les relations spatiales et les informations structurelles plutôt que sur la simple extraction de caractéristiques visuelles de base.
Les résultats:
Lors du test professionnel OmniDocBench v1.5, OCR 2 a obtenu un score de 91,09, soit une amélioration de 3,73 points par rapport à la version précédente. Cette amélioration est principalement due à une meilleure précision dans la lecture de l'ordre des documents et la gestion des mises en page complexes.
Comment utiliser DeepSeek OCR 2 : 3 méthodes de déploiement rapides
DeepSeek a publié les poids du modèle Hugging Face. Vous pouvez utiliser ces trois méthodes pour accéder au modèle à des fins de production ou de recherche :
Méthode 1 : Réglage fin rapide via Dépasser la paresse(Recommandé)
Unsloth est optimisé pour OCR 2 et réduit considérablement l'utilisation de la mémoire.
from unsloth import FastVisionModel import torch # Charger le modèle model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # Utiliser la quantification 4 bits pour économiser de la mémoire ) # Modèle d'invite prompt = " Veuillez convertir ce document en Markdown et extraire tous les tableaux.Méthode 2 : Inférence haute performance avec vLLM
C'est le meilleur choix pour les organisations qui doivent traiter de nombreuses demandes simultanément.
- Paramètres: DeepSeek recommande de paramétrer
températureà 0,0 pour des résultats plus cohérents. - Prise en charge linguistique : Vous pouvez spécifier la langue cible dans l'invite de commande. Plus de 100 langues sont prises en charge.
Méthode 3 : Transformateurs de visage à câlins standard
Pour une flexibilité maximale, utilisez la bibliothèque standard :
- Installez les prérequis :
pip install transformers einops addict easydict. - Charger le modèle :
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", trust_remote_code=True).
Conseil: Lors du traitement de numérisations inclinées, une rotation de l'image de seulement 0,5 degré pour la redresser peut aider le modèle à produire des résultats encore meilleurs.
D'après mon observation à long terme du secteur de l'IA, DeepSeek a toujours fait figure de pionnier dans l'optimisation des algorithmes fondamentaux. J'ai notamment constaté que leur premier modèle OCR En octobre 2025, la compression des jetons était déjà utilisée pour améliorer l'efficacité.
OCR 2 ne se limite pas à une simple mise à jour des performances. Il représente un changement fondamental dans la manière dont l'IA traite la logique visuelle. Grâce à l'utilisation d'une architecture de modèle de langage pour l'encodage visuel, DeepSeek a permis à l'IA d'approfondir sa compréhension des données complexes. Ces efforts témoignent, à mon sens, d'une vision novatrice. Cette méthode d'organisation de l'information à un niveau fondamental permet à l'IA de lire d'une manière plus proche de la logique humaine et établit une nouvelle norme pour l'extraction précise des données.


