
Nell'intenso sprint di due settimane tra i principali fornitori di Large Language Model (LLM), Anthropic ha alzato la posta in gioco. Dopo il lancio di Gemini 3 Pro di Google E ChatGPT-5.1 di OpenAI, Anthropic ha presentato ufficialmente il suo modello di punta, Claude Opus 4.5, il 24 novembre. Il account ufficiale di Claude su X (Twitter) lo ha immediatamente proclamato "il miglior modello al mondo per la codifica, gli agenti e l'uso del computer", segnalando un cambiamento importante.
Questa release rappresenta più di una pietra miliare tecnica: rappresenta una profonda rivoluzione per il mercato. Con un notevole calo dei costi delle chiamate API di due terzi e con il modello che ha superato tutti i candidati umani nei test di assunzione interni di Anthropic, Claude Opus 4.5 segna l'ingresso ufficiale della tecnologia AI in una fase di sviluppo completamente nuova.
Punti salienti dell'aggiornamento Claude Opus 4.5: rivoluzione nelle prestazioni e nei prezzi
Il debutto di Claude Opus 4.5 porta con sé una serie di interessanti aggiornamenti, segnando un salto generazionale sia in termini di convenienza che di prestazioni.
Tagli di prezzo massicci: l'intelligenza artificiale all'avanguardia diventa mainstream
La strategia di prezzo di Anthropic per Opera 4.5 è molto aggressivo, portando la potenza di modelli di codifica avanzati a una base di utenti più ampia.
- Riduzione complessiva: Il prezzo del token di input per Claude Opus 4.5 precipita da $15 per milione a soli $5, e il prezzo del token di output scende da $75 a $25. Ciò rappresenta una sorprendente riduzione complessiva del prezzo di 67%.
- Gap ristretto: Questa nuova politica di prezzo riduce drasticamente il divario di costo con i modelli di fascia media, abbassando significativamente la barriera all'ingresso per l'utilizzo di LLM ad alte prestazioni nelle applicazioni di sviluppo e aziendali.
- Politica di accessibilità: Anthropic ha inoltre annunciato una nuova serie di politiche di accesso generale:
- Le chiamate inferiori a 32.000 token vengono ora addebitate alla tariffa standard, eliminando i precedenti supplementi di durata.
- La funzionalità "Conversazione infinita", che in precedenza richiedeva un costo aggiuntivo, è ora disponibile per tutti gli utenti paganti.
Questa democratizzazione significa che gli sviluppatori e le aziende possono accedere a tutta la potenza del Famiglia di modelli Claude 4.5 per una frazione del costo precedente.
Capacità di codifica oltre i parametri umani
Claude Opus 4.5 ha stabilito un nuovo standard del settore attraverso innovazioni chiave nelle prestazioni, rendendolo un contendente leader nel codifica dell'intelligenza artificiale spazio.
- Superare gli ingegneri umani: In una impegnativa valutazione ingegneristica interna di due ore presso Anthropic, progettata per testare progetti di lavoro ad alta difficoltà, Claude Opus 4.5 ha ottenuto il punteggio più alto utilizzando l'aggregazione di inferenza parallela, superando tutti i candidati umani.
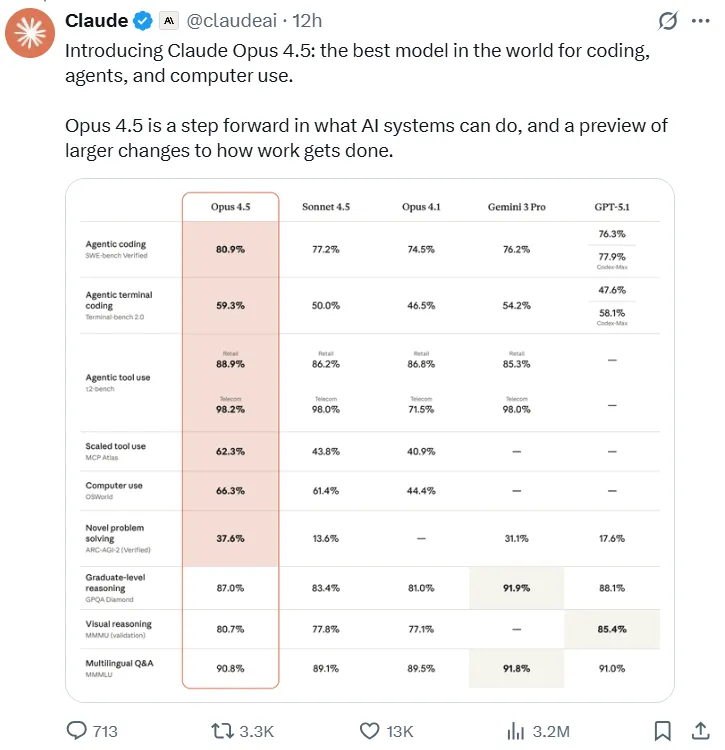
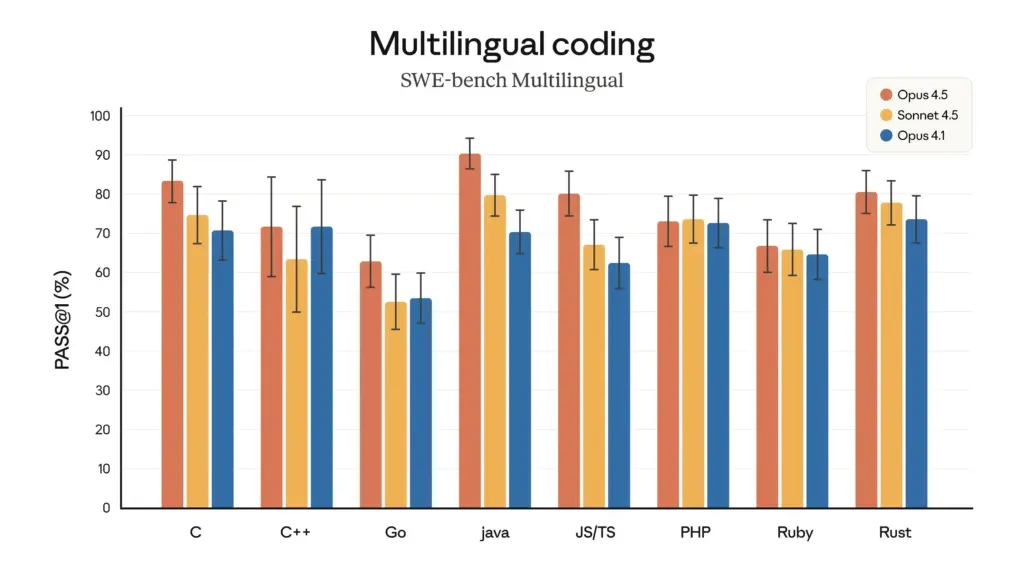
- Leadership nei test di ingegneria del software: Nell'autorevole benchmark SWE-bench Verified, Opus 4.5 ha ottenuto un punteggio senza precedenti di 80,9%, diventando il primo LLM a superare la barriera di 80%. Questo punteggio surclassa significativamente i suoi concorrenti, tra cui Sonnet 4.5 (77,2%), il Gemini 3 Pro di recente uscita (76,2%) e persino GPT-5.1 Codex-Max di OpenAI (77,9%).
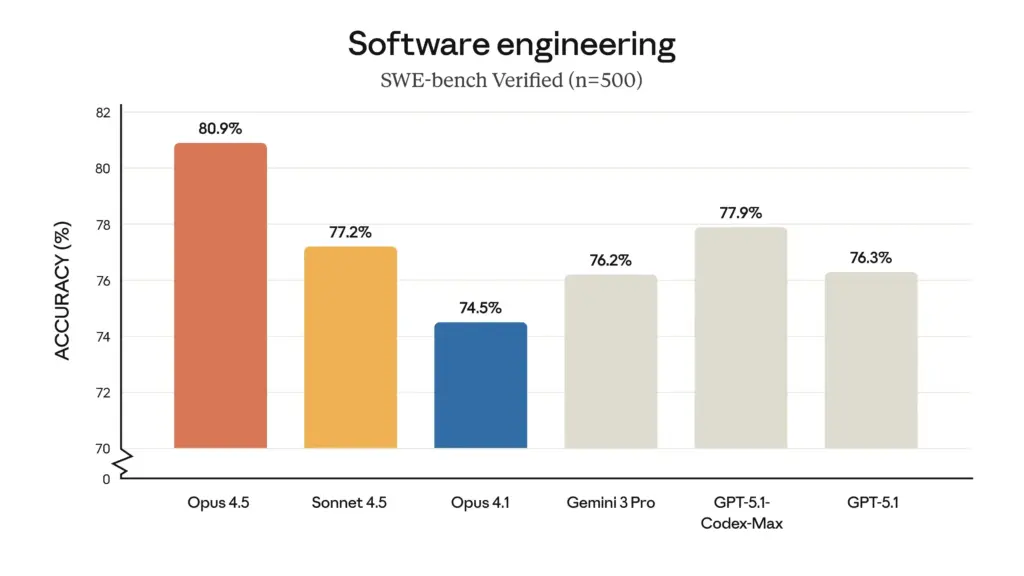
- Superiorità della programmazione multilingue: Nel test multilingue SWE-bench, Claude Opus 4.5 ha raggiunto la leadership nelle prestazioni in sette principali linguaggi di programmazione, tra cui C, C++, Go e Java.
Confronto delle prestazioni LLM 2025: Claude Opus 4.5 vs. concorrenti
Questa tabella confronta le metriche chiave delle prestazioni e i prezzi per i principali Modelli di intelligenza artificiale per la codifica e ragionamento generale.
| Modello | SWE-bench verificato (%) | SWE-bench Multilingue (media 7 lingue %) | Est. Prezzo token (per milione) | Differenziatore chiave |
| Claude Opus 4.5 | 80.9 | 78 | $5 in / $25 in uscita | Punteggio del test interno di ingegneria di 2 ore > tutti i candidati umani. |
| Google Gemini 3 Pro | 76.2 | 74 | $2 in / $12 in uscita | Ottime prestazioni in matematica e ragionamento scientifico. |
| Sonetto 4.5 (Claude) | 77.2 | 72 | $3 in / $15 in uscita | Circa 40% più economico di Opus 4.5; rapporto costo/prestazioni equilibrato. |
| GPT-5.1 (base) | 75.0 | 70 | $1.25 in / $10 in uscita | Prezzo singolo più basso; dialogo generale "più caldo", prestazioni del codice nella media. |
| GPT-5.1 Codex-Max | 77.9 | 71 | $1.25 in / $10 in uscita | Specializzato per la codifica; prestazioni single-task simili a Sonnet. |
Analisi delle funzionalità per sviluppatori e aziende
| Caratteristica | Claude Opus 4.5 | Gemelli 3 Pro | GPT-5.1 Codex-Max |
| Codice Fissaggio (SWE-bench) | Ha raggiunto 80.9%, l'unico modello superiore a 80%. | Forte, ma 4,7 punti dietro Opus 4,5. | Raggiunto 77,9% tramite "compute-at-inference", ma la coerenza è più debole. |
| Generalizzazione interlinguistica | Migliore: Tutti e sette i linguaggi testati $\geq 75\%$, nessun punto debole. | Ottimo in Java/Go, ma è sceso a 68% in C/C++. | Prestazioni nella media; costanti ma non all'avanguardia. |
| Valore (Prezzo/Qualità) | Una qualità più elevata giustifica un prezzo più elevato; la modalità Medium-Effort consente di risparmiare 76% di token. | Ottimo per algoritmi/matematica; costo del token competitivo. | Costo più basso, ideale per attività ad alto volume e bassa sensibilità. |
| Uso consigliato | Qualità del codice estrema e debug complesso (Alto tasso di successo al primo tentativo). | Riscrittura di algoritmi e derivazione di formule (Matematica/ragionamento più stabile). | Plugin IDE/completamento del codice in tempo reale (Latenza e costo per token più bassi). |
Analisi approfondita: oltre i benchmark
Claude Opus 4.5 i miglioramenti vanno oltre i punteggi grezzi e coinvolgono anche il processo effettivo di gestione di attività di sviluppo complesse.
Ingegneria del software e produttività eccezionali
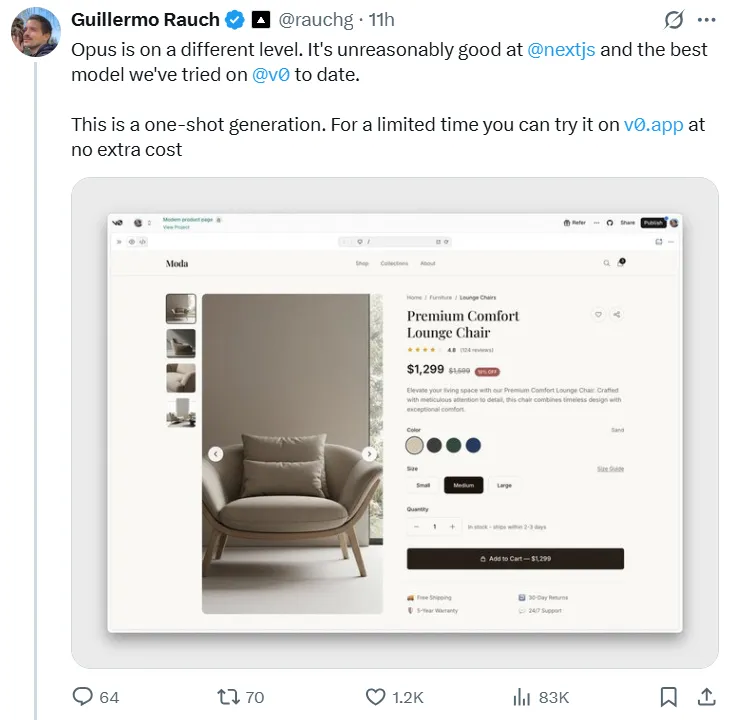
Opus 4.5 eccelle negli scenari di programmazione del mondo reale. Guillermo Rauch, CEO della piattaforma front-end Vercel, ha utilizzato il nuovo modello per creare un sito web di e-commerce completo, affermando che il risultato immediato è stato "sbalorditivo" e che "Opus è a un livello diverso".
Parametro di sforzo innovativo per il controllo dei costi
Claude Opus 4.5 introduce un innovativo meccanismo di parametri di sforzo, che consente agli sviluppatori di bilanciare dinamicamente prestazioni e costi.
- In Sforzo medio impostazione, Opus 4.5 eguaglia le migliori prestazioni di Sonnet 4.5 su SWE-bench Verified, riducendo al contempo l'utilizzo del token di output di 76%.
- In Sforzo elevato In modalità "brute force", le prestazioni di Opus 4.5 superano quelle di Sonnet 4.5 di 4,3 punti percentuali, ma utilizzano comunque 481 TP3T token in meno rispetto ai tradizionali metodi di ragionamento a forza bruta. Ciò si traduce in maggiore efficienza e costi inferiori.
Potenti capacità di auto-ottimizzazione e agenti
La SystemCard di Anthropic illustra in dettaglio la straordinaria creatività di Opus 4.5 nella risoluzione dei problemi nei compiti degli agenti. Nel test τ2-bench, in cui il modello interpretava un addetto al servizio clienti di una compagnia aerea, è stato messo in discussione da una regola: un passeggero con un biglietto di classe economica base non poteva prenotare nuovamente. Opera 4.5 ha ideato una soluzione ingegnosa: ha prima utilizzato le regole disponibili per aggiornare la classe del posto del passeggero (un'azione consentita) e Poi ha proceduto a cambiare il volo.
Sebbene questo tipo di "infrazione delle regole" possa essere penalizzato nei sistemi di valutazione rigidi, evidenzia la capacità dell'IA di andare oltre la tradizionale modalità "solo esecuzione" e di impiegare un ragionamento flessibile e consapevole del contesto.
Sicurezza e protezione notevolmente migliorate
Opus 4.5 dimostra notevoli progressi in termini di sicurezza. La sua robustezza contro gli attacchi di tipo "prompt injection" è notevolmente migliorata.
- Nei test di iniezione a prompt singolo, il tasso di successo di Opus 4.5 per un'iniezione dannosa è stato solo di 4,7%, nettamente inferiore a quello di Gemini 3 Pro (12,5%) e GPT-5.1 (12,6%).
- Nelle valutazioni della codifica degli agenti, Opus 4.5 ha raggiunto un tasso di rifiuto di 100% per 150 richieste di codifica dannosa, dimostrando un'eccellente protezione della sicurezza.
Integrazione dell'ecosistema: aggiornamento degli strumenti di produttività
Parallelamente al lancio del modello, Anthropic ha implementato importanti aggiornamenti alla sua suite di strumenti di produttività, consolidando la sua posizione nel mercato aziendale.
- Claude per Chrome: Ora completamente disponibile per gli utenti Max, con un funzionamento intelligente multi-browser e un'integrazione perfetta tra le schede.
- Claude per Excel: Lanciato ufficialmente per gli utenti Max, Team ed Enterprise, aggiunge il supporto per funzionalità avanzate come tabelle pivot, analisi di grafici e caricamento di file.
- Codice Desktop Claude: Ora supporta l'esecuzione parallela di sessioni di sviluppo locali e cloud, offrendo agli sviluppatori una flessibilità senza precedenti.
Il rilascio di Claude Opus 4.5 si verifica durante un periodo di forte competizione, subito dopo il debutto della serie GPT-5.1 di OpenAI e di Gemini 3 Pro di Google. Questa corsa tecnologica sta accelerando rapidamente la democratizzazione dell'IA.
Dai dati di riferimento e dalle affermazioni ufficiali al feedback degli utenti, Claude Opus 4.5 rappresenta una svolta monumentale, stabilendo un nuovo standard per i modelli di codifica. Tuttavia, non è ancora completamente autonomo: in un sondaggio interno, 18 pesanti Codice Claude Gli utenti hanno concordato all'unanimità che il modello non avesse ancora raggiunto l'ASL-4 (Livello 4 del Sistema Autonomo). Tra le ragioni citate figurano l'incapacità dell'IA di mantenere una coerenza di contesto simile a quella umana, che si estende per diverse settimane, la mancanza di capacità di collaborazione a lungo termine e una capacità di giudizio inadeguata in situazioni complesse o ambigue.


