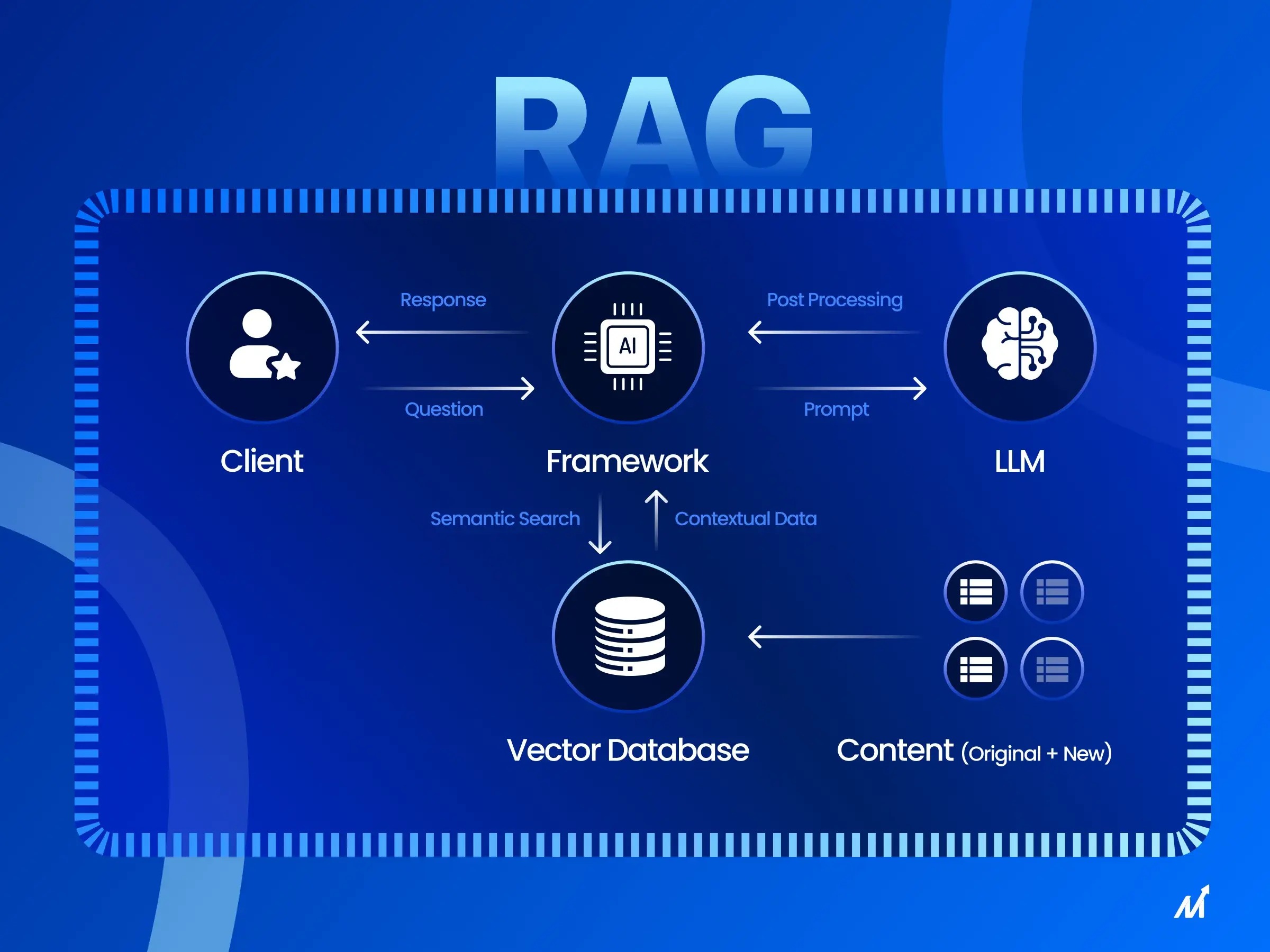
Con l'avanzare dell'evoluzione dei sistemi di risposta alle domande, gli sviluppatori stanno esplorando nuove tecniche per migliorarne le prestazioni. Un approccio promettente è il modello RAG (Retrieval-Augmented Generation), che combina il recupero delle informazioni con le capacità del linguaggio generativo. Ottimizzando l'incorporamento utilizzato per il recupero di dati specifici di un dominio, i ricercatori hanno trovato un modo per migliorare significativamente l'accuratezza delle risposte dei modelli RAG. Questo articolo approfondisce questa tecnica.
Introduzione a RAG
Per comprendere meglio perché l'ottimizzazione degli embedding è così efficace per i modelli RAG, dobbiamo prima fornire alcune informazioni di base su RAG stesso.
Che cosa è RAG?
RAG sta per Retrieval-Augmented Generation (Generazione Aumentata di Recupero). Si tratta di un metodo che combina il recupero delle informazioni con modelli generativi. Un modello RAG recupera prima le informazioni rilevanti, quindi genera una risposta basata su tali informazioni. Questo aumenta la capacità del modello di rispondere a domande complesse. Si compone di due parti: un recuperatore e un generatore. Il recuperatore estrae frammenti rilevanti da un ampio corpus di documenti in base alla domanda. Il generatore utilizza quindi tali frammenti per generare una risposta coerente. Questo approccio funziona meglio per le risposte a domande di dominio aperto perché può recuperare dinamicamente le informazioni più recenti.
Pro e limiti dei modelli RAG
Rispetto ai tradizionali modelli di recupero del testo e ai modelli generativi, i modelli RAG presentano alcuni vantaggi:
- Può fornire risultati di ricerca più accurati e utili
- Può gestire query complesse e testi lunghi
- Può generare risultati di ricerca personalizzati in base all'intento dell'utente
Tuttavia, i modelli RAG presentano anche alcune limitazioni:
- L'addestramento e l'inferenza sono computazionalmente costosi
- Elevati requisiti per i dati di addestramento e la capacità del modello
- Difficoltà nella gestione di query e testi provenienti da domini specializzati
Il ruolo degli incorporamenti in RAG
Dopo aver esaminato le basi di RAG, approfondiamo il ruolo cruciale degli embedding e il modo in cui possono essere ottimizzati.

Confronto di richiamo di diversi modelli di incorporamento sui dati di dominio
Questo esperimento ha utilizzato oltre 30.000 frammenti di conoscenza e 600 domande utente standard per i test di richiamo. Abbiamo confrontato principalmente le prestazioni di richiamo dei modelli m3e-base, bge-base-zh e bce-embedding-base_v1 su dati di input in cinese e inglese.
Ottimizzazione del modello di incorporamento sui dati di dominio
- Raccolta dati: raccogliere dati sufficienti relativi al dominio, tra cui documenti, coppie di domande e risposte, ecc. Questi dati dovrebbero riguardare i punti di conoscenza chiave e le domande comuni nel dominio.
- Pre-elaborazione: pulire e pre-elaborare i dati per rimuovere rumore e ridondanza, garantendo la qualità dei dati.
- Fine-tuning: perfeziona un modello embedded pre-addestrato (ad esempio, BERT) sui dati di dominio. L'addestramento continuo sui dati di dominio aiuta il modello ad adattarsi meglio alla semantica e all'utilizzo del linguaggio in quel dominio.
- Valutazione e ottimizzazione: valutare le prestazioni del modello di incorporamento ottimizzato in RAG e adattare i parametri di addestramento e i set di dati secondo necessità per ottimizzare ulteriormente le prestazioni.
Grazie alla messa a punto, il modello di Embedding è in grado di comprendere meglio la semantica specifica del dominio, migliorando così le capacità di recupero e generazione del modello RAG e incrementando i tassi e la qualità delle risposte.
Prendendo come esempio il modello m3e:
Scarica: https://huggingface.co/moka-ai/m3e-base
Riferimento per la messa a punto: https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
Dopo aver perfezionato i dati di dominio e aver nuovamente testato il richiamo, abbiamo riscontrato un aumento diretto del 33% nel tasso di richiamo: un risultato molto promettente.
Conclusione
L'ottimizzazione del modello di Embedding è un modo efficace per migliorare i tassi di risposta dei RAG. Ottimizzando i dati di dominio, il modello di Embedding può comprendere meglio la semantica specifica del dominio, migliorando così le prestazioni complessive del modello RAG. Sebbene i modelli RAG offrano vantaggi significativi nel QA open-domain, le loro prestazioni in domini specifici necessitano ancora di ulteriore ottimizzazione. La ricerca futura potrebbe esplorare ulteriori metodi di ottimizzazione e miglioramenti della qualità dei dati per migliorare ulteriormente l'accuratezza delle risposte e l'usabilità dei modelli RAG in tutti i domini.


