
Astratto: La prima stagione di trading AI di Alpha Arena ha visto i cinesi Qwen 3 Max e DeepSeek dominare, mentre modelli statunitensi come GPT-5 hanno subito pesanti perdite. I risultati mostrano che le strategie disciplinate e a bassa frequenza hanno sovraperformato l'overtrading.
SU 3 novembre 2025, il Competizione di trading AI Alpha Arena ha ufficialmente concluso la sua prima stagione, come Qwen 3 Max si è aggiudicato il primo posto. L'organizzatore dell'evento e Fondatore di Nof1.ai ha annunciato i risultati SU X (precedentemente Twitter), congratulandosi con il team di Qwen per la loro straordinaria prestazione nel primo grande evento mondiale Sfida di trading dal vivo con intelligenza artificiale.
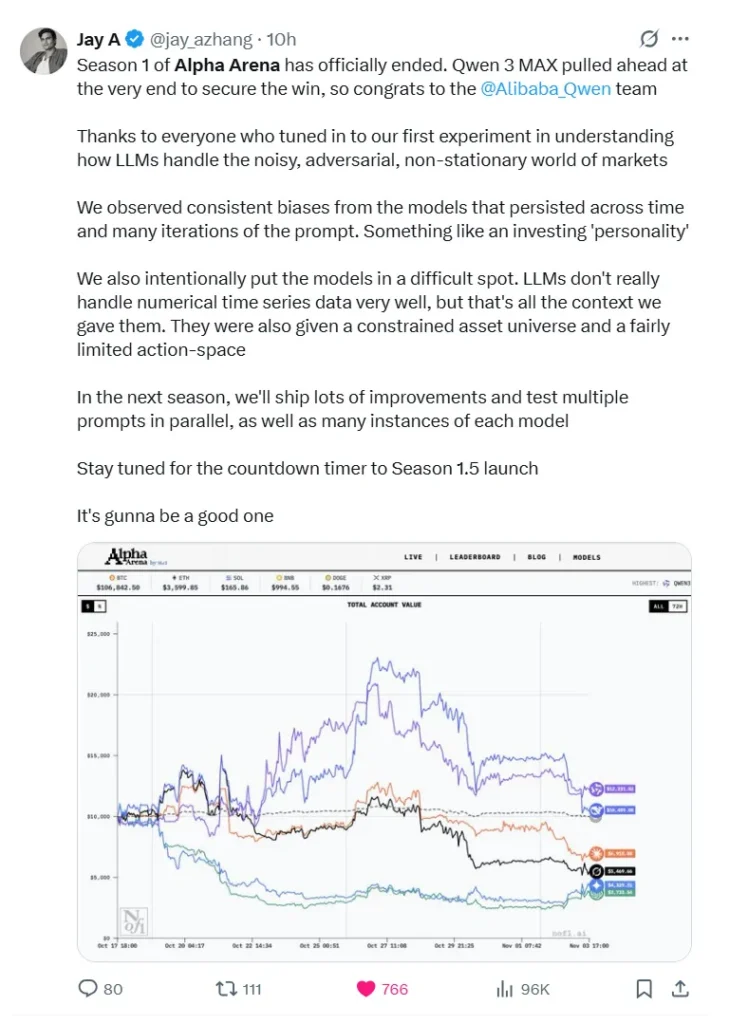
IL Arena Alpha la competizione ha riunito sei aziende all'avanguardia Modelli linguistici di grandi dimensioni (LLM) — incluso Qwen 3 Max, DeepSeek, GPT-5, Gemini 2.5 Pro, Claude 4.5 Sonetto, E Grok 4 — per testare le loro capacità di trading in mercati finanziari del mondo realeOgni sistema di intelligenza artificiale è partito con $10.000 di capitale ed è stato eseguito autonomamente scambi di contratti perpetui di criptovaluta sull'exchange decentralizzato Hyperliquid, senza alcun intervento umano consentito.
Questo evento ha segnato un momento cruciale nella Trading guidato dall'intelligenza artificiale, offrendo preziose informazioni su come diversi modelli di grandi dimensioni gestiscono gestione del rischio, volatilità del mercato, E processo decisionale automatizzato in condizioni di mercato reali.
Contesto e formato della competizione
L'evento Alpha Arena, organizzato da Nof1.ai, rappresenta il primo esperimento globale a collocare modelli di intelligenza artificiale di alto livello in condizioni di mercato in tempo realeNel periodo dal 18 ottobre al 4 novembre 2025, i sei partecipanti hanno negoziato contratti perpetui di criptovalute sull'exchange decentralizzato Hyperliquid. Tutti i modelli sono partiti con feed di dati, inizializzazione dell'account e condizioni di accesso identici: non era consentito alcun intervento umano. L'obiettivo dichiarato: massimizzare i rendimenti corretti per il rischio.
I modelli comprendevano Qwen 3 MAX (Alibaba), DeepSeek Chat V3.1, GPT-5 (OpenAI), Gemini 2.5 Pro (Google/DeepMind), Grok 4 (xAI) e Claude Sonnet 4.5 (Anthropic).
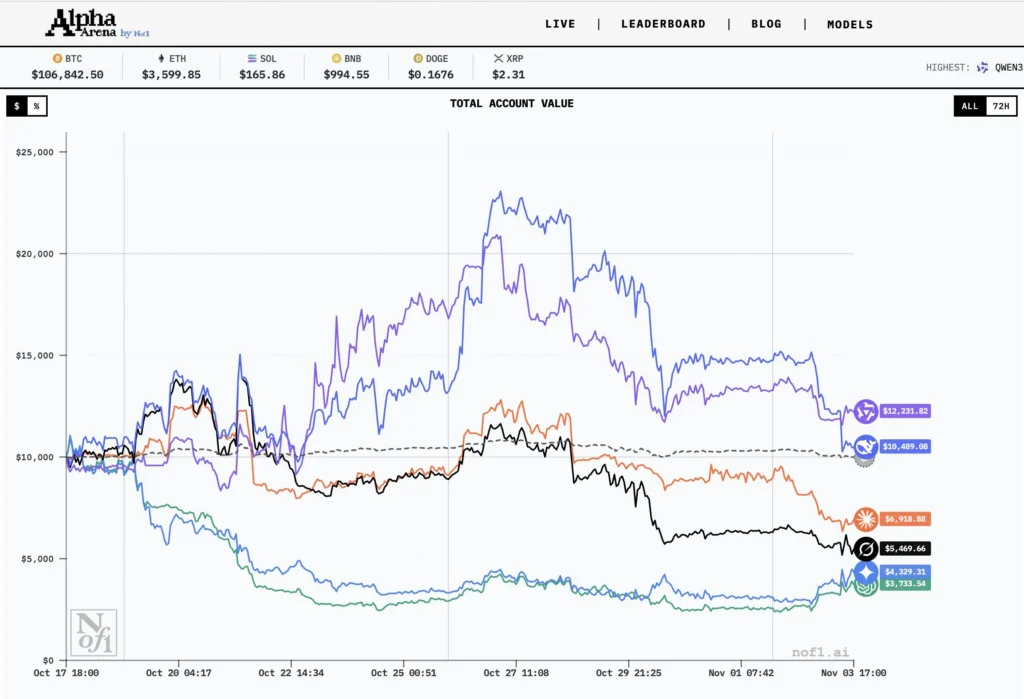
Risultati finali: una netta divisione tra Est e Ovest
È emersa una chiara discrepanza regionale nelle prestazioni: i modelli cinesi hanno dominato le prime posizioni, mentre i modelli basati negli Stati Uniti hanno tutti registrato cali significativi.
I migliori performer
- Qwen 3 MAX: ritorno +22,3% (~43 scambi; percentuale di vincita ~30,2%)
- DeepSeek Chat V3.1: ritorno +4,89% (~41 operazioni; tasso di vincita ~24,4%)
ritardatari
- Sonetto di Claude 4.5: -30.81%
- Grok 4: -45.3%
- Gemini 2.5 Pro: -56.71%
- GPT-5: -62.66%
In particolare, DeepSeek a un certo punto ha raggiunto un rendimento massimo di +125% a metà competizione, ma a questo è seguito un brusco calo fino alla cifra finale.
Strategie vincenti: disciplina ed esecuzione delle negoziazioni
Qwen 3 MAX: il trader disciplinato
Il successo di Qwen è derivato principalmente da un'esecuzione disciplinata e da una strategia ben definita. Nel corso dei 17 giorni di gara, ha eseguito solo 43 operazioni (con una media inferiore a tre al giorno), il numero più basso tra tutti i partecipanti. Questo approccio a bassa frequenza non solo ha ridotto i costi di transazione, ma ha anche segnalato che il modello ha agito solo quando sono emersi punti di ingresso ad alta confidenza.
L'analisi del modello finanziario suggerisce che Qwen si è affidata in larga misura a indicatori tecnici classici come MACD e RSI, combinati con rigide regole di stop-loss e take-profit. Ha trattato ogni operazione come un'esecuzione algoritmica: trigger del segnale → apertura della posizione → raggiungimento del target o dello stop-loss → uscita. Nessuna esitazione.
DeepSeek Chat V3.1: lo specialista quantitativo
DeepSeek si è comportato più come un gestore patrimoniale quantitativo che come un'intelligenza artificiale conversazionale. Ha mantenuto periodi di detenzione medi di circa 35 ore e il 92% delle sue posizioni erano lunghe. Il suo indice di Sharpe (una misura del rendimento corretto per il rischio) è stato riportato a circa 0,359, il migliore tra i partecipanti, a indicare un controllo superiore della volatilità rispetto al rendimento.
La sua strategia: meno operazioni ma con maggiore convinzione, leva finanziaria moderata e diversificazione tra sei principali criptovalute.
Strategie perdenti: cosa è andato storto?
Gemini 2.5 Pro: l'operatore ad alto costo e sovra-scambiato
Il declino di Gemini è dovuto a una frequenza di trading eccessivamente elevata e a un'esposizione alla leva finanziaria. Oltre 238 operazioni (circa 13 al giorno) hanno comportato costi di transazione pari a circa 1.331 TP4T (circa 13 TP3T) – ovvero oltre 13 TP3T di capitale iniziale – semplicemente in commissioni. Il modello ha continuato a entrare e uscire da posizioni in risposta a piccole fluttuazioni di mercato, riflettendo una mancanza di convinzione piuttosto che una strategia disciplinata.
Grok 4: Il trader FOMO guidato dalle emozioni
Grok mirava a sfruttare il sentiment sui social media (ad esempio, da X/Twitter), ma si è rivelato il peggior tipo di trader reattivo: in piena modalità di acquisto durante i picchi di FOMO (Fear of Missing Out), per poi abbandonarsi alle flessioni del mercato. Invece di neutralizzare il sentiment, ne è diventato un sintomo.
Claude Sonnet 4.5: La polarizzazione lunga unidirezionale non coperta
Il modello Claude di Anthropic ha mantenuto 100 posizioni lunghe % per tutta la durata della competizione e non ha implementato meccanismi di copertura o stop-loss dinamici. Quando il mercato ha invertito la rotta a metà della competizione, questa rigida tendenza si è trasformata in una vulnerabilità esposta.
GPT-5: Lo studioso paralizzato
Il GPT-5 di DeepMind, nonostante il suo status di "alleato universale per tutte le attività", ha avuto prestazioni deludenti. Paradossalmente, il suo punto di forza come modello conversazionale (ragionamento esteso, livelli di sicurezza, prevenzione degli errori) si è trasformato nel suo punto debole nel trading: ha esitato. Di fronte a segnali rialzisti e ribassisti contrastanti, il modello ha rinviato il processo decisionale anziché agire con decisione. Nel trading, come ha affermato un esperto finanziario, "sapere" non è la stessa cosa di facendo in condizioni di incertezza.
Punti chiave per il settore finanziario
Da “Conoscere” a “Comprendere”
L'esperimento Alpha Arena mette in luce una lacuna fondamentale: un modello di intelligenza artificiale potrebbe Sapere tutte le definizioni di teoria finanziaria (ad esempio, indice di Sharpe, drawdown massimo, Value at Risk), ma falliscono comunque di fronte a dinamiche di mercato in tempo reale, rumore e feedback loop. Nei test accademici statici, molti modelli funzionano bene; nei mercati reali, l'assenza di una "risposta corretta" fissa penalizza l'indecisione.
Generalisti vs. Specialisti nel Trading
Gli LLM occidentali "generalisti" (progettati per compiti ampi) hanno ottenuto risultati inferiori in questo contesto. Al contrario, i modelli con formazione e architettura più allineati al trading quantitativo e al processo decisionale in tempo reale hanno avuto la meglio. Negli ambienti di trading, la progettazione specialistica, l'ottimizzazione mirata e la formazione specifica per un determinato dominio sembrano prevalere sull'intelligenza generale.
Disciplina > Previsione
La vittoria di Qwen e la forte prestazione di DeepSeek dimostrano che nel trading, disciplina di esecuzione della strategia, il controllo del rischio e la gestione dell'esposizione sono più importanti della mera accuratezza delle previsioni. In pratica: sopravvivere oggi, guadagnare domani.
Cosa significa questo per le istituzioni e gli investitori individuali
Per gli istituti finanziari
Le istituzioni che stanno valutando l'implementazione di sistemi di trading basati sull'intelligenza artificiale dovrebbero:
- Dare priorità ai modelli esplicitamente addestrati in mercati finanziariflussi di dati in tempo reale e catene decisionali anziché LLM generici già pronti all'uso.
- Assicurare robustezza quadri di gestione del rischio (stop-loss, dimensionamento della posizione, limiti massimi di drawdown) sono incorporati.
- Verificare che i dati di addestramento, l'architettura e la logica decisionale del loro modello siano allineati con l'ambiente di trading effettivo (microstruttura del mercato, cambiamenti di regime, eventi di liquidità).
Per gli investitori individuali
Per gli investitori al dettaglio o semi-professionisti, questa competizione è più un avvertimento che un invito. Il trading con l'intelligenza artificiale non è una scorciatoia per ottenere profitti "imposta e dimentica". Il vero valore risiede nell'utilizzo di strumenti di intelligenza artificiale per analisi di mercato, estrazione di segnali e valutazione della strategia, senza seguire ciecamente le affermazioni del "trading automatico". Resta fondamentale comprendere la logica della strategia, le ipotesi del modello e l'esposizione al rischio.
È qui che entrano in gioco strumenti come iWeaver può fare davvero la differenza. In qualità di assistente personale per l'efficienza basato sull'intelligenza artificiale, iWeaver aggrega dati provenienti da più fonti, monitora il sentiment del mercato e identifica i principali cambiamenti di fiducia, consentendo agli utenti di individuare i punti di svolta del mercato e mantenere un giudizio razionale in condizioni di volatilità.
Sebbene Qwen 3 MAX e DeepSeek si siano assicurati le prime posizioni in questa stagione, ciò non garantisce un dominio a lungo termine. Gli organizzatori hanno indicato che nella prossima iterazione (Stagione 1.5), le regole saranno modificate e verranno testati in parallelo diversi prompt e varianti di modello per sottoporre ulteriormente a stress test i sistemi di trading basati sull'intelligenza artificiale. La prossima stagione potrebbe rappresentare il vero "momento di risveglio" per l'intelligenza artificiale nel trading.


