
Il 27 gennaio, DeepSeek ha rilasciato OCR 2 come modello open source. Dopo aver analizzato il loro rapporto tecnicoCredo che questo rappresenti un cambiamento sistematico nel modo in cui l'IA interpreta i dati visivi. Invece di limitarsi ad aumentare il numero di parametri, DeepSeek si è concentrato su cambiamenti architetturali fondamentali per migliorare le prestazioni oltre i limiti dei tradizionali modelli di linguaggio visivo (VLM).
DeepSeek OCR 2 è più di un semplice riconoscimento del testo
DeepSeek OCR 2 è un modello di linguaggio visivo di nuova generazione con 3 miliardi di parametri. Si differenzia significativamente dagli strumenti tradizionali come Tesseract o dai modelli visivi di base. OCR 2 si pone due obiettivi specifici:
- Ordine di lettura corretto: Mantiene la sequenza corretta per il testo multicolonna, le note a piè di pagina e la relazione tra intestazioni e corpo del testo.
- Struttura di layout stabile: Garantisce che tabelle, elenchi e contenuti misti siano formattati in strutture utilizzabili.
Se è necessario elaborare scansioni PDF per l'inserimento in database, pulire dati per sistemi RAG o analizzare report finanziari complessi, OCR 2 garantisce un elevato livello di accuratezza e ricostruzione logica.
Innovazione architettonica: perché DeepSeek OCR 2 è così efficiente?
Sostituzione di CLIP con un modello linguistico
La maggior parte dei modelli visivi più datati utilizza CLIP come componente di elaborazione delle immagini. CLIP è stato progettato per abbinare le immagini alle etichette di testo. Tuttavia, non è in grado di comprendere la relazione logica tra le diverse parti di un documento complesso.
Il DeepSeek Soluzione: Hanno usato Qwen2-0.5B (un'architettura basata su LLM) come nucleo del codificatore di visione.
Il vantaggio: Poiché il codificatore si basa su un modello linguistico, i token visivi hanno una capacità di ragionamento di base durante la fase iniziale. Il modello può identificare quali pixel appartengono a un'intestazione e quali appartengono a un limite di tabella, il che consente un'elaborazione dei dati più accurata.
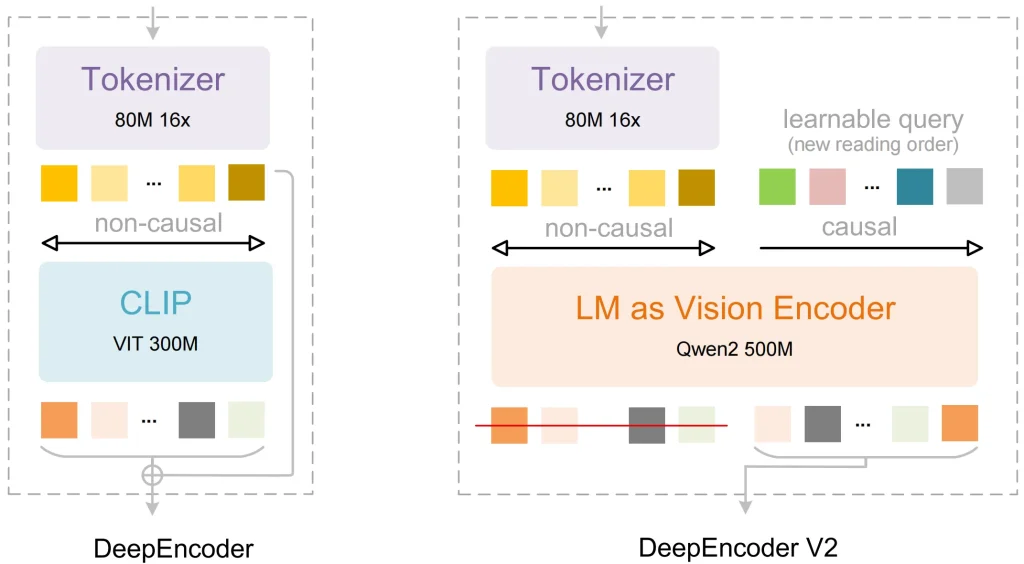
DeepEncoder V2 e flusso causale visivo
Questa è la svolta tecnica più significativa di OCR 2. Molti modelli elaborano le immagini in una griglia fissa, dall'alto a sinistra al basso a destra. Questo ordine fisso causa spesso errori quando il modello incontra tabelle complesse o pagine multicolonna.
Il DeepSeek Soluzione: Hanno aggiunto Flusso causale visivo al componente DeepEncoder V2:
- Il modello raccoglie innanzitutto le informazioni globali dell'intera pagina.
- Utilizza query apprendibili per riordinare i token visivi.
- Invia questa sequenza organizzata logicamente al decoder per generare il testo.
Ciò consente al modello di raccogliere informazioni in base al significato effettivo dei dati. Poiché le informazioni vengono organizzate in base al layout e alla semantica durante la fase di codifica, l'output finale è molto stabile.
| Metrico | Modelli OCR tradizionali | DeepSeek OCR 2 |
| Errore nell'ordine di lettura | Alto (ha difficoltà con le colonne) | Significativamente inferiore (la distanza di modifica è scesa a 0,057) |
| Compressione token | Basso (migliaia di token per pagina) | Molto alto (256 – 1120 token per pagina) |
| Stabilità/Precisione | Tendente a ripetizioni o errori | Precisione 97% (a compressione 10x) |
Spostare la codifica visiva verso il ragionamento
Gli esperti descrivono OCR 2 come un "codificatore visivo basato su modelli linguistici". Ciò significa che il codificatore si concentra sulle relazioni spaziali e sulle informazioni strutturali anziché limitarsi a estrarre le caratteristiche visive di base.
I risultati:
Nel test professionale OmniDocBench v1.5, OCR 2 ha ottenuto un punteggio di 91,09. Si tratta di un miglioramento di 3,73 punti rispetto alla versione precedente. La maggior parte dei progressi si è verificata nell'accuratezza degli ordini di lettura e nella gestione di layout complessi.
Come utilizzare DeepSeek OCR 2: 3 metodi di distribuzione rapida
DeepSeek ha rilasciato i pesi del modello su Hugging Face. È possibile utilizzare questi tre metodi per accedere al modello per la produzione o la ricerca:
Metodo 1: FastFine-Tuning tramite Non-indolenza(Raccomandato)
Unsloth è ottimizzato per OCR 2 e riduce significativamente l'utilizzo della memoria.
da unsloth import FastVisionModel import torch # Carica il modello model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # Usa la quantizzazione a 4 bit per risparmiare memoria) # Prompt template prompt = " \n<|grounding|>Converti questo documento in Markdown ed estrai tutte le tabelle."Metodo 2: inferenza ad alte prestazioni con vLLM
Questa è la scelta migliore per le organizzazioni che devono gestire molte richieste contemporaneamente.
- Impostazioni: DeepSeek consiglia di impostare il
temperaturaa 0,0 per risultati più coerenti. - Supporto linguistico: È possibile specificare la lingua di destinazione nel prompt. Sono supportate oltre 100 lingue.
Metodo 3: Trasformatori standard per il viso abbracciato
Per la massima flessibilità, utilizzare la libreria standard:
- Installa i requisiti:
pip install transformers einops addict easydict. - Carica il modello:
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", trust_remote_code=True).
Mancia: Quando si elaborano scansioni inclinate, ruotare l'immagine di soli 0,5 gradi per raddrizzarla può aiutare il modello a produrre risultati ancora migliori.
Dalla mia osservazione a lungo termine del settore dell'intelligenza artificiale, DeepSeek ha costantemente agito come pioniere nell'ottimizzazione degli algoritmi di base. Ho notato che il loro primo modello OCR nell'ottobre 2025 ha già utilizzato la compressione dei token per migliorare l'efficienza.
OCR 2 non è solo un aggiornamento delle prestazioni. Rappresenta un cambiamento fondamentale nel modo in cui l'intelligenza artificiale elabora la logica visiva. Utilizzando un'architettura basata su un modello linguistico per la codifica visiva, DeepSeek ha aumentato la profondità con cui l'intelligenza artificiale comprende dati complessi. Credo che questi sforzi dimostrino un alto livello di lungimiranza. Questo metodo di organizzazione delle informazioni a livello fondamentale consente all'intelligenza artificiale di leggere in un modo più simile alla logica umana e fornisce un nuovo standard per l'estrazione accurata dei dati in futuro.


