
Nelle mie recenti valutazioni dei modelli, una domanda continua a presentarsi: Un agente di codifica può essere veloce, affidabile e conveniente quando le attività comportano modifiche di più file, debug ripetuti e utilizzo di strumenti, non solo risposte a un solo turno? MiniMax M2.5 è una delle poche versioni che viene fornita con abbastanza efficienza end-to-end e dettagli sui prezzi per testare concretamente questa domanda.
Perché presto attenzione a M2.5
Mi concentro meno sul "miglior punteggio di riferimento" e più sulla capacità di un modello di completare flussi di lavoro reali:
- Consegna end-to-end: ambito → implementazione → convalida → risultati
- Efficienza operativa: iterazioni di chiamata dello strumento, utilizzo del token e stabilità in fase di esecuzione
- Agente economia: se il modello di prezzo supporta agenti di lunga durata e iterazioni ripetute
MiniMax M2.5 è interessante perché mira a ottimizzare capacità, efficienza e costo nella stessa versione: una combinazione importante per i team di ingegneria che prendono decisioni di distribuzione.
Per cosa è stato progettato M2.5
Sulla base del materiali ufficiali, MiniMax M2.5 è posizionato per carichi di lavoro di produttività del mondo reale su tre percorsi principali:
- Per l'ingegneria del software (codifica agentica): rappresentato da SWE-Bench Verified, Multi-SWE-Bench e un'enfasi sulla stabilità delle prestazioni su diverse imbracature.
- Per la ricerca interattiva e l'uso degli strumenti: tra cui BrowseComp, Wide Search e il benchmark interno RISE di MiniMax, progettato per riflettere un'esplorazione più approfondita all'interno di fonti web professionali.
- Per la produttività in ufficio: focalizzato su attività orientate ai risultati in Word, PowerPoint ed Excel, supportato da un framework di valutazione (GDPval-MM) che considera la qualità dell'output, le tracce di esecuzione dell'agente e il costo del token.
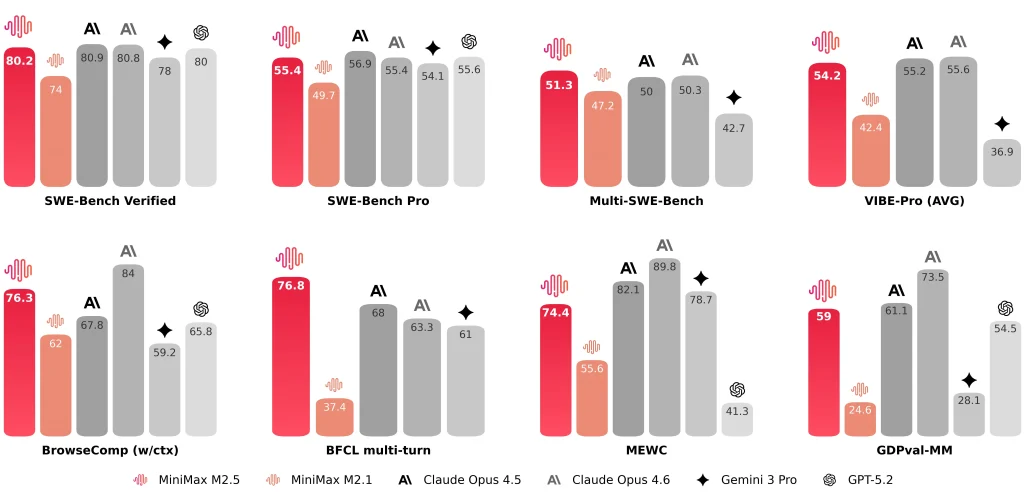
MiniMax divulga anche risultati rappresentativi come SWE-Bench verificato 80.2%, Banco multi-SWE 51.3%, E BrowseComp 76.3%.
MiniMax M2.5 vs M2.1 e Claude Opus 4.6: cosa confronto
M2.5 vs M2.1 vs Claude Opus 4.6 (Tabella delle metriche chiave)
| Dimensione | M2.5 | M2.1 | Claude Opus 4.6 |
| SWE-Bench verificato | 80.20% | 74.0% | 81.42% (Antropico segnalato) ~78-80% (media pubblica) |
| Tempo medio end-to-end per attività SWE | 22,8 minuti | 31,3 minuti | 22,9 minuti |
| Token per attività SWE (media) | 3,52 milioni | 3,72 milioni | — (Probabilmente >4M a causa della verbosità) |
| Iterazioni di ricerca/strumento rispetto alla generazione precedente | ~20% iterazioni in meno (segnalate) | Linea di base | — |
| SWE-Bench con imbracatura incrociata (Droid) | 79.7 | 71.3 | 78.9 |
| SWE-Bench con cablaggio incrociato (OpenCode) | 76.1 | 72.0 | 75.9 |
| Opzioni di produttività | ~50 token/s (standard) ~100 token/s (Fulmine) | ~57 token/s | ~67-77 token/s |
| Prezzi (per 1 milione di token di input) | $0.3 (standard e Lightning) | $0.3 | $5.0 |
| Prezzi (per 1 milione di token in uscita) | $1.2 (standard) $2.4 (Fulmine) | $1.2 | $25.0 |
| Intuizione oraria (output continuo) | ~$0,3/ora a 50 t/s ~$1/ora a 100 t/s | ~$0,3/ora a 57 t/s | ~$6,50/ora a 70 t/s |
Note:
- “—” significa che il valore non è stato fornito nei materiali riassunti qui.
- I benchmark possono variare in base all'imbracatura, alla configurazione degli strumenti, ai prompt e alle convenzioni di reporting, quindi li tratto come indicatori di portata, non classifiche assolute.
M2.5 vs M2.1: End-to-End più veloce, utilizzo di token inferiore, meno iterazioni di ricerca
Il confronto ufficiale è presentato in modo semplice e intuitivo. Faccio attenzione a tre parametri specifici:
- Tempo di esecuzione end-to-end: il tempo medio di un'attività SWE scende da 31,3 minuti (M2.1) A 22,8 minuti (M2,5), descritto come un Miglioramento 37%.
- Token per attività: l'utilizzo del token per attività diminuisce da 3,72 milioni A 3,52 milioni.
- Efficienza di iterazione della ricerca/strumento: su BrowseComp, Wide Search e RISE, MiniMax segnala risultati migliori con meno iterazioni, con un costo di iterazione approssimativamente 20% inferiore rispetto a M2.1.
Per me, questi miglioramenti sono più importanti di un singolo punteggio di riferimento perché determinano direttamente capacità di elaborazione dell'agente E costi operativi sostenibili.
M2.5 vs Claude Opus 4.6: intervallo di codifica simile, il contesto di valutazione è importante
Quando si confronta M2.5 con Claude Opus 4.6, Tratto i punteggi come intervalli piuttosto che classifiche assolute, perché le imbracature, le configurazioni degli strumenti, i prompt e le convenzioni di reporting possono variare.
- Antropico osserva che Verificato dal banco SWE dell'Opus 4.6 il risultato è una media su 25 provee menziona un valore osservato più elevato (81.42%) con aggiustamenti rapidi.
- Rapporti MiniMax SWE-Bench verificato 80.2% per MiniMax M2.5.
Numericamente, i due sembrano collocarsi in una fascia competitiva simile per i benchmark degli agenti di codifica. Da un punto di vista ingegneristico, mi interessa di più la stabilità nelle diverse forme di progetto reali (front-end + back-end, diversi scaffold e integrazioni di terze parti) che un singolo valore di riferimento.
Come M2.5 cambia il mio flusso di lavoro (appunti pratici)
Velocità e stile del flusso di lavoro
Dopo l'integrazione MiniMax M2.5 in una toolchain di agenti di codifica, due cose risaltano:
- La velocità di MiniMax M2.5 migliora notevolmente l'iterazione di attività breviMolte attività reali seguono il ciclo "piccola modifica → esecuzione → modifica". Se ogni ciclo introduce lunghe attese, il cambio di contesto diventa costoso. MiniMax evidenzia esplicitamente "end-to-end più veloce" e "minore utilizzo di token" come risultati fondamentali.
- MiniMax M2.5 tende a scrivere una specifica prima dell'implementazionePer attività multi-file e multi-modulo, preferisco che il modello catturi esplicitamente i limiti di ambito, le relazioni tra i moduli e i criteri di accettazione prima di scrivere il codice. Questo semplifica l'esecuzione, facilitandone la verifica e la standardizzazione, e M2.5 offre ottime prestazioni con questa struttura.
Questi punti non dovrebbero essere trascurati
Nonostante le ottime prestazioni complessive, continuo a considerare i seguenti vincoli che necessitano di misure di sicurezza per il flusso di lavoro:
- La strategia di debug non è sempre proattiva: per bug difficili da localizzare, il modello può modificare ripetutamente l'implementazione senza passare automaticamente a test unitari, logging o passaggi di riproduzione minimi. Spesso devo dare istruzioni esplicite: "aggiungi log / scrivi test / restringi il percorso di errore".
- Il recupero esterno e l'integrazione di terze parti possono essere inaffidabili: quando si integrano determinati servizi esterni, il modello potrebbe produrre passaggi di integrazione errati. Preferisco limitare gli input con esempi di documentazione ufficiale invece di affidarmi a codice "assemblato tramite recupero".
- La sincronizzazione tra codice e documentazione non è sempre predefinita: quando un'attività richiede di "aggiornare il codice e anche aggiornare la documentazione/Skill markdown", utilizzo una checklist esplicita per ridurre la possibilità che venga aggiornato solo il codice.
Questi vincoli non sono esclusivi di M2.5; sono delle misure di sicurezza che applico alla maggior parte dei flussi di lavoro degli agenti di codifica.
In questa fase, mi posiziono MiniMax M2.5 come un modello di produttività agentica orientato all'ingegneriaNon fornisce solo risultati di benchmark, ma rivela anche il runtime end-to-end, il consumo di token, l'efficienza dell'iterazione e la struttura dei prezzi, il che mi consente di valutare i costi di distribuzione reali utilizzando un insieme coerente di parametri.
Alcuni utenti potrebbero chiedersi se generare una specifica prima della codifica aumenti il costo dei token e indebolisca l'affermazione "low cost". La mia conclusione pratica è:
- Sì, scrivere una Spec aggiunge alcuni token di output.
- In molti flussi di lavoro reali, tale costo è compensato da un minor numero di cicli di rielaborazione e da un minor numero di iterazioni avanti e indietro, in particolare per attività multi-file, multi-modulo o che richiedono un debug intenso.
- Il sovraccarico è solitamente controllabile, a patto che la specifica non sia eccessivamente lunga e non ripeta i dettagli di implementazione.
Ecco alcuni consigli pratici per ridurre al minimo l'overhead dei token Spec:
- Per piccoli compiti: richiedere esplicitamente "nessuna specifica; fornire una differenza di codice più i passaggi del test".
- Per compiti di medie/grandi dimensioni: vincola la specifica a X linee / X punti elenco (ad esempio, 10–15), concentrandosi solo su struttura e criteri di accettazione, non dettagli di implementazione.
- Nelle catene di strumenti degli agenti: tratta la Spec come la unica fonte di veritàAggiornare prima la sezione Spec pertinente quando i requisiti cambiano, quindi procedere alla codifica e alla convalida. Questo riduce le spiegazioni ripetute e lo spreco di token nascosti dovuto alla ripetizione del contesto.


