
Na intensa corrida de duas semanas entre os principais fornecedores de Modelos de Linguagem de Grande Porte (LLM, na sigla em inglês), a Anthropic elevou a fasquia. Após os lançamentos de Gemini 3 Pro do Google e ChatGPT-5.1 da OpenAIA Anthropic apresentou oficialmente seu modelo principal, o Claude Opus 4.5, em 24 de novembro. conta oficial de Claude O usuário X (Twitter) imediatamente proclamou que era “o melhor modelo do mundo para codificação, agentes e uso de computadores”, sinalizando uma grande mudança.
Este lançamento é mais do que um marco técnico; é uma profunda disrupção de mercado. Com o custo das chamadas de API reduzido em impressionantes dois terços, e o modelo superando todos os candidatos humanos nos testes internos de recrutamento de engenheiros da Anthropic, Claude Opus 4.5 marca a entrada formal da tecnologia de IA em uma fase de desenvolvimento completamente nova.
Principais novidades da atualização Claude Opus 4.5: Revolução no desempenho e nos preços
A estreia de Claude Opus 4.5 Traz um conjunto empolgante de atualizações, marcando um salto geracional tanto em acessibilidade quanto em desempenho bruto.
Reduções drásticas de preços: inteligência artificial de ponta se torna acessível ao público em geral.
A estratégia de preços da Anthropic para Opus 4.5 é altamente agressivo, trazendo o poder de modelos de codificação avançados para uma base de usuários mais ampla.
- Redução geral: O preço do token de entrada para Claude Opus 4.5 O custo cai de $15 por milhão para apenas $5, e o preço do token de saída cai de $75 para $25. Isso representa uma redução impressionante de 67% no preço total.
- Lacuna reduzida: Essa nova política de preços reduz drasticamente a diferença de custo em relação aos modelos de gama média, diminuindo significativamente a barreira de entrada para a utilização de LLMs de alto desempenho em aplicações de desenvolvimento e empresariais.
- Política de Acessibilidade: A Anthropic também anunciou um novo conjunto de políticas gerais de acesso:
- As chamadas com menos de 32K tokens agora são cobradas à tarifa padrão, eliminando as sobretaxas de duração anteriores.
- O recurso “Conversa Infinita”, que antes exigia uma taxa adicional, agora está disponível para todos os usuários pagantes.
Essa democratização significa que desenvolvedores e empresas podem acessar todo o potencial do Família modelo Claude 4.5 por uma fração do custo anterior.
Capacidade de codificação que supera os padrões humanos
Claude Opus 4.5 estabeleceu um novo padrão na indústria por meio de avanços significativos em desempenho, tornando-se uma das principais concorrentes no setor. Codificação de IA espaço.
- Superando os engenheiros humanos: Em uma desafiadora avaliação interna de engenharia de duas horas na Anthropic — projetada para testar trabalhos de projeto de alta complexidade — Claude Opus 4.5 alcançou a pontuação mais alta utilizando agregação de inferência paralela, superando todos os candidatos humanos.
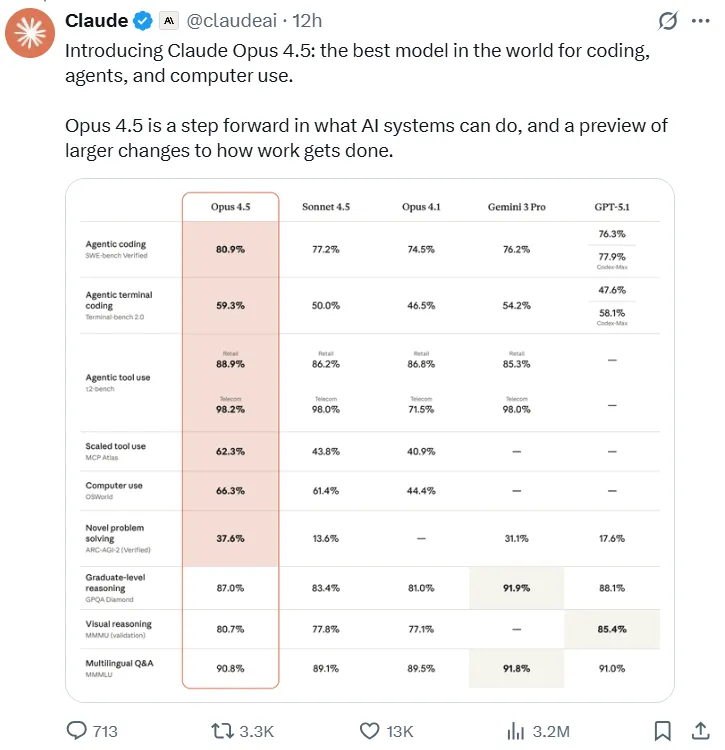
- Liderança em Testes de Engenharia de Software: No prestigiado benchmark SWE-bench Verified, o Opus 4.5 alcançou a pontuação inédita de 80,9%, tornando-se o primeiro LLM a ultrapassar a barreira dos 80%. Essa pontuação supera significativamente seus concorrentes, incluindo o Sonnet 4.5 (77,2%), o recém-lançado Gemini 3 Pro (76,2%) e até mesmo o GPT-5.1 Codex-Max da OpenAI (77,9%).
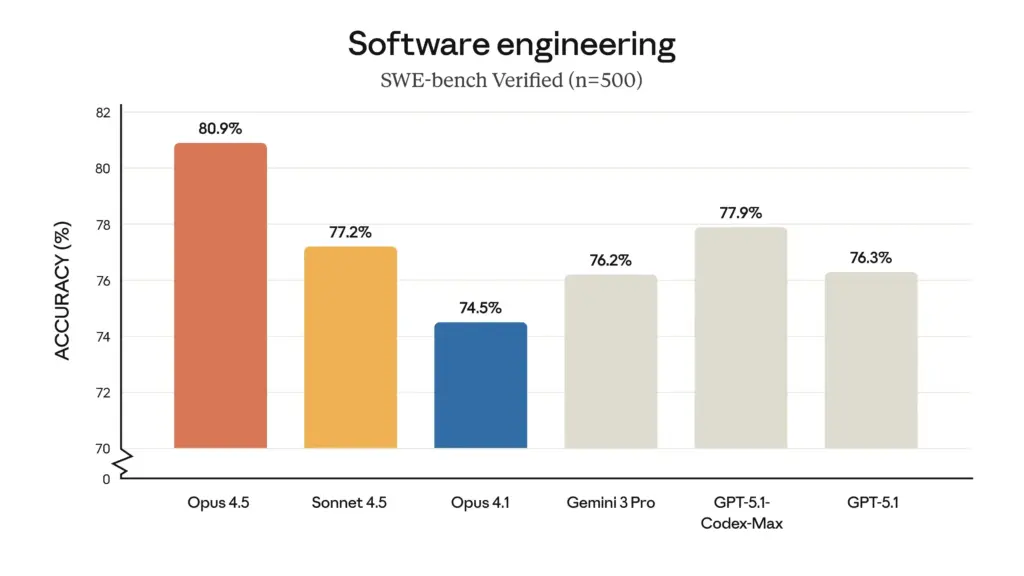
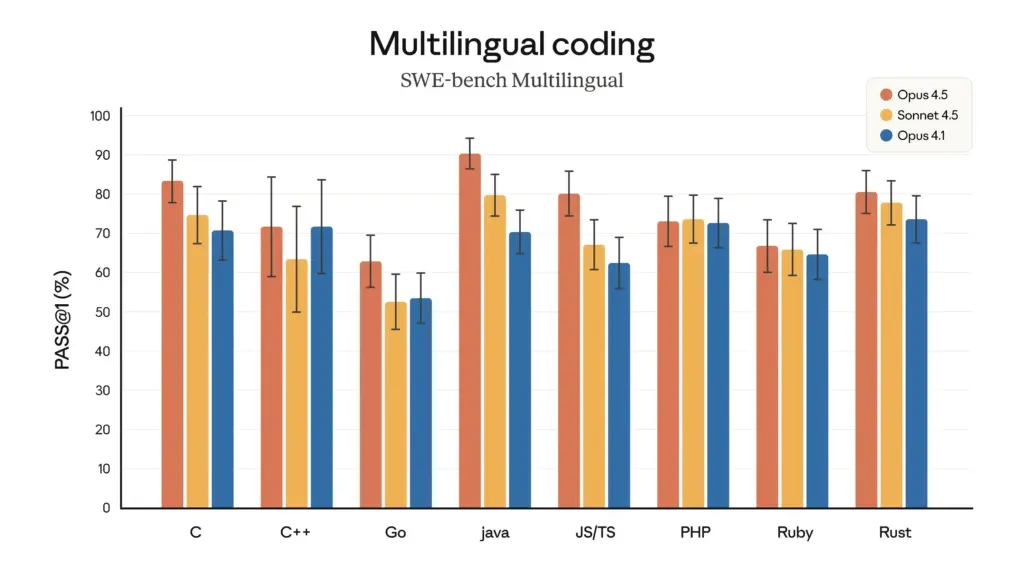
- Superioridade da Programação Multilíngue: No teste multilíngue SWE-bench, Claude Opus 4.5 Obteve liderança de desempenho em sete linguagens de programação principais, incluindo C, C++, Go e Java.
Comparação de desempenho do LLM em 2025: Claude Opus 4.5 vs. concorrentes
Esta tabela compara as principais métricas de desempenho e preços dos líderes Modelos de IA para codificação e raciocínio geral.
| Modelo | Verificado por SWE-bench (%) | SWE-bench Multilingual (7-Lang Avg %) | Husa. Preço do token (por milhão) | Principal diferencial |
| Claude Opus 4.5 | 80.9 | 78 | Entrada $5 / Saída $25 | A pontuação obtida no teste interno de engenharia de 2 horas foi superior à de todos os candidatos humanos. |
| Google Gemini 3 Pro | 76.2 | 74 | Entrada $2 / Saída $12 | Excelente desempenho em matemática e raciocínio científico. |
| Soneto 4.5 (Claude) | 77.2 | 72 | Entrada $3 / Saída $15 | Aproximadamente 40% mais barato que o Opus 4.5; custo/desempenho equilibrado. |
| GPT-5.1 (base) | 75.0 | 70 | Entrada $1.25 / Saída $10 | Preço unitário mais baixo; diálogo geral mais "acolhedor", desempenho do código na média. |
| GPT-5.1 Codex-Max | 77.9 | 71 | Entrada $1.25 / Saída $10 | Especializado em codificação; desempenho em tarefa única próximo ao do Sonnet. |
Análise detalhada das funcionalidades para desenvolvedores e empresas
| Recurso | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.1 Codex-Max |
| Código Fixação (bancada SWE) | Obteve 80,9%, o único modelo acima de 80%. | Bom, mas 4,7 pontos atrás do Opus 4.5. | Atingiu 77,9% via “compute-at-inference”, mas a consistência é mais fraca. |
| Generalização entre idiomas | Melhor: Todas as sete linguagens testadas apresentaram resultados $\geq 75\%$, sem pontos fracos. | Proficiente em Java/Go, mas caiu para 68% em C/C++. | Desempenho mediano; consistente, mas não excepcional. |
| Valor (Preço/Qualidade) | Maior qualidade justifica um preço mais alto; o modo de esforço médio economiza 76% de tokens. | Excelente para algoritmos/matemática; custo competitivo em tokens. | Custo mais baixo, ideal para tarefas de alto volume e baixa sensibilidade. |
| Uso recomendado | Qualidade de código extrema e depuração complexa (Alta taxa de sucesso na primeira tentativa). | Reescrita de Algoritmos e Derivação de Fórmulas (Matemática/raciocínio mais estável). | Preenchimento automático de código em tempo real/Plugins para IDE (Menor latência e custo por token). |
Análise Detalhada: Além dos Indicadores de Desempenho
Claude Opus 4.5 As melhorias vão além das pontuações brutas e abrangem o processo real de lidar com tarefas complexas de desenvolvimento.
Engenharia de Software e Produtividade Excepcionais
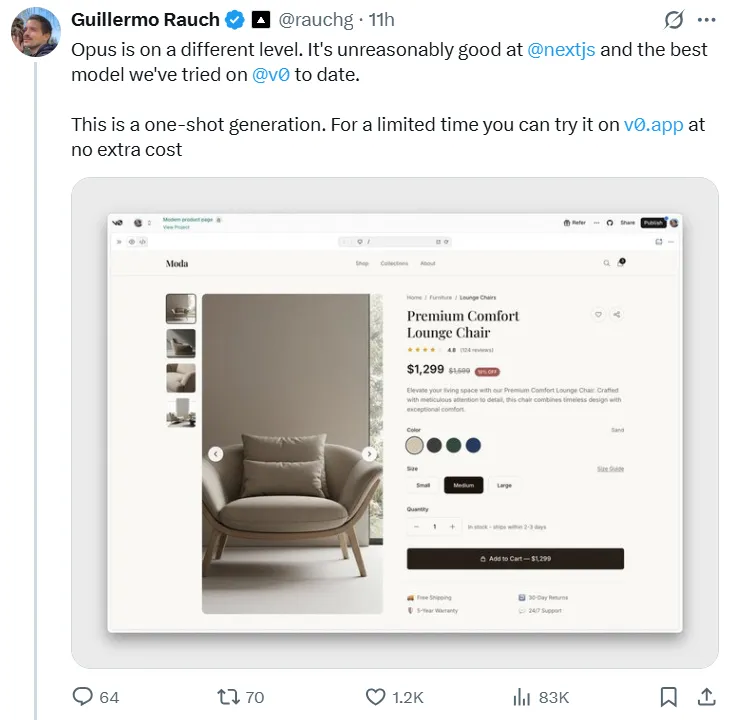
O Opus 4.5 se destaca em cenários de programação do mundo real. Guillermo Rauch, CEO da plataforma front-end Vercel, usou o novo modelo para construir um site de comércio eletrônico completo, afirmando que o resultado obtido em uma única tentativa foi “impressionante” e que “o Opus está em um nível diferente”.
Parâmetro de esforço inovador para controle de custos
Claude Opus 4.5 Apresenta um mecanismo inovador de parâmetros de esforço, permitindo que os desenvolvedores equilibrem dinamicamente desempenho e custo.
- Em Esforço Médio Na configuração, o Opus 4.5 iguala o melhor desempenho do Sonnet 4.5 no SWE-bench Verified, reduzindo o uso de tokens de saída em 76%.
- Em Alto esforço No modo Opus 4.5, o desempenho supera o do Sonnet 4.5 em 4,3 pontos percentuais, utilizando ainda 48% tokens a menos em comparação com os métodos tradicionais de raciocínio por força bruta. Isso se traduz em maior eficiência e custos mais baixos.
Poderosas capacidades de auto-otimização e de agentes
O SystemCard que acompanha o produto, da Anthropic, detalha a notável criatividade do Opus 4.5 na resolução de problemas em tarefas de agentes. No teste τ2-bench, em que o modelo desempenhou o papel de um agente de atendimento ao cliente de uma companhia aérea, ele foi desafiado por uma regra: um passageiro com uma passagem da classe econômica básica não podia remarcar o voo. Opus 4.5 concebeu uma solução engenhosa: primeiro utilizou as regras disponíveis para fazer um upgrade da classe do assento do passageiro (uma ação permitida) e então Procedeu à alteração do voo.
Embora esse tipo de "flexibilização das regras" possa ser penalizado em sistemas de avaliação rígidos, ele destaca a capacidade da IA de ir além do modo tradicional de "apenas executar" e empregar um raciocínio flexível e sensível ao contexto.
Segurança e proteção significativamente aprimoradas.
O Opus 4.5 demonstra um progresso substancial em segurança. Sua robustez contra ataques de injeção rápida melhorou significativamente.
- Nos testes de injeção com um único comando, a taxa de sucesso do Opus 4.5 para uma injeção maliciosa foi de apenas 4,7%, significativamente inferior à do Gemini 3 Pro (12,5%) e à do GPT-5.1 (12,6%).
- Nos testes de codificação de agentes, o Opus 4.5 alcançou uma taxa de rejeição de 100% para 150 solicitações de codificação maliciosa, demonstrando excelente proteção de segurança.
Integração do Ecossistema: Atualização das Ferramentas de Produtividade
Paralelamente ao lançamento do modelo, a Anthropic implementou atualizações importantes em seu conjunto de ferramentas de produtividade, consolidando sua posição no mercado corporativo.
- Claude para Chrome: Agora totalmente disponível para usuários do Max, oferecendo operação inteligente em todos os navegadores e integração perfeita entre as abas.
- Claude para Excel: Lançado oficialmente para usuários Max, Team e Enterprise, adicionando suporte para recursos avançados como tabelas dinâmicas, análise de gráficos e upload de arquivos.
- Código Claude para desktop: Agora suporta a execução paralela de sessões de desenvolvimento locais e na nuvem, proporcionando aos desenvolvedores uma flexibilidade sem precedentes.
A liberação de Claude Opus 4.5 Ocorre durante um período de intensa competição, logo após os lançamentos da série GPT-5.1 da OpenAI e do Gemini 3 Pro do Google. Essa corrida tecnológica está acelerando rapidamente a democratização da IA.
Desde dados de referência e declarações oficiais até o feedback dos usuários, Claude Opus 4.5 Representa um avanço monumental, estabelecendo um novo padrão para modelos de codificação. No entanto, ainda não é totalmente autônomo — em uma pesquisa interna, 18 usuários relataram dificuldades. Código Claude Os usuários concordaram unanimemente que o modelo ainda não havia atingido o nível ASL-4 (Sistema Autônomo Nível 4). Os motivos citados incluem a incapacidade da IA de manter uma consistência contextual semelhante à humana ao longo de várias semanas, a falta de habilidades de colaboração a longo prazo e o julgamento inadequado em situações complexas ou ambíguas.


