À medida que os sistemas de resposta a perguntas se tornam mais avançados, os desenvolvedores estão explorando novas técnicas para aprimorar seu desempenho. Uma abordagem promissora é o modelo RAG (Retrieval-Augmented Generation), que combina recuperação de informações e recursos de linguagem generativa. Ao refinar a incorporação usada para recuperação de dados específicos de um domínio, os pesquisadores encontraram uma maneira de melhorar significativamente a precisão das respostas dos modelos RAG. Este artigo analisa os detalhes dessa técnica.
Introdução ao RAG
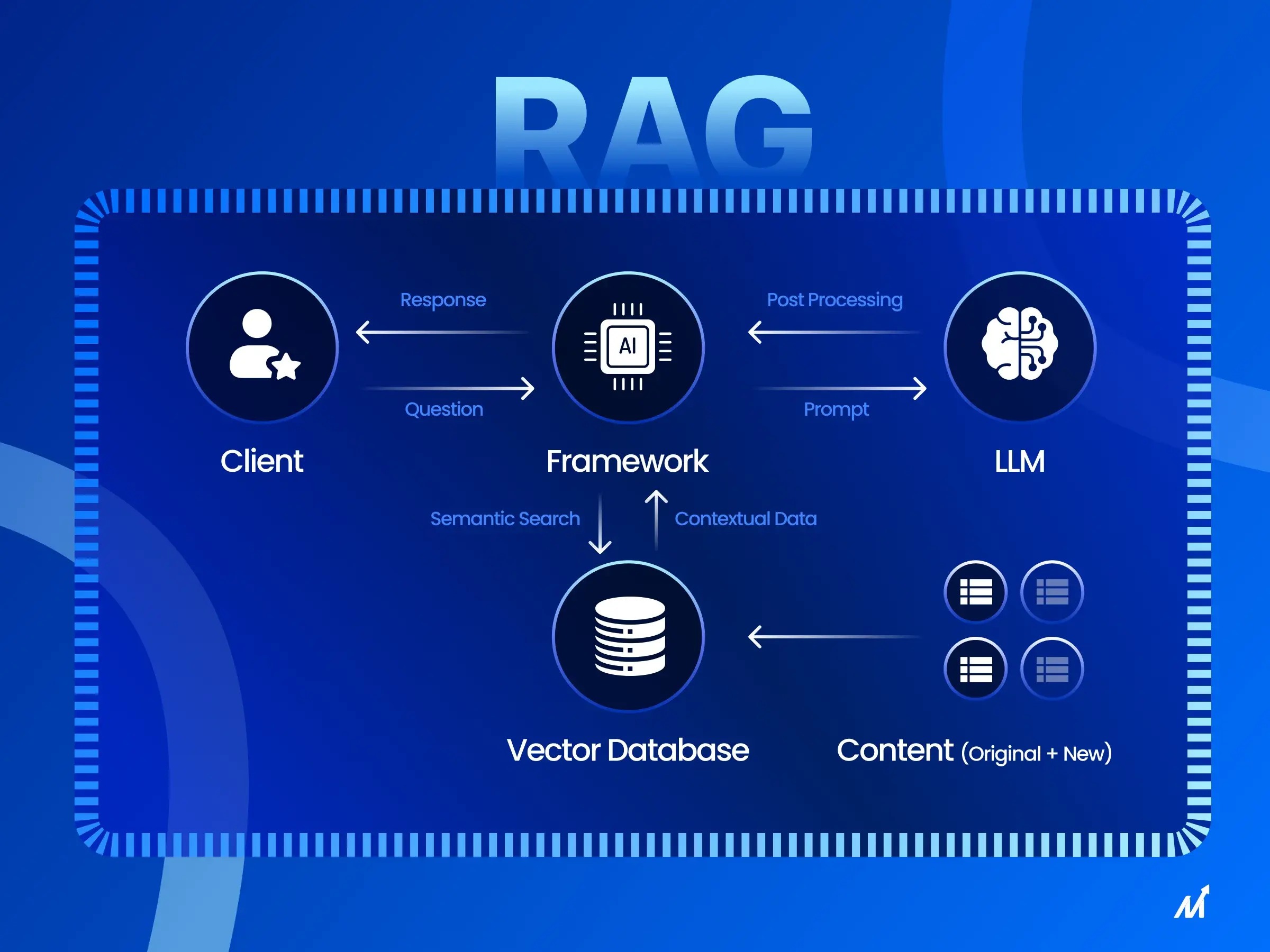
Para entender melhor por que o ajuste de embeddings é tão eficaz para modelos RAG, primeiro precisamos abordar alguns detalhes sobre o próprio RAG.
O que é RAG?
RAG significa Recuperação-Geração Aumentada. É um método que combina recuperação de informações com modelos generativos. Um modelo RAG primeiro recupera informações relevantes e, em seguida, gera uma resposta com base nessas informações. Isso aumenta a capacidade do modelo de responder a perguntas complexas. Ele tem duas partes: um recuperador e um gerador. O recuperador extrai trechos relevantes de um grande corpus de documentos com base na pergunta. O gerador então usa esses trechos para gerar uma resposta coerente. Essa abordagem funciona melhor para responder a perguntas de domínio aberto, pois pode buscar dinamicamente as informações mais recentes.
Prós e limitações dos modelos RAG
Comparados aos modelos tradicionais de recuperação de texto e modelos generativos, os modelos RAG têm algumas vantagens:
- Pode fornecer resultados de pesquisa mais precisos e úteis
- Pode lidar com consultas complexas e textos longos
- Pode gerar resultados de pesquisa personalizados com base na intenção do usuário
No entanto, os modelos RAG também apresentam algumas limitações:
- Treinamento e inferência são computacionalmente caros
- Altos requisitos para dados de treinamento e capacidade do modelo
- Dificuldade em lidar com consultas e textos de domínios especializados
O papel dos embeddings no RAG
Com os conceitos básicos do RAG abordados, vamos nos aprofundar em como os embeddings desempenham um papel crucial e podem ser otimizados.

Comparação de recall de diferentes modelos de incorporação em dados de domínio
Este experimento utilizou mais de 30.000 fragmentos de conhecimento e 600 perguntas padrão do usuário para testes de recall. Comparamos principalmente o desempenho de recall dos modelos m3e-base, bge-base-zh e bce-embedding-base_v1 em dados de entrada em chinês e inglês.
Ajuste fino do modelo de incorporação em dados de domínio
- Coleta de dados: colete dados suficientes relacionados ao domínio, incluindo documentos, pares de perguntas e respostas, etc. Esses dados devem cobrir pontos-chave de conhecimento e perguntas comuns no domínio.
- Pré-processamento: limpe e pré-processe os dados para remover ruído e redundância, garantindo a qualidade dos dados.
- Ajuste fino: ajuste fino de um modelo embarcado pré-treinado (por exemplo, BERT) nos dados do domínio. O treinamento contínuo nos dados do domínio ajuda o modelo a se adaptar melhor à semântica e ao uso da linguagem naquele domínio.
- Avaliação e otimização: avalie o desempenho do modelo de incorporação ajustado no RAG e ajuste os parâmetros de treinamento e conjuntos de dados conforme necessário para otimizar ainda mais o desempenho.
Por meio do ajuste fino, o modelo de incorporação pode entender melhor a semântica específica do domínio, melhorando assim os recursos de recuperação e geração do modelo RAG e aumentando as taxas de resposta e a qualidade.
Tomando o modelo m3e como exemplo:
Baixar: https://huggingface.co/moka-ai/m3e-base
Referência de ajuste fino: https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
Após o ajuste fino dos dados de domínio e novos testes de recall, observamos um aumento direto na taxa de recall de 33% – um resultado muito promissor.
Conclusão
O ajuste fino do modelo de incorporação é uma maneira eficaz de melhorar as taxas de resposta do RAG. Ao fazer o ajuste fino em dados de domínio, o modelo de incorporação pode compreender melhor a semântica específica do domínio, impulsionando assim o desempenho geral do modelo RAG. Embora os modelos RAG apresentem vantagens significativas em QA de domínio aberto, seu desempenho em domínios específicos ainda precisa de maior otimização. Pesquisas futuras podem explorar mais métodos de ajuste fino e melhorias na qualidade dos dados para aprimorar ainda mais a precisão das respostas e a usabilidade dos modelos RAG em todos os domínios.


