
Em 27 de janeiro, a DeepSeek lançou o OCR 2 como um modelo de código aberto. Após analisar seus relatório técnicoAcredito que isso representa uma mudança sistemática na forma como a IA compreende dados visuais. Em vez de simplesmente aumentar o número de parâmetros, o DeepSeek focou em mudanças arquitetônicas fundamentais para melhorar o desempenho além dos limites dos modelos tradicionais de visão e linguagem (VLMs).
DeepSeek OCR 2 é mais do que apenas reconhecimento de texto.
O DeepSeek OCR 2 é um modelo de visão e linguagem de última geração com 3 bilhões de parâmetros. Ele difere significativamente de ferramentas tradicionais como o Tesseract ou modelos visuais básicos. O OCR 2 prioriza dois objetivos específicos:
- Ordem de leitura correta: Mantém a sequência adequada para textos com várias colunas, notas de rodapé e a relação entre cabeçalhos e corpo do texto.
- Estrutura de layout estável: Isso garante que tabelas, listas e conteúdo misto sejam formatados em estruturas utilizáveis.
Se você precisa processar digitalizações de PDF para entrada em banco de dados, limpar dados para sistemas RAG ou analisar relatórios financeiros complexos, o OCR 2 oferece um alto nível de precisão e reconstrução lógica.
Inovação arquitetônica: por que o DeepSeek OCR 2 é tão eficiente?
Substituindo o CLIP por um modelo de linguagem
A maioria dos modelos visuais mais antigos usa o CLIP como componente de processamento de imagens. O CLIP foi projetado para associar imagens a rótulos de texto. No entanto, ele não consegue compreender a relação lógica entre diferentes partes de um documento denso.
O DeepSeek Solução: Eles usaram Qwen2-0,5B (uma arquitetura baseada em LLM) como núcleo do codificador de visão.
O benefício: Como o codificador é baseado em um modelo de linguagem, os tokens visuais possuem uma capacidade básica de raciocínio durante o estágio inicial. O modelo consegue identificar quais pixels pertencem a um cabeçalho e quais pertencem ao limite de uma tabela, o que leva a um processamento de dados mais preciso.
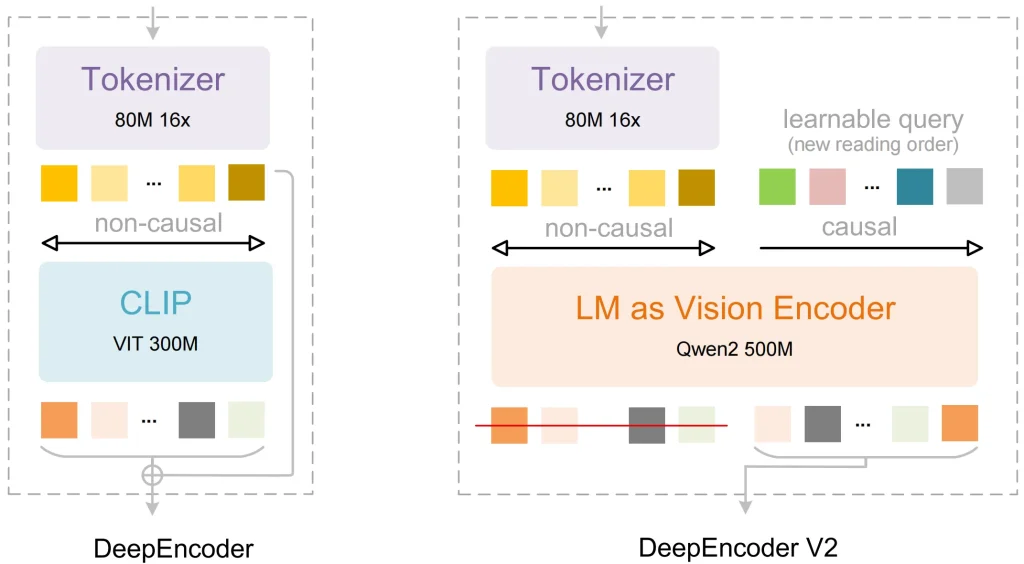
DeepEncoder V2 e Fluxo Causal Visual
Esta é a inovação técnica mais significativa do OCR 2. Muitos modelos processam imagens em uma grade fixa, do canto superior esquerdo para o canto inferior direito. Essa ordem fixa frequentemente causa erros quando o modelo encontra tabelas complexas ou páginas com várias colunas.
O DeepSeek Solução: Eles acrescentaram Fluxo Causal Visual para o componente DeepEncoder V2:
- O modelo primeiro coleta as informações globais de toda a página.
- Ele usa consultas aprendíveis para reordenar os tokens visuais.
- Ele envia essa sequência logicamente organizada para o decodificador para gerar o texto.
Isso permite que o modelo colete informações com base no significado real dos dados. Como as informações são organizadas por layout e semântica durante a etapa de codificação, a saída final é muito estável.
| Métrica | Modelos tradicionais de OCR | DeepSeek OCR 2 |
| Erro na ordem de leitura | Alto (dificuldades com colunas) | Significativamente menor (a distância de edição caiu para 0,057) |
| Compressão de Tokens | Baixo (milhares de tokens por página) | Muito alto (256 a 1120 tokens por página) |
| Estabilidade/Precisão | Propenso à repetição ou a erros | Precisão do 97% (com compressão de 10x) |
Aprimorando a codificação visual em direção ao raciocínio
Especialistas descrevem o OCR 2 como um "codificador visual orientado por modelo de linguagem". Isso significa que o codificador se concentra em relações espaciais e informações estruturais, em vez de apenas extrair características visuais básicas.
Os resultados:
No teste profissional OmniDocBench v1.5, o OCR 2 alcançou uma pontuação de 91,09. Isso representa uma melhoria de 3,73 pontos em relação à versão anterior. A maior parte do progresso ocorreu na precisão da leitura de ordens e no processamento de layouts complexos.
Como usar o DeepSeek OCR 2: 3 métodos de implantação rápida
A DeepSeek disponibilizou os pesos do modelo no Hugging Face. Você pode usar estes três métodos para acessar o modelo para produção ou pesquisa:
Método 1: Ajuste fino rápido via Unsloth(Recomendado)
O Unsloth é otimizado para OCR 2 e reduz significativamente o uso de memória.
from unsloth import FastVisionModel import torch # Carregar o modelo model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # Usar quantização de 4 bits para economizar memória ) # Prompt template prompt = " <|grounding|>Por favor, converta este documento para Markdown e extraia todas as tabelas.</grounding>Método 2: Inferência de Alto Desempenho com vLLM
Essa é a melhor opção para organizações que precisam lidar com muitas solicitações simultaneamente.
- Configurações: A DeepSeek recomenda definir o
temperaturaPara obter os resultados mais consistentes, defina o valor para 0,0. - Suporte a idiomas: Você pode especificar o idioma de destino no prompt. Ele suporta mais de 100 idiomas.
Método 3: Transformadores de rosto de abraço padrão
Para máxima flexibilidade, utilize a biblioteca padrão:
- Instale os requisitos:
pip install transformers einops addict easydict. - Carregar o modelo:
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", trust_remote_code=True).
Dica: Ao processar digitalizações inclinadas, girar a imagem em apenas 0,5 graus para endireitá-la pode ajudar o modelo a produzir resultados ainda melhores.
Com base na minha longa observação da indústria de IA, a DeepSeek tem se destacado consistentemente como pioneira na otimização de algoritmos essenciais. Notei que... primeiro modelo OCR Em outubro de 2025, a compressão de tokens já era utilizada para melhorar a eficiência.
O OCR 2 não é apenas uma atualização de desempenho. Ele representa uma mudança fundamental na forma como a IA processa a lógica visual. Ao usar uma arquitetura de modelo de linguagem para codificação visual, o DeepSeek aumentou a profundidade com que a IA compreende dados complexos. Acredito que esses esforços demonstram um alto nível de visão de futuro. Esse método de organizar informações em um nível fundamental permite que a IA leia de uma maneira mais semelhante à lógica humana e fornece um novo padrão para extração precisa de dados no futuro.


