Em minhas avaliações de modelos recentes, uma pergunta continua surgindo: Um agente de codificação consegue manter-se rápido, confiável e acessível quando as tarefas envolvem edições em vários arquivos, depuração repetida e uso de ferramentas — e não apenas respostas de uma única etapa? O MiniMax M2.5 é um dos poucos lançamentos que vem com quantidade suficiente de bateria. detalhes de eficiência e preços de ponta a ponta Para testar essa questão de forma concreta.
Por que estou prestando atenção ao M2.5
Dou menos ênfase à "melhor pontuação de referência" e mais à capacidade de um modelo executar fluxos de trabalho reais:
- Entrega de ponta a pontaEscopo → implementação → validação → entregáveis
- Eficiência operacional: iterações de chamadas de ferramentas, uso de tokens e estabilidade em tempo de execução
- Agente economia: se o modelo de precificação suporta agentes de longa duração e iterações repetidas
O MiniMax M2.5 é interessante porque visa otimizar capacidade, eficiência e custo na mesma versão — uma combinação importante para as equipes de engenharia que tomam decisões de implementação.
Para que serve o M2.5
Com base em materiais oficiais, MiniMax M2.5 está posicionada para cargas de trabalho de produtividade do mundo real em três vertentes principais:
- Para Engenharia de Software (Codificação Agenética)Representado por SWE-Bench Verified, Multi-SWE-Bench e com ênfase no desempenho estável em diferentes sistemas de arreios.
- Para uso em buscas e ferramentas interativasIncluindo BrowseComp, Wide Search e o benchmark interno RISE da MiniMax, projetado para refletir uma exploração mais aprofundada em fontes web profissionais.
- Para produtividade no escritório: focado em tarefas orientadas a resultados no Word, PowerPoint e Excel, com suporte de uma estrutura de avaliação (GDPval-MM) que considera a qualidade da saída, os rastros de execução do agente e o custo do token.
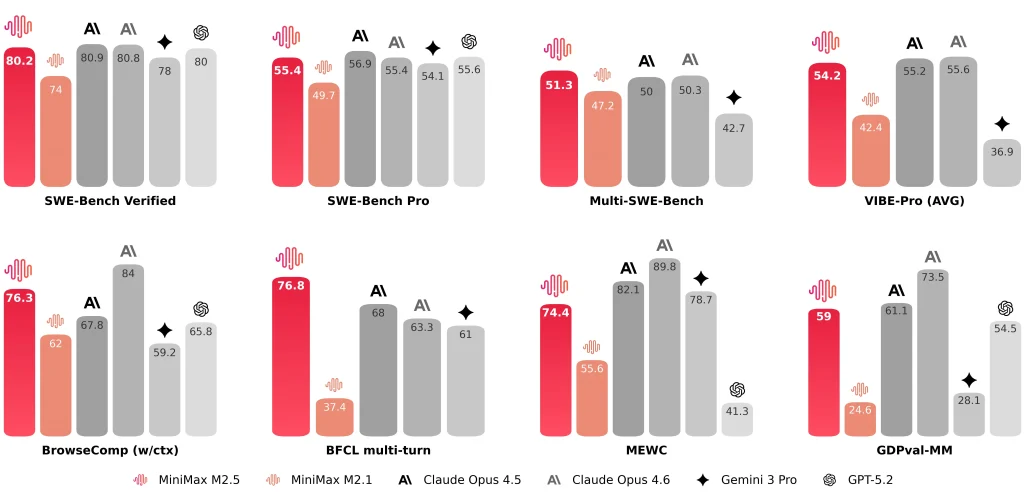
A MiniMax também divulga resultados representativos, tais como: SWE-Bench Verificado 80.2%, Bancada Multi-SWE 51.3%, e BrowseComp 76.3%.
MiniMax M2.5 vs M2.1 e Claude Opus 4.6: O que eu comparo
M2.5 vs M2.1 vs Claude Opus 4.6 (Tabela de Métricas Principais)
| Dimensão | M2.5 | M2.1 | Claude Opus 4.6 |
| Verificado pelo SWE-Bench | 80.20% | 74.0% | 81.42% (Relatório antropológico) ~78-80% (Média pública) |
| Tempo médio de execução de ponta a ponta por tarefa de engenharia de software. | 22,8 min | 31,3 min | 22,9 min |
| Tokens por tarefa SWE (média) | 3,52 milhões | 3,72 milhões | — (Provavelmente >4M devido à verbosidade) |
| Iterações de busca/ferramenta versus geração anterior | ~20% menos iterações (relatadas) | Linha de base | — |
| Banco SWE com arnês cruzado (Droid) | 79.7 | 71.3 | 78.9 |
| Bancada SWE de chicote cruzado (OpenCode) | 76.1 | 72.0 | 75.9 |
| Opções de taxa de transferência | ~50 tokens/s (padrão) ~100 tokens/s (Lightning) | ~57 tokens/s | ~67-77 tokens/s |
| Preços (por 1 milhão de tokens de entrada) | $0.3 (padrão e Lightning) | $0.3 | $5.0 |
| Preços (por 1 milhão de tokens de saída) | $1.2 (padrão) $2.4 (Relâmpago) | $1.2 | $25.0 |
| Intuição horária (saída contínua) | ~$0,3/h a 50 t/s ~$1/h a 100 t/s | ~$0,3/h a 57 t/s | ~$6,50/h a 70 t/s |
Notas:
- “—” significa que o valor não foi fornecido nos materiais aqui resumidos.
- Os benchmarks podem variar de acordo com o ambiente, a configuração da ferramenta, os prompts e as convenções de relatório, portanto, eu os trato como indicadores de alcanceNão se trata de rankings absolutos.
M2.5 vs M2.1: Computação de ponta a ponta mais rápida, menor uso de tokens, menos iterações de busca.
A comparação oficial é apresentada de forma acessível à área de engenharia. Dou atenção a três métricas específicas:
- Tempo de execução de ponta a ponta: o tempo médio de execução das tarefas de engenharia de software cai de 31,3 minutos (M2.1) para 22,8 minutos (M2,5), descrito como um Melhoria 37%.
- Tokens por tarefa: o uso de tokens por tarefa diminui de 3,72 milhões para 3,52 milhões.
- eficiência de iteração de busca/ferramentaEm BrowseComp, Wide Search e RISE, o MiniMax apresenta melhores resultados com menos iterações, com um custo de iteração de aproximadamente [valor omitido]. 20% inferior do que M2.1.
Para mim, essas melhorias importam mais do que uma única pontuação de referência, porque determinam diretamente taxa de transferência do agente e custo operacional sustentável.
M2.5 vs Claude Opus 4.6: Faixa de codificação semelhante, contexto de avaliação importa
Ao comparar M2.5 com Claude Opus 4.6Eu trato as pontuações como intervalos em vez de classificações absolutas, porque as configurações de ferramentas, os comandos e as convenções de relatório podem variar.
- Antrópico observa que Opus 4.6's SWE-bench verificado O resultado é uma média ao longo de 25 tentativase menciona um valor observado mais alto (81,42%) sob ajustes imediatos.
- Relatórios da MiniMax SWE-Bench Verificado 80.2% para MiniMax M2.5.
Numericamente, os dois parecem estar em uma faixa competitiva semelhante para benchmarks de agentes de codificação. De uma perspectiva de engenharia, me preocupo mais com a estabilidade em diferentes formatos de projeto — front-end + back-end, diferentes estruturas e integrações de terceiros — do que com um único número principal.
Como o M2.5 muda meu fluxo de trabalho (notas práticas)
Velocidade e estilo de fluxo de trabalho
Após a integração MiniMax M2.5 Em uma cadeia de ferramentas de agentes de codificação, duas coisas se destacam:
- A velocidade do MiniMax M2.5 melhora significativamente a iteração de tarefas curtas.Muitas tarefas reais seguem o ciclo "pequena alteração → executar → ajustar". Se cada iteração do ciclo introduzir longas esperas, a troca de contexto torna-se dispendiosa. O MiniMax destaca explicitamente "computação de ponta a ponta mais rápida" e "menor uso de tokens" como resultados principais.
- O MiniMax M2.5 tende a escrever uma especificação antes da implementação.Para tarefas com múltiplos arquivos e módulos, prefiro que o modelo capture explicitamente os limites do escopo, os relacionamentos entre os módulos e os critérios de aceitação antes de escrever o código. Isso facilita a auditoria e a padronização da execução, e o M2.5 tem um bom desempenho nessa estrutura.
Esses pontos não devem ser ignorados.
Mesmo com um desempenho geral sólido, ainda considero os seguintes pontos como restrições que exigem diretrizes de fluxo de trabalho:
- A estratégia de depuração nem sempre é proativa.Para bugs difíceis de localizar, o modelo pode modificar repetidamente a implementação sem alternar automaticamente para testes unitários, registro de logs ou etapas mínimas de reprodução. Muitas vezes preciso instruir explicitamente: "adicione logs / escreva testes / identifique o caminho da falha".
- A recuperação externa de dados e a integração com terceiros podem ser pouco confiáveis.Ao integrar determinados serviços externos, o modelo pode gerar etapas de integração incorretas. Prefiro restringir as entradas com exemplos da documentação oficial em vez de depender de código "montado a partir da recuperação".
- A sincronização de código e documentação não é consistentemente definida por padrão.Quando uma tarefa exige "atualizar o código e também a documentação/markdown do Skill", eu uso uma lista de verificação explícita para reduzir a chance de que apenas o código seja atualizado.
Essas restrições não são exclusivas do M2.5; são diretrizes que aplico à maioria dos fluxos de trabalho de agentes de codificação.
Nesta fase, eu posiciono MiniMax M2.5 como um modelo de produtividade agentiva orientado para a engenhariaNão se limita a fornecer resultados de referência; também revela o tempo de execução de ponta a ponta, o consumo de tokens, a eficiência de iteração e a estrutura de preços, o que me permite avaliar o custo real de implantação usando um conjunto consistente de métricas.
Alguns usuários podem questionar se gerar uma especificação (Spec) antes de codificar aumenta o custo do token e compromete a alegação de "baixo custo". Minha conclusão prática é:
- Sim, escrever uma especificação adiciona alguns tokens de saída.
- Em muitos fluxos de trabalho reais, esse custo é compensado por menos retrabalho e menos iterações de ida e volta., especialmente para tarefas que envolvem vários arquivos, módulos diferentes ou depuração intensiva.
- A sobrecarga geralmente é controlável, desde que a especificação não seja excessivamente longa e não repita detalhes de implementação.
Aqui estão algumas dicas práticas para minimizar a sobrecarga do token de especificação:
- Para tarefas pequenas: solicite explicitamente “sem especificação; forneça uma comparação de código mais etapas de teste”.
- Para tarefas de médio/grande porte: restringir a especificação a X linhas / X balas (por exemplo, 10–15), concentrando-se apenas em estrutura e critérios de aceitação, não detalhes de implementação.
- Em cadeias de ferramentas de agentes: trate a especificação como a única fonte de verdadeAtualize primeiro a seção de especificação relevante quando os requisitos mudarem e, em seguida, prossiga para a codificação e validação. Isso reduz explicações repetidas e o desperdício de tokens ocultos ao reiterar o contexto.