
Em 5 de fevereiro, a indústria de IA testemunhou uma "colisão" histórica quando a Anthropic e a OpenAI lançaram seus modelos principais —Claude Opus 4.6 e Códice GPT-5.3—em sequência.
Diante de lançamentos simultâneos de alto perfil como esses, avaliar o vencedor exige olhar além da propaganda e focar em dimensões técnicas objetivas. Geralmente, divido minha análise em três camadas: atualizações técnicas essenciais, o que os benchmarks revelam sobre suas capacidades e como a entrega difere em cenários reais. A seguir, usarei essa estrutura para desconstruir os recursos técnicos e o desempenho empírico desses dois modelos.
Analisando os avanços em Claude Opus 4.6
Com base no meu pesquisas anteriores e o mais recente documentação técnica, a evolução de Claude Opus 4.6 centra-se em diversas atualizações arquitetônicas revolucionárias:
- Pensamento adaptativo: Essa funcionalidade permite que o modelo aloque recursos computacionais dinamicamente com base na dificuldade da tarefa. Nos meus testes, constatei que o modelo responde quase instantaneamente a consultas simples, enquanto entra em um modo de "raciocínio profundo" para projetos arquitetônicos complexos, levando mais tempo para garantir o rigor lógico.
- Contexto e compactação de 1 milhão de tokens API: Embora a janela de 1 milhão de tokens seja enorme, a verdadeira inovação é a API de compactaçãoPara combater a degradação de desempenho típica de conversas longas, esta API comprime de forma inteligente o histórico de diálogos, retendo apenas os nós lógicos críticos. Isso reduz significativamente os custos de inferência para projetos de longa duração.
- Controles de Residência de Dados: Esta versão permite que usuários corporativos restrinjam a inferência de dados a servidores localizados nos EUA. Considero isso uma medida estratégica para atender aos rigorosos requisitos de conformidade de setores regulamentados, como o financeiro e o da saúde.
- Comprimento de saída de 128K: A capacidade máxima de geração de dados em uma única operação foi ampliada para 128.000 tokens, permitindo que o modelo gere blocos de código extensos ou documentos técnicos completos de uma só vez, sem perder a coerência.
Decifrando os pontos fortes de agência do GPT-5.3-Codex
da OpenAI GPT-5.3-Codex Prioriza fortemente a velocidade de execução e a interação em nível de sistema. De acordo com as especificações oficiais, os principais destaques incluem:
- Aumento da eficiência de inferência: O modelo opera 25% mais rápido que seu antecessor, o GPT-5.2 Codex. Em meus testes comparativos, o GPT-5.3 Codex demonstrou uma taxa de transferência significativamente maior para tarefas idênticas de geração de scripts.
- Direção em curvas fechadas: Isso permite que os usuários emitam novas instruções enquanto o modelo está executando uma tarefa de longa duração. Por exemplo, se o modelo estiver executando um script automatizado no terminal, posso intervir e corrigir seu caminho em tempo real sem reiniciar o processo.
- Capacidade operacional em nível de sistema: Posicionado como um “modelo de programação agente”, ele vai além da escrita de código. Foi otimizado para usar ferramentas no nível do sistema operacional, gerenciar implantações e monitorar ambientes de teste de forma autônoma.
- Desenvolvimento autoassistido: A OpenAI revelou que o GPT-5.3 Codex foi utilizado durante suas próprias fases de treinamento e depuração. Isso indica que o modelo atingiu um nível de maturidade técnica que lhe permite auxiliar em sua própria iteração.
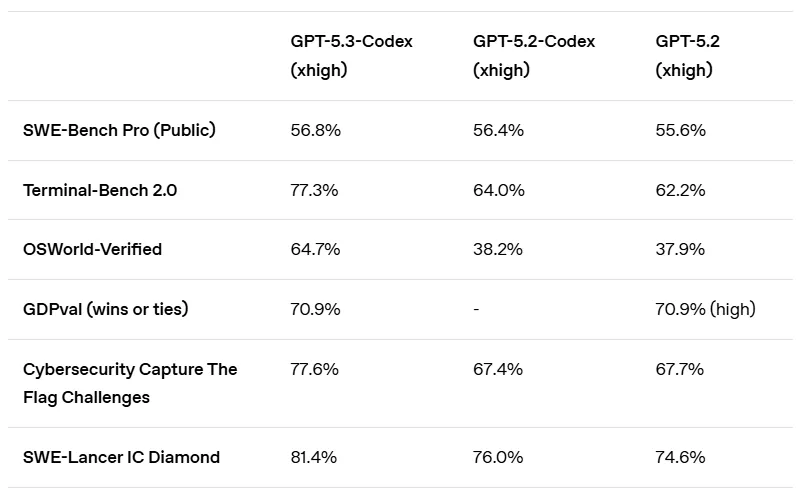
Benchmarks comparativos: Claude Opus 4.6 vs. GPT-5.3-Codex
Para medir o desempenho de forma objetiva, selecionei vários parâmetros de referência padrão do setor. Segue uma breve explicação do que essas métricas representam:
- Bancada de terminais 2.0: Avalia a capacidade da IA de executar comandos complexos e gerenciar tarefas em uma CLI (Interface de Linha de Comando).
- SWE-bench Pro: Mede a taxa de sucesso da IA na resolução de problemas reais de engenharia de software, como correções de bugs reais no GitHub.
- GDPval-AA: Avalia a proficiência do modelo em trabalhos que exigem conhecimento profissional de alto valor, como análise financeira e pesquisa jurídica.
- OSWorld: Testa a capacidade da IA de navegar em uma GUI (Interface Gráfica do Usuário) para concluir tarefas diárias de escritório.
- O Último Exame da Humanidade: Um teste de raciocínio multidisciplinar de alta dificuldade, concebido para expandir os limites do conhecimento especializado.
| Métrica | Claude Opus 4.6 | Códice GPT-5.3 | Quem ganha |
| Bancada de terminais 2.0 | 65.40% | 77.30% | Códice GPT-5.3 |
| SWE-bench Pro | Não divulgado | 57.00% | Códice GPT-5.3 |
| OSWorld | 46.20% | 64.70% | Códice GPT-5.3 |
| GDPval-AA (Elo) | +144 vs Linha de Base | Linha de base | Claude Opus 4.6 |
| O Último Exame da Humanidade | Pontuação máxima | Não divulgado | Claude Opus 4.6 |
| Janela de contexto | 1.000.000 de Tokens | ~200.000 Tokens | Claude Opus 4.6 |
| Melhoria de velocidade | Linha de base | 0.25 | Códice GPT-5.3 |
Análise de cenários do mundo real: qual modelo escolher?
Com base nos parâmetros técnicos e dados acima, recomendo o seguinte para diferentes necessidades profissionais:
Escolha Claude Opus 4.6 se:
- Você é um arquiteto de software: É a melhor opção para refatorar projetos legados que envolvem centenas de milhares de linhas de código.
- Você trabalha em áreas de alta conformidade: Apresenta melhor desempenho nas áreas de finanças ou direito, onde a precisão lógica e o cumprimento das normas são imprescindíveis.
- Você tem tolerância zero para “alucinações”: Nos testes mais recentes de "Agulha no Palheiro", sua capacidade de memorização em contexto longo atingiu 76%, superando em muito os concorrentes.
Escolha o Codex GPT-5.3 se:
- Você é um desenvolvedor Full-Stack: É otimizado para alta velocidade de desenvolvimento e tarefas que exigem interação frequente com terminais, bancos de dados e plataformas em nuvem.
- Você prefere a programação com intervenção humana: A direção em curvas fechadas é perfeita para desenvolvedores que desejam ajustar o fluxo lógico da IA por meio de diálogo contínuo.
- Você é especialista em Segurança Cibernética: Sendo o primeiro modelo classificado com "Capacidade de Segurança Cibernética de Alto Nível", ele detém uma vantagem decisiva na detecção e defesa contra vulnerabilidades.
Minha conclusão em relação a esse lançamento simultâneo é que ambas as empresas se voltaram para a "execução de tarefas de longa duração" e a "engenharia de agentes", embora com focos diferentes. Claude Opus 4.6 Destaca-se em contextos ultralongos, gerenciamento de sessões (Compactação) e conformidade empresarial. Por outro lado, GPT-5.3-Codex Domina em benchmarks de engenharia de software, velocidade de execução e utilização de ferramentas a longo prazo.
Para a seleção em nível de equipe, sugiro uma regra simples: execute um teste A/B usando seus repositórios internos reais. Monitore a taxa de sucesso, o número de revisões, o custo e o tempo de entrega, em vez de confiar apenas em benchmarks de terceiros.
Para usuários individuais, assinar ambos os serviços pode ser proibitivamente caro. Nesse caso, recomendo usar um agregador como iWeaverIsso permite que você acesse ambos os modelos com uma única assinatura, possibilitando a alternância instantânea entre Claude e GPT até encontrar a opção ideal para sua tarefa específica.


