
Avalio o GLM-5 principalmente como um modelo de engenharia, não como um modelo de bate-papo genérico que só precisa "soar bem". Minha abordagem é direta: primeiro, uso benchmarks públicos amplamente referenciados para confirmar a posição do GLM-5 no nível superior e, em seguida, valido esses sinais com um fluxo de trabalho repetível Para verificar se o GLM-5 é realmente mais estável e prático para tarefas reais de engenharia. Com base nesse processo, minha conclusão é que o progresso do GLM-5 não se resume apenas à escala — ele também avança em eficiência de contexto longo, treinamento de agentes, e estabilidade de saída de nível de engenharia Ao mesmo tempo. Essa combinação ajuda a explicar por que seu desempenho se aproxima dos principais modelos fechados, tanto em rankings compostos quanto em avaliações de agentes no mundo real.
Utilizo duas métricas para estabelecer a posição do GLM-5.
Para evitar depender apenas de impressões subjetivas, baseio minha avaliação do GLM-5 em duas vertentes complementares de avaliação de Análise Artificial:
- Índice de Inteligência Artificial de Análise (pontuação de capacidade composta): Pontuações GLM-5 50, o que a coloca no nível mais alto. Pontuações mais altas incluem Claude Opus 4.6 (Raciocínio Adaptativo) em 53 e GPT-5.2 (xhigh) em 51, enquanto Claude Opus 4.5 também está no 50 alcance. Este índice agrega múltiplas avaliações em uma única pontuação que reflete a força geral em raciocínio, codificação e habilidades relacionadas.
- GDPval-AA (avaliação agentiva do trabalho intelectual no mundo real): GLM-5 tem um Classificação Elo de 1412Em termos simples, Elo é um pontuação de força relativa frente a frente—Um Elo mais alto significa uma taxa de sucesso geral maior no mesmo conjunto de tarefas. O GDPval-AA foi projetado para simular o trabalho real (por exemplo, recuperar informações, analisá-las e produzir entregáveis) e permite que os modelos operem em um ambiente de agentes com acesso a ferramentas.
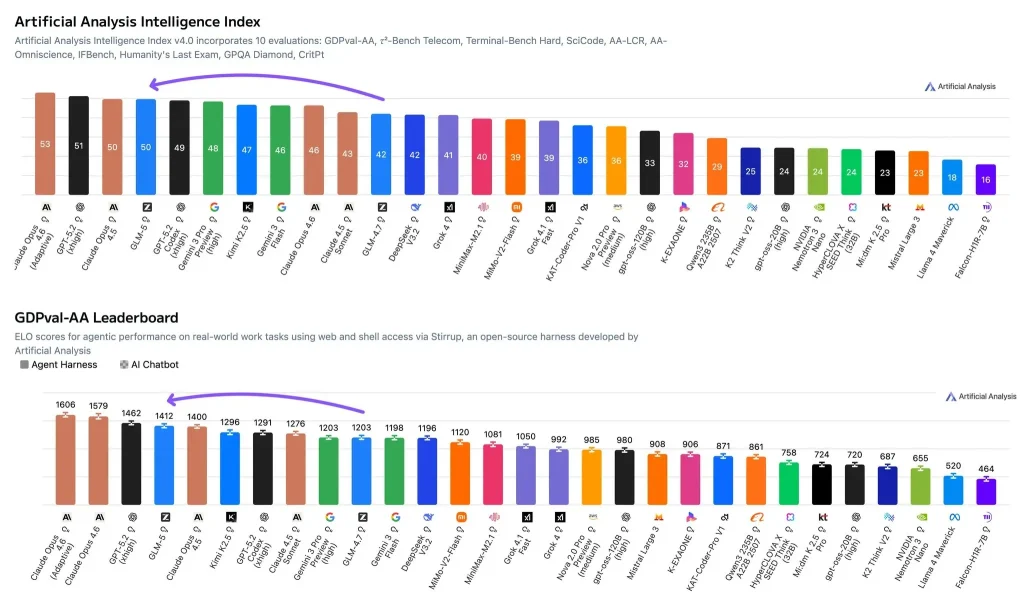
Consideradas em conjunto, essas duas métricas apontam para uma hipótese clara: É improvável que a vantagem do GLM-5 venha de "truques" isolados em conjuntos de teste. É mais provável que ela provenha da qualidade de execução e da estabilidade em tarefas complexas de múltiplas etapas.
Como eu testo o GLM-5: três fluxos de trabalho de engenharia de alta frequência
Meus testes práticos se assemelham mais a uma verificação de aceitação de engenharia do que a uma "demonstração de resultados". Eu me concentro menos em se o modelo consegue gerar explicações mais longas e mais em se ele consegue fornecer resultados corretos e utilizáveis sob certas restrições. Eu testo principalmente três tipos de fluxo de trabalho:
- Tarefas de engenharia de software de contexto longo: Forneço um segmento de código mais extenso, além de restrições de documentação, e solicito a localização de problemas entre arquivos e uma proposta de correção com alterações mínimas.
- Edições incrementais de código: Preciso de alterações limitadas a uma função ou módulo específico, mantendo o restante da estrutura intacto, e solicito um patch no estilo diff, além da correção dos riscos de regressão.
- Cadeias de tarefas centradas em ferramentas: Estruturo as tarefas como recuperar → sintetizar → produzir um resultado, e verifico se o modelo consegue solicitar as entradas ausentes de forma clara e propor um caminho de repetição confiável quando algo falha.
Utilizo esses fluxos de trabalho porque as melhorias no Índice de Inteligência e no GDPval-AA devem aparecer com mais clareza em cadeias longas, uso de ferramentas e entregáveis de engenharia em vez de instruções curtas e de turno único.
Principais inovações do GLM-5: uma melhoria estrutural a partir de três alterações de reforço.
A atenção esparsa da DSA torna o contexto longo economicamente sustentável.
Em materiais públicos e o papel, o GLM-5 enfatiza a adoção de DSA (DeepSeek Sparse Attention)Em termos simples: quando as entradas se tornam muito longas, o modelo não precisa gastar a mesma quantidade de processamento computacional em cada token. Em vez disso, ele aloca mais processamento para os tokens que provavelmente são mais importantes e relevantes, reduzindo o custo de treinamento e inferência, ao mesmo tempo que busca preservar a qualidade do contexto longo.
Nos meus testes, a implicação prática é consistente com esse objetivo de design: à medida que o contexto aumenta, A latência tende a aumentar de forma mais suave., e A coerência da saída tende a permanecer mais estável.Isso é importante em contextos de engenharia porque a exploração da base de código, o acúmulo de requisitos e a execução em longo prazo expandem naturalmente o contexto ao longo do tempo.
A infraestrutura de RL assíncrona ("slime") se adapta melhor à interação de longo prazo.
O GLM-5 descreve publicamente uma configuração de aprendizado por reforço assíncrono que desacopla a geração de trajetória (rollout) do treinamento para melhorar o rendimento e a eficiência. Uma interpretação prática disso é que o modelo pode aprender de forma mais eficaz a partir de grandes volumes de registros de interação sobre o modelo. Como concluir tarefas de ponta a ponta, em vez de apenas aprender a produzir respostas que pareçam plausíveis isoladamente.
Em fluxos de trabalho práticos, vejo isso mais claramente no tratamento de falhas: em vez de ficar repetindo trechos de texto improdutivos, o GLM-5 retorna com mais frequência às restrições e propõe soluções. novas etapas executáveisE é mais explícito sobre quais entradas estão faltando.
Os objetivos do treinamento estão mudando em direção à engenharia de agentes, e não ao ganho de habilidades pontuais.
O GLM-5 se posiciona explicitamente como uma transição da “codificação orientada por instruções” para engenharia de agentesInterpreto isso como um objetivo de treinamento que vai além de escrever código ou resolver problemas isolados de raciocínio: o modelo precisa planejar, executar e refletir em horizontes mais longos, produzindo resultados que sejam utilizáveis em fluxos de trabalho de engenharia.
Essa abordagem ajuda a explicar por que o GLM-5 pode ter um bom desempenho no GDPval-AA (tarefas de agentes de trabalho intelectual), ao mesmo tempo que apresenta uma pontuação competitiva no Índice de Inteligência composto.
Por que o GLM-5 ainda está classificado "logo atrás" dos porta-aviões blindados fechados: a diferença é menor, mas não é zero.
O GLM-5 já está na mesma faixa de pontuação de alto nível.
UM 50 A pontuação no Índice de Inteligência sugere que não há grandes pontos fracos nas avaliações agregadas — caso contrário, seria difícil manter uma pontuação nesse nível. Está na mesma faixa que o Claude Opus 4.5 e ligeiramente abaixo do Claude Opus 4.6 (Raciocínio Adaptativo) e do GPT-5.2 (extremamente alto).
O GLM-5 está próximo de se tornar um dos principais dispositivos em termos de trabalho intelectual real. Agente Tarefas
Um Elo de 1412 O GDPval-AA indica altas taxas de sucesso relativas em tarefas de trabalho intelectual com suporte de ferramentas. Para decisões de implementação, isso costuma ser mais preditivo do que a acurácia estática em um benchmark específico, pois muitos cenários de produção envolvem recuperação, análise, redação e coordenação de ferramentas.
As diferenças remanescentes se manifestam na extrema dificuldade e na maturidade das políticas.
Sistemas de segurança fechados geralmente mantêm vantagens em termos de maturidade de políticas: autoverificação mais consistente, limites de recusa mais confiáveis e menos erros em casos extremos. O GLM-5 pode se aproximar desse nível, mas para um subconjunto de tarefas complexas ainda pode exigir restrições mais claras ou mecanismos de proteção mais robustos em nível de sistema para garantir resultados consistentes.
Vantagens que confirmo na prática: o GLM-5 se comporta mais como um copiloto de engenharia do que como um chatbot.
Edições incrementais mais confiáveis, menos reescritas desnecessárias.
Quando preciso de alterações localizadas, preservando a estrutura circundante, o GLM-5 geralmente produz substituições direcionadas ou edições no estilo diff em vez de reescrever módulos inteiros. Isso reduz o trabalho de revisão e facilita o gerenciamento dos riscos de regressão.
Melhor consistência de restrições em cadeias de tarefas mais longas.
Ao dividir uma tarefa em várias etapas e impor restrições rigorosas a partir de etapas anteriores, o GLM-5 tende a manter essas restrições consistentes à medida que o contexto se expande, reduzindo suposições contraditórias.
Mais saídas executáveis da cadeia de ferramentas e melhor recuperação após falhas.
Em fluxos de trabalho de recuperação → síntese → entrega, foco em verificar se o modelo consegue gerar etapas executáveis e uma lista de verificação clara de "entradas ausentes". O GLM-5, com mais frequência, impulsiona o fluxo de trabalho em vez de permanecer na camada de explicação.
Limitações a serem conhecidas antecipadamente: o que pode bloquear a adoção em produção
Os custos de implantação e de sistemas ainda são elevados.
O GLM-5 é um modelo MoE de grande escala. Mesmo que apenas parte do modelo seja ativada por token, a auto-hospedagem ainda requer trabalho substancial em planejamento de memória, agendamento de concorrência, estratégia de cache chave-valor, quantização e compatibilidade com mecanismos de inferência.
Não vai ganhar automaticamente em todos os segmentos especializados.
O Índice de Inteligência e o GDPval-AA tendem a favorecer o raciocínio geral e tarefas de trabalho intelectual. Se o seu domínio for altamente especializado — por exemplo, fluxos de trabalho de conformidade rigorosa, demonstrações matemáticas formais de nicho ou controle de estilo extremamente detalhado — você ainda deve realizar testes A/B direcionados antes de se comprometer.
Um modelo robusto não substitui uma engenharia de sistemas robusta.
Em implantações com agentes, a falha mais comum não é "o modelo não consegue responder", mas sim "a cadeia de execução não está controlada". Permissões de ferramentas, isolamento de segurança, observabilidade, lógica de repetição e verificação de evidências continuam sendo necessários para transformar a capacidade do modelo em desempenho estável em produção.
Quando eu priorizaria o GLM-5
Se meu objetivo é que um modelo desempenhe um papel significativo em um fluxo de trabalho de engenharia (e não apenas produza respostas isoladas), o GLM-5 é um candidato de primeira linha, especialmente para:
- Tarefas de engenharia de longo contexto: depuração entre arquivos, refatoração, localização de problemas complexos
- Fluxos de trabalho centrados em ferramentas: recuperação, criação de scripts, síntese de dados, entregáveis de documentos
- Requisitos para categorias de peso livre: Implantação local, personalização e limites de custo/controle mais rigorosos.
Se sua carga de trabalho for dominada por perguntas e respostas curtas, extremamente sensível a custos/QPS, ou se você operar sob limites de conformidade muito rígidos, sem tolerância a proteções em nível de sistema, eu começaria com modelos mais leves ou soluções de ponta fechadas como base e adicionaria o GLM-5 somente se ele apresentar um retorno claro.

