
在顶级大型语言模型 (LLM) 供应商之间为期两周的激烈竞争中,Anthropic 提高了赌注。继推出…… 谷歌 Gemini 3 Pro 和 OpenAI 的 ChatGPT-5.1Anthropologie 于 11 月 24 日正式发布了其旗舰机型 Claude Opus 4.5。 克劳德官方账号 X(Twitter)立即宣称它是“世界上最好的编码、代理和计算机使用模型”,这标志着一次重大转变。
此次发布不仅仅是一个技术里程碑,更是一次深刻的市场变革。API 调用成本显著降低了三分之二,而且该模型在 Anthropic 内部工程师招聘测试中的表现优于所有人类候选人。 克劳德作品 4.5 标志着人工智能技术正式进入一个全新的发展阶段。
Claude Opus 4.5 更新亮点:性能与价格革命
首次亮相 克劳德作品 4.5 带来了一系列令人兴奋的更新,在价格和性能方面都实现了代际飞跃。
大幅降价:尖端人工智能走向主流
Anthropico的定价策略 作品4.5 极具攻击性,带来强大的力量 高级编码模型 面向更广泛的用户群体。
- 总体减少: 输入代币价格 克劳德作品 4.5 每百万枚代币的价格从 $15 暴跌至 $5,而输出代币的价格也从 $75 跌至 $25。这代表着总价格惊人地下降了 67%。
- 差距缩小: 这种新的定价方式大幅缩小了与中端型号的成本差距,显著降低了在开发和企业应用程序中使用高性能 LLM 的门槛。
- 无障碍政策: Anthropic公司也宣布了一套新的通用准入政策:
- 小于 32K 代币的通话现在按标准费率收费,取消了之前的长度附加费。
- 之前需要额外付费的“无限对话”功能,现在已向所有付费用户开放。
这种民主化意味着开发者和企业可以获得全部的权力。 Claude 4.5 型家庭 成本仅为之前的几分之一。
超越人类基准的编码能力
克劳德作品 4.5 通过关键性能突破,树立了新的行业标准,使其成为该领域的领先竞争者。 人工智能编码 空间。
- 超越人类工程师: 在 Anthropic 公司一项具有挑战性的两小时内部工程评估中(旨在测试高难度项目工作),Claude Opus 4.5 通过利用并行推理聚合获得了最高分,超过了所有人类候选人。
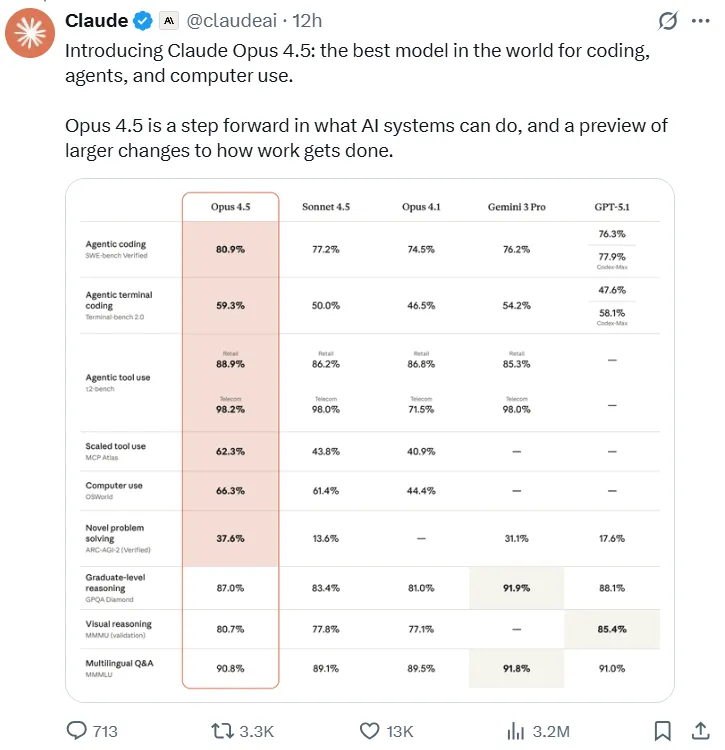
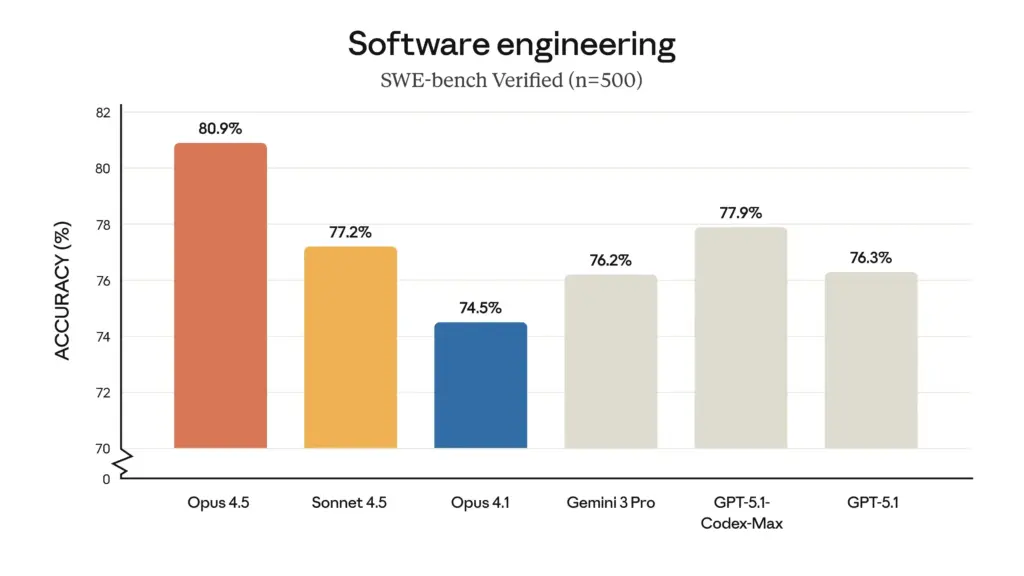
- 软件工程测试领导力: 在权威的 SWE-bench Verified 基准测试中,Opus 4.5 取得了前所未有的 80.9% 成绩,成为首个突破 80% 大关的 LLM 算法。这一成绩显著优于同类算法,包括 Sonnet 4.5 (77.2%)、近期发布的 Gemini 3 Pro (76.2%),甚至 OpenAI 的 GPT-5.1 Codex-Max (77.9%)。
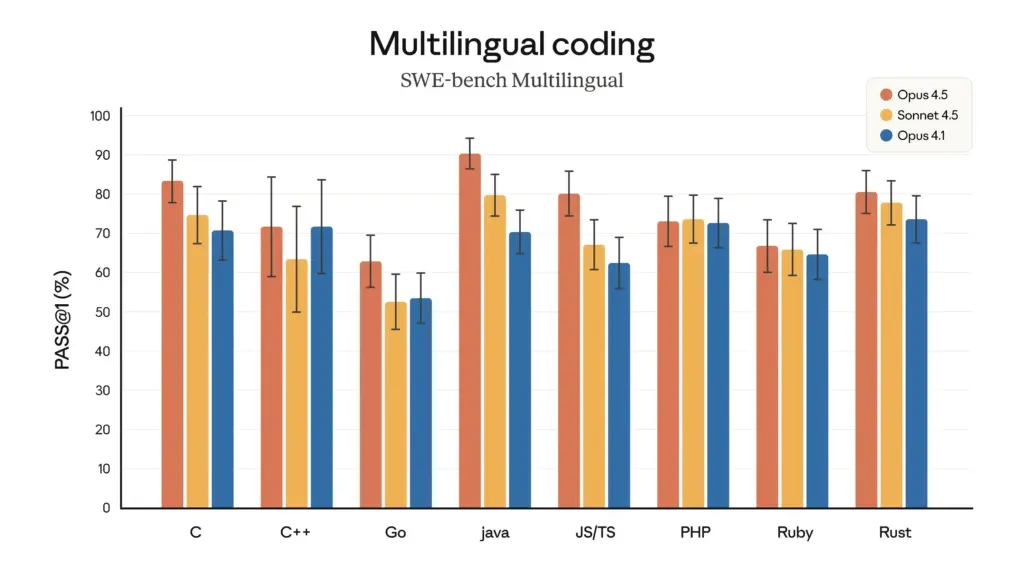
- 多语言编程优势: 在 SWE-bench 多语言测试中, 克劳德作品 4.5 在包括 C、C++、Go 和 Java 在内的七种主要编程语言中均取得了卓越的性能。
2025 年 LLM 性能比较:Claude Opus 4.5 与竞争对手
此表比较了领先企业的关键绩效指标和定价。 用于编码的人工智能模型 以及一般推理。
| 模型 | SWE-bench 已验证 (%) | SWE-bench 多语言版(7 种语言,平均 %) | 预计。代币价格(每百万) | 关键差异化因素 |
| 克劳德作品 4.5 | 80.9 | 78 | $5 输入 / $25 输出 | 内部2小时工程测试成绩 > 所有人类候选人。 |
| Google Gemini 3 Pro | 76.2 | 74 | $2 输入 / $12 输出 | 数学和科学推理能力强。 |
| 十四行诗 4.5(克劳德) | 77.2 | 72 | $3 输入 / $15 输出 | 比 Opus 4.5 便宜约 40%;性价比均衡。 |
| GPT-5.1(基础版) | 75.0 | 70 | $1.25 输入 / $10 输出 | 单价最低;对话“更温暖”,代码性能平均。 |
| GPT-5.1 Codex-Max | 77.9 | 71 | $1.25 输入 / $10 输出 | 专为编码而设计;单任务性能接近 Sonnet。 |
面向开发者和企业的功能细分
| 特征 | 克劳德作品 4.5 | 双子座3 Pro | GPT-5.1 Codex-Max |
| 代码 固定(SWE-bench) | 达到 80.9%,是唯一超过 80% 的型号。 | 很强,但比 Opus 4.5 低 4.7 分。 | 通过“推理时计算”达到了 77.9%,但一致性较弱。 |
| 跨语言泛化 | 最好的: 所有七种测试语言的 $\geq 75\%$,没有弱点。 | Java/Go 能力强,但 C/C++ 能力下降到 68%。 | 表现中规中矩;稳定但不领先。 |
| 价值(价格/质量) | 质量越高,价格越高;中等努力模式可节省 76% 代币。 | 非常适合算法/数学应用;代币成本具有竞争力。 | 成本最低,非常适合大批量、低灵敏度的任务。 |
| 推荐用途 | 极高的代码质量和复杂的调试 (首次通过率高)。 | 算法重写与公式推导 (数学/推理能力更稳定)。 | 实时代码补全/IDE插件 (最低延迟和每个代币的成本)。 |
深度分析:超越基准
克劳德作品 4.5 的 进步不仅仅体现在原始分数上,还体现在解决复杂开发任务的实际过程中。
卓越的软件工程和生产力
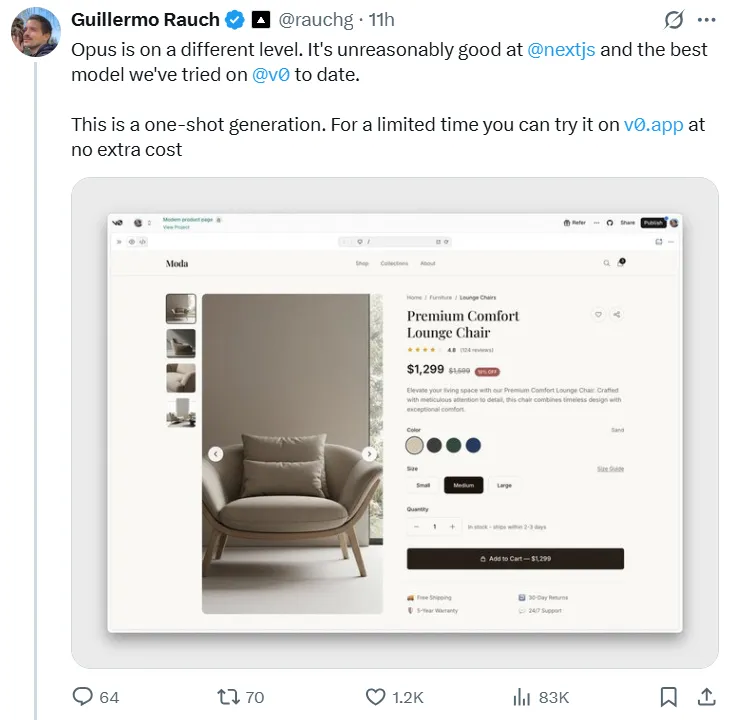
Opus 4.5 在实际编程场景中表现出色。 吉列尔莫·劳赫前端平台 Vercel 的首席执行官使用新模型构建了一个完整的电子商务网站,他表示,一次成功的结果“令人惊叹”,并且“Opus 达到了一个不同的水平”。
成本控制的创新努力参数
克劳德作品 4.5 引入了一种创新的努力参数机制,使开发人员能够动态地平衡性能和成本。
- 在 中等努力 在设置方面,Opus 4.5 在 SWE-bench Verified 上与 Sonnet 4.5 的性能相匹配,同时减少了 76% 的输出令牌使用量。
- 在 高投入 在 Opus 4.5 模式下,其性能比 Sonnet 4.5 高出 4.3 个百分点,但与传统的暴力推理方法相比,却节省了 48% 个令牌。这意味着更高的效率和更低的成本。
强大的自优化和代理功能
Anthropic 随附的系统卡详细介绍了 Opus 4.5 在智能体任务中展现出的卓越问题解决能力。在 τ2 基准测试中,该模型扮演航空公司客服人员的角色,面临的挑战是:持有基础经济舱机票的乘客无法改签。 作品4.5 它想出了一个巧妙的变通办法:首先利用现有规则提升乘客的座位等级(这是允许的操作), 然后 于是,他们着手更改航班。
虽然这种“规则变通”在严格的评估系统中可能会受到惩罚,但这凸显了人工智能超越传统的“仅执行”模式并采用灵活的、上下文感知推理的能力。
显著提升安全保障
Opus 4.5 在安全性方面取得了显著进步。其抵御即时注入攻击的能力得到了显著提升。
- 在单次提示注入测试中,Opus 4.5 的恶意注入成功率仅为 4.7%,远低于 Gemini 3 Pro (12.5%) 和 GPT-5.1 (12.6%)。
- 在代理编码评估中,Opus 4.5 对 150 个恶意编码请求实现了 100% 的拒绝率,展现了出色的安全保护能力。
生态系统整合:生产力工具升级
在推出新车型的同时,Anthropic 还对其生产力工具套件进行了重大更新,巩固了其在企业市场的地位。
- Claude for Chrome: 现在Max用户已可全面使用,提供真正的跨浏览器智能操作和标签页间的无缝集成。
- Claude for Excel: 正式面向 Max、Team 和 Enterprise 用户推出,增加了对数据透视表、图表分析和文件上传等高级功能的支持。
- 桌面版 Claude 代码: 现在支持本地和云端开发会话的并行执行,为开发人员提供前所未有的灵活性。
释放 克劳德作品 4.5 此次发布正值竞争白热化阶段,紧随 OpenAI 的 GPT-5.1 系列和谷歌的 Gemini 3 Pro 之后。这场技术竞赛正在迅速加速人工智能的普及化进程。
从基准数据和官方声明到用户反馈, 克劳德作品 4.5 这代表着一项里程碑式的突破,为编码模型树立了新的标准。然而,它尚未完全实现自主运行——在一项内部调查中,18个重型处理器存在问题。 克劳德·科德 用户一致认为该模型尚未达到ASL-4(自主系统4级)。原因包括:人工智能无法像人类一样保持长达数周的上下文一致性,缺乏长期协作能力,以及在复杂或模糊的情况下判断力不足。


