
1月27日,DeepSeek发布了开源的OCR 2版本。在分析了他们的…… 技术报告我认为这代表了人工智能理解视觉数据方式的系统性转变。DeepSeek并没有简单地增加参数数量,而是专注于根本性的架构变革,以超越传统视觉语言模型(VLM)的性能极限。
DeepSeek OCR 2 不仅仅是文本识别
DeepSeek OCR 2 是一款拥有 30 亿个参数的新一代视觉语言模型。它与 Tesseract 等传统工具或基础视觉模型有着显著区别。OCR 2 优先考虑两个具体目标:
- 正确阅读顺序: 它保持多列文本、脚注以及标题和正文之间关系的正确顺序。
- 稳定的布局结构: 它确保表格、列表和混合内容被格式化为可用的结构。
如果您需要处理用于数据库录入的 PDF 扫描件、清理 RAG 系统的数据或解析复杂的财务报告,OCR 2 可提供高水平的准确性和逻辑重建。
架构创新:DeepSeek OCR 2 为何如此高效?
用语言模型替换 CLIP
大多数旧式视觉模型都使用 CLIP 作为图像处理组件。CLIP 的设计初衷是将图像与文本标签进行匹配。然而,它缺乏理解复杂文档中不同部分之间逻辑关系的能力。
深潜 解决方案: 他们使用 Qwen2-0.5B (基于LLM的架构)作为视觉编码器的核心。
好处: 由于编码器基于语言模型,视觉标记在初始阶段就具备基本的推理能力。该模型可以识别哪些像素属于表头,哪些像素属于表格边界,从而实现更精确的数据处理。
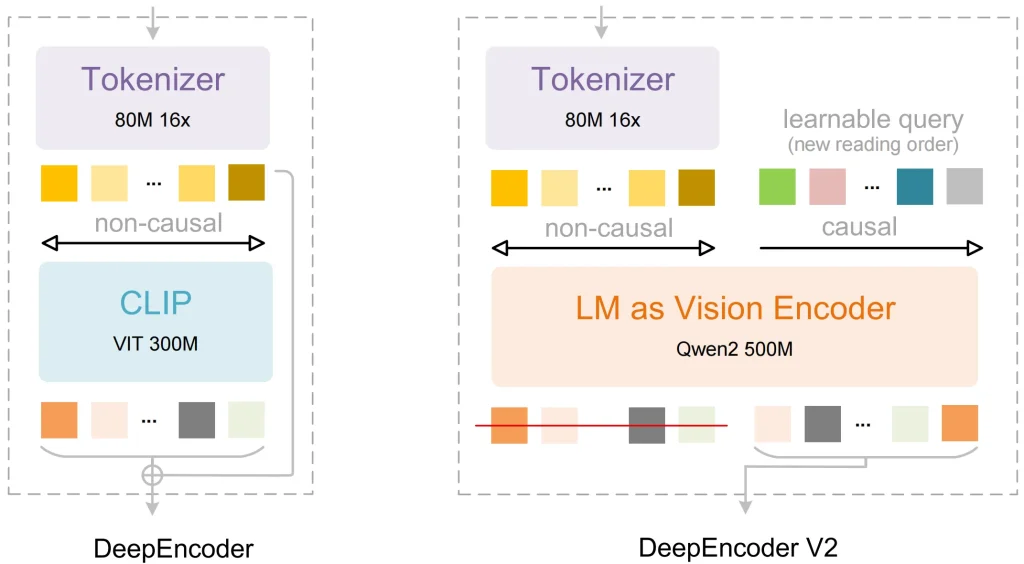
DeepEncoder V2 和视觉因果流
这是OCR 2.0最重要的技术突破。许多OCR模型采用从左上到右下固定的网格顺序处理图像。这种固定顺序在模型遇到复杂表格或多列页面时经常会导致错误。
深潜 解决方案: 他们补充说 视觉因果流 到 DeepEncoder V2 组件:
- 该模型首先收集整个页面的全局信息。
- 它使用可学习的查询来重新排列视觉标记。
- 它将这个逻辑有序的序列发送给解码器以生成文本。
这使得模型能够根据数据的实际含义收集信息。由于信息在编码阶段已按布局和语义进行组织,因此最终输出非常稳定。
| 公制 | 传统OCR模型 | DeepSeek OCR 2 |
| 阅读顺序错误 | 高(难以处理列) | 显著降低(编辑距离降至 0.057) |
| 令牌压缩 | 低(每页数千个令牌) | 非常高(每页 256 – 1120 个令牌) |
| 稳定性/准确性 | 容易重复或出错 | 97% 精度(10 倍压缩) |
将视觉编码转化为推理
专家将OCR 2描述为“语言模型驱动的视觉编码器”。这意味着该编码器侧重于空间关系和结构信息,而不仅仅是提取基本的视觉特征。
结果:
在 OmniDocBench v1.5 专业版测试中,OCR 2 的得分为 91.09 分,比上一版本提高了 3.73 分。大部分提升体现在读取指令的准确性和处理复杂布局的能力上。
如何使用 DeepSeek OCR 2:3 种快速部署方法
DeepSeek 已发布 Hugging Face 模型的权重。您可以使用以下三种方法访问该模型,用于生产或研究:
方法一:通过快速微调 Unsloth(受到推崇的)
Unsloth 针对 OCR 2 进行了优化,并显著降低了内存使用量。
from unsloth import FastVisionModel import torch # 加载模型 model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # 使用 4 位量化以节省内存 ) # 提示模板 prompt = " <|grounding|>请将此文档转换为 Markdown 格式并提取所有表格。方法二:基于vLLM的高性能推理
对于需要同时处理大量请求的组织来说,这是最佳选择。
- 设置: DeepSeek建议设置
温度为获得最一致的结果,设为 0.0。 - 语言支持: 您可以在提示符中指定目标语言。它支持超过100种语言。
方法三:标准拥抱脸变形金刚
为了获得最大的灵活性,请使用标准库:
- 安装所需组件:
pip install transformers einops addict easydict. - 加载模型:
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", trust_remote_code=True).
提示: 处理倾斜的扫描图像时,只需将图像旋转 0.5 度即可将其矫正,这有助于模型产生更好的结果。
根据我长期对人工智能行业的观察,DeepSeek 一直走在优化核心算法的前沿。我注意到他们的 首款OCR模型 2025 年 10 月已采用令牌压缩来提高效率。
OCR 2 不仅仅是性能上的提升,它代表着人工智能处理视觉逻辑方式的根本性变革。DeepSeek 通过使用语言模型架构进行视觉编码,显著提升了人工智能理解复杂数据的深度。我认为这些努力展现了高度的前瞻性。这种从基础层面组织信息的方法,使人工智能能够以更接近人类逻辑的方式进行阅读,并为未来精准的数据提取树立了新的标准。


