随着问答系统日益先进,开发人员正在探索新技术来提升其性能。其中一种颇具前景的方法是 RAG(检索增强生成)模型,它结合了信息检索和生成语言能力。通过微调用于检索特定领域数据的嵌入,研究人员找到了一种显著提高 RAG 模型答案准确率的方法。本文将深入探讨这项技术的细节。
RAG简介
为了更好地理解为什么调整嵌入对于 RAG 模型如此有效,我们首先需要介绍一些 RAG 本身的背景。
什么是 RAG?
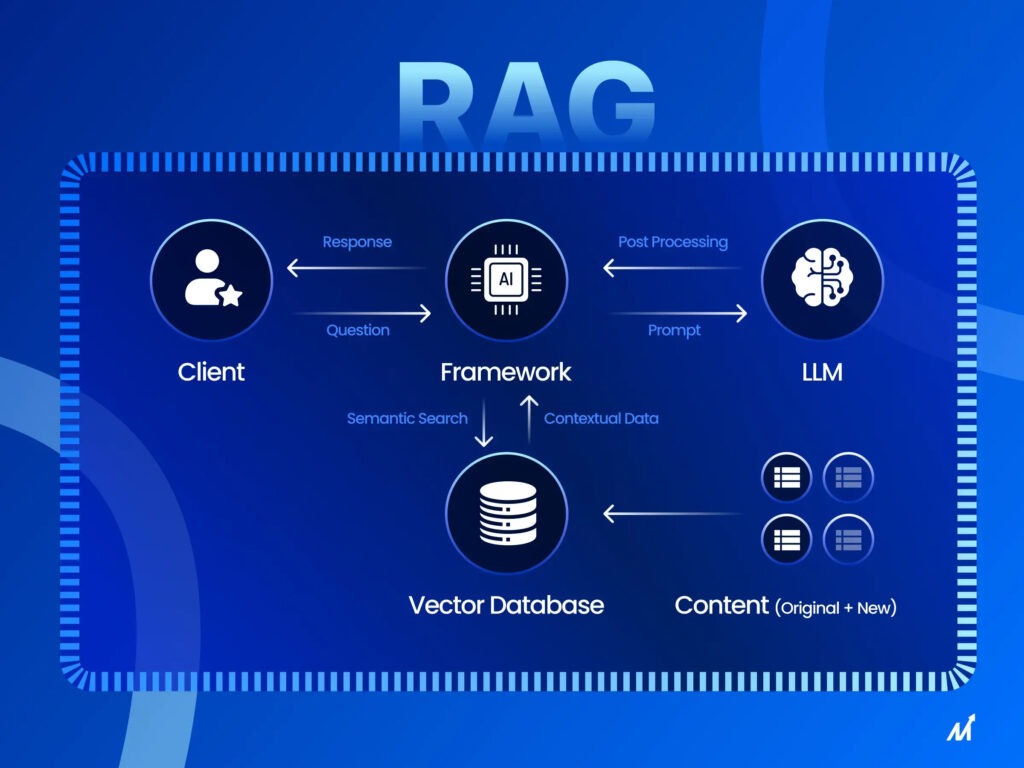
RAG 代表检索增强生成 (Retrieval-Augmented Generation)。它是一种将信息检索与生成模型相结合的方法。RAG 模型首先检索相关信息,然后基于该信息生成答案。这增强了模型回答复杂问题的能力。它包含两部分:检索器和生成器。检索器根据问题从大型文档语料库中提取相关片段。然后,生成器使用这些片段生成连贯的答案。这种方法更适合开放领域问答,因为它可以动态获取最新信息。
RAG 模型的优点和局限性
与传统的文本检索和生成模型相比,RAG模型具有一些优势:
- 可以提供更准确、更有用的搜索结果
- 可以处理复杂的查询和长文本
- 可以根据用户意图生成个性化的搜索结果
然而,RAG模型也存在一些局限性:
- 训练和推理的计算成本很高
- 对训练数据和模型容量要求较高
- 难以处理来自专业领域的查询和文本
嵌入在 RAG 中的作用
了解了 RAG 的基础知识后,让我们深入了解嵌入如何发挥关键作用以及如何进行优化。

不同嵌入模型在领域数据上的召回率比较
本次实验使用了30000+知识片段和600个标准用户问题进行召回测试,主要对比m3e-base、bge-base-zh、bce-embedding-base_v1三个模型在中文和英文输入数据上的召回性能。
在领域数据上微调嵌入模型
- 数据收集:收集足够的领域相关数据,包括文档、问答对等,这些数据应该涵盖领域内的关键知识点和常见问题。
- 预处理:清理和预处理数据,去除噪音和冗余,确保数据质量。
- 微调:在领域数据上对预训练的嵌入式模型(例如 BERT)进行微调。持续在领域数据上进行训练有助于模型更好地适应该领域的语义和语言用法。
- 评估与优化:评估微调后的 Embedding 模型在 RAG 中的性能,并根据需要调整训练参数和数据集,进一步优化性能。
通过微调,Embedding模型可以更好地理解领域特定语义,从而提升RAG模型的检索和生成能力,提高答题率和质量。
以m3e模型为例:
下载:https://huggingface.co/moka-ai/m3e-base
微调参考:https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
在对领域数据进行微调并重新测试召回率后,我们看到召回率直接提高了 33%——这是一个非常有希望的结果。
结论
对 Embedding 模型进行微调是提升 RAG 问答率的有效方法。通过对领域数据进行微调,Embedding 模型可以更好地理解领域特定语义,从而提升 RAG 模型的整体性能。尽管 RAG 模型在开放领域问答中拥有显著优势,但其在特定领域的性能仍需进一步优化。未来的研究可以探索更多微调方法和数据质量改进,以进一步提升 RAG 模型的答案准确性和跨领域的可用性。


