
抽象的: 比较 GPT-5.2-Codex 和 克劳德·科德 用于人工智能工程。利用 ChatGPT-5.2-codex + iWeaver 掌握复杂的后端逻辑并提高效率,使您能够立即成为顶尖的人工智能架构师。
什么是 GPT-5.2-Codex?它与标准 GPT 有何不同?
如果 GPT-5.2 是一个 通才那么,GPT-5.2-Codex 就是一个 专家 专为解决复杂的编程难题而设计。
根据 OpenAI 的最新博客文章GPT-5.2-Codex 不仅仅是基于代码数据进行微调的标准 GPT 模型;它是第一个针对代码数据进行架构优化的模型。 端到端工程.
与标准 GPT 的主要区别:
- 上下文持久性: 标准的GPT模型在长时间的对话中往往会“忘记”之前的定义。相比之下,Codex拥有超长的…… 上下文窗口 针对代码库进行了优化,使其能够理解跨文件依赖关系。
- 执行,而不仅仅是生成: 标准版 GPT 擅长编写“代码片段”,而 GPT-5.2-Codex 则旨在理解整个程序。 存储库在发布会上,Sam Altman 强调 GPT-5.2-Codex 不仅仅是一个简单的自动完成工具;它的功能就像人类工程师一样——阅读文档、查找错误文件、编写补丁和通过测试——使开发人员能够在真实的开发环境中执行任务。
主要亮点:数据和能力的双重飞跃
GPT-5.2-Codex 的发布在技术界引发了广泛的讨论,主要集中在以下三个方面:
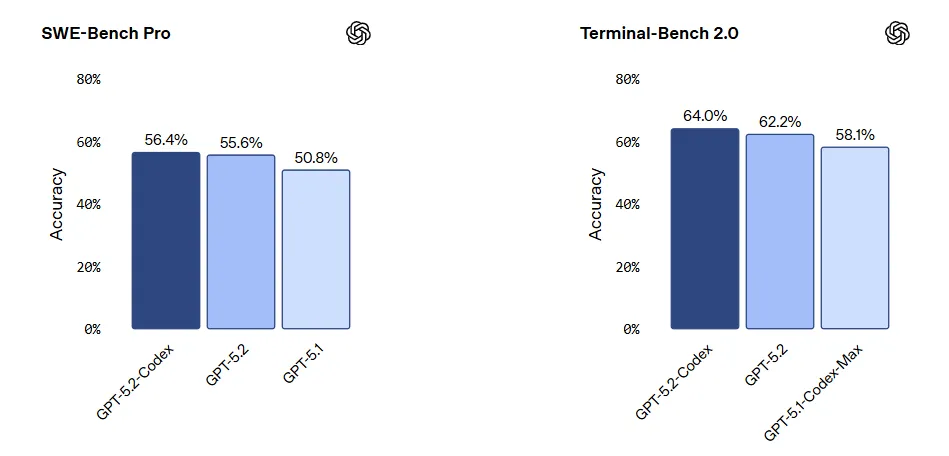
- 在 SWE-bench Pro 测试中表现出色: SWE-bench Pro 目前是衡量人工智能在解决真实 GitHub 问题方面性能的黄金标准。GPT-5.2-Codex 取得了历史性的高分(解决了超过 1000 个问题)。 60% (问题数量),表明它已经超越了“Hello World”阶段,开始修复复杂的生产环境错误。
- 自我提升循环: 根据 Ars TechnicaOpenAI 内部使用 GPT-5.2-Codex 生成训练数据并优化其工具链。这种“AI 训练 AI”的递归改进模型,其迭代速度已远超以往人类的预期。
- 每张系统卡的稳健性: OpenAI 的系统卡在处理“模糊指令”方面取得了显著改进。当需求不明确时,该模型不易产生错误判断,更倾向于提出澄清问题或运用逻辑推理来完善上下文。
深度对比:GPT-5.2-Codex 与 Claude Code
社交媒体上经常被讨论的一个话题是:“GPT-5.2-Codex 和 Claude Code 哪个更好?”
我们从三个维度对它们进行比较:基准数据、用户体验和用例。
| 方面 | GPT-5.2-Codex | 克劳德·科德(3.5首十四行诗/作品) |
| SWE-bench 性能 | S级 在解决涉及多文件依赖关系的复杂错误方面展现出绝对优势。 | A级 性能依然强劲,但处理超长逻辑链时略显吃力。 |
| 用户体验 | “逻辑野兽” 用户报告称,后端架构、算法优化和数学逻辑性能无可挑剔,幻觉极少。 | “更‘人性化’” 开发者普遍认为 Claude 在前端 UI、自然语言交互和一次性代码生成方面表现出更好的“直觉”。 |
| 代码风格 | 严谨而精心设计 倾向于生成“企业级”代码,其中包含详细的注释并严格遵循设计模式。 | 简洁直观 生成高度可读的代码,更适合快速原型开发。 |
| 生态系统整合 | 强大的生态系统 与 GitHub Copilot 和 VS Code 深度集成。 | 高灵活性 在 Cursor 和 Windsurf 等第三方编辑器中表现尤为出色。 |
结论: 如果你的重点是 后端重构、算法实现或大规模系统设计GPT-5.2-Codex 显然是最佳选择。如果您专注于 前端交互或快速原型制作克劳德·科德或许能提供更优质的体验。
实际应用:利用 GPT-5.2-Codex 提升研发效率指南
基于 GPT-5.2-Codex 的工程能力,我们概述了现代软件开发生命周期 (SDLC) 中的三个核心应用场景和标准工作流程。
场景一:系统级重构和技术栈迁移
应用上下文: 管理涉及大量文件更改的技术债务,例如主要框架升级(例如,将 React 类组件迁移到 Hooks)、基础设施标准化(日志规范、安全中间件集成)和死代码清理。
标准工作流程:
- 步骤 1:背景情境化。 通过 IDE 插件或 CI/CD 集成工具授予 GPT-5.2-Codex 对整个 Git 存储库的读取权限,以建立完整的依赖关系索引。
- 步骤 2:约束定义。 输入技术方案文件,以确定重构边界。
- 命令示例: “保持与 V1 API 的向后兼容性。所有数据库操作都必须通过 ORM 层;禁止直接进行 SQL 拼接。”
- 预处理: 请求模型输出 重构计划列出受影响的模块、潜在风险和回滚策略。
- 步骤 3:迭代执行 & 审查.
- 执行: 该模型按模块提交 Pull Request。
- 确认: 触发自动化测试流水线(CI 流水线),并将失败日志反馈给模型进行自动纠正。
- 验收: 最终的代码审查由人工工程师进行,重点在于架构的合理性,而不是语法细节。
场景二:全周期开发和自动化调试
应用上下文: 涵盖功能开发和错误修复,旨在让 AI 处理实现细节,而开发人员则专注于逻辑编排。
实际工作流程:
- 新功能开发(增强型 TDD):
- 分解: 输入产品需求文档 (PRD),并让模型将其转换为技术文档。 任务清单.
- 代码生成: 对于每个任务,请求模型同步生成 业务实现代码 和 高覆盖率单元测试.
- 缺陷修复(根本原因分析):
- 输入: 请提供完整的堆栈跟踪、相关的日志片段和涉及的源文件。
- 分析与修复: 该模型执行跨文件归属分析以定位 根本原因 并生成一个 修补.
- 预防倒退: 强制模型编写回归测试用例,以确保相同的逻辑错误不会再次发生。
效率提升: 开发人员不再将 80% 的精力投入到代码实现上,而是专注于 需求澄清, 建筑决策, 边缘案例回顾, 和 代码审查.
场景 3:前端工程和 UI 代码生成
应用上下文: 适用于快速构建 MVP(最小可行产品)、内部工具开发和高保真度渲染营销页面。
标准工作流程:
步骤1:可视化解析: 输入 Figma 设计截图或预览链接。GPT-5.2-Codex 会解析 DOM 结构、组件层级和布局参数。
步骤2:代码生成:
- 结构层: 生成符合项目标准(例如 React/Vue/Next.js)的组件骨架。
- 表示层: 生成原子 CSS(例如 Tailwind CSS)或相应的 UI 库代码(例如 Chakra UI/Ant Design)。
步骤3:逻辑补全: 开发人员连接后端 API 数据并将交互事件绑定到生成的代码。
效率提升: 显著减少花费在以下方面的时间 样板代码实现了从设计到前端实现的半自动化流程。
安全和实际考虑因素
尽管 OpenAI 的系统卡功能强大,但它也发出了一些企业在实施过程中必须注意的警告:
- 过度自信: 当面对不熟悉的私有框架时,该模型可能会自信地提供错误的代码。
- 安全漏洞: 尽管已经过红队演练,但复杂的 SQL 查询或系统调用中仍然存在注入漏洞的风险。
- 最佳实践: 始终保持 “人机交互” 这种方法。不要让人工智能直接将代码推送到生产环境;人工代码审查仍然是最后一道防线。
GPT-5.2-Codex 的部署标志着软件工程的结构性转变。随着传统代码实现高度自动化,开发人员的核心能力将被重新定义。 系统架构设计 和 技术产品化这意味着开发人员必须从“代码执行者”转变为“技术决策者”,协调人工智能代理来实现复杂的工程目标。
在新常态下 人工智能辅助开发构建完善的智能工具生态系统是提高组织效率的关键:
- 工程交付方: 依靠 GPT-5.2-Codex 解决底层逻辑构建、算法实现和遗留系统重构等硬核技术问题,确保技术基础的稳健性。
- 协作管理方面: 介绍 iWeaver 作为非结构化数据和工作流程的中心枢纽,iWeaver 不仅管理和转换信息,还能打破部门壁垒。iWeaver 帮助技术人员以及运营、市场营销、销售和产品经理等非技术人员完成闭环管理。 意图识别和任务分解,实现智能分配和执行跟踪实现无缝协作 跨职能团队.
常问问题
ChatGPT-5.2-Codex 是什么?
ChatGPT-5.2-Codex 是 OpenAI 专门为高级编程和系统架构而设计的专业化演进版本。其显著特点是: S级逻辑推理它经过精心调整,能够处理长期任务依赖关系、自主代理执行和高级网络安全防御,使其成为复杂后端工程的首选。
iWeaver 如何优化我的工作流程?(即使对于非程序员也适用)
iWeaver 弥合了复杂人工智能功能与直观易用的生产力之间的鸿沟。我们通过以下方式简化技术门槛:
- OpenClaw 工作流程集成iWeaver 让复杂的开源 API 变得简单易懂。它提供了部署的分步指南。 OpenClaw 通过 ChatGPT-5.2-Codex 实现工作流程,从而实现无缝的“需求到代码”自动化周期。
- 动态知识管理支持超过 50多种文件格式 (包括 PDF、原始代码和视频),iWeaver 会对您的数据进行索引,以提供“上下文持久性”,确保 AI 在大型项目中永远不会“丢失线索”。
- 高级提示优化我们的内置助手会将您的随意指示转换成 专家级提示确保每次都能提供高精度、可直接投入生产的产品。
Codex + iWeaver 组合在哪些情况下可以最大限度地提高效率?
这种“情报+基础设施”的协同作用将彻底改变以下方面:
- 从零到一的全栈开发非程序员可以在 iWeaver 中发出业务级指令,让 Codex 生成全栈逻辑,并实时同步所有技术文档。
- 复杂技术栈分析在评估多个技术解决方案时,使用 iWeaver 总结和对比不同的框架,利用多代理协作在几分钟内生成全面的决策报告。
我的数据安全吗?
安全是我们的首要任务。 我们严格遵守隐私保护协议,确保敏感文件(例如法律合同或专有源代码)的端到端加密。此外,您的数据存储在…… 私有专用数据库 并且严格禁止用于训练任何第三方人工智能模型。
iWeaver 支持哪些语言?
iWeaver专为全球员工打造。我们提供全面、原生级别的支持。 英语、中文、法语、意大利语、日语、韩语和德语确保语言障碍不会影响您的工作效率。


