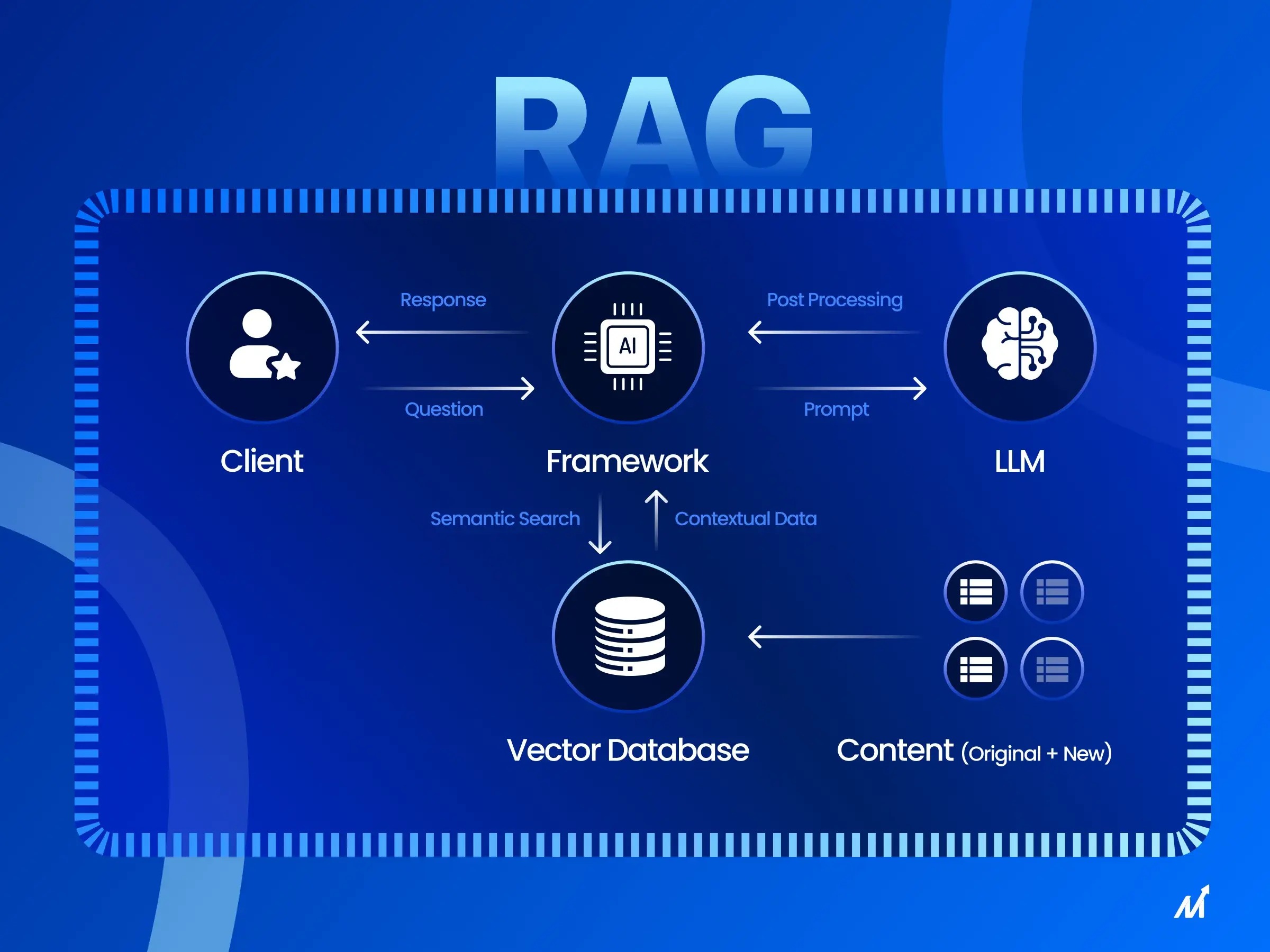
Da Frage-Antwort-Systeme immer fortschrittlicher werden, erforschen Entwickler neue Techniken, um ihre Leistung zu steigern. Ein vielversprechender Ansatz ist das RAG-Modell (Retrieval-Augmented Generation), das Informationsabruf und generative Sprachfunktionen kombiniert. Durch die Feinabstimmung der Einbettung für den Abruf domänenspezifischer Daten haben Forscher einen Weg gefunden, die Antwortgenauigkeit von RAG-Modellen deutlich zu verbessern. Dieser Artikel geht näher auf diese Technik ein.
Einführung in RAG
Um besser zu verstehen, warum die Optimierung von Einbettungen für RAG-Modelle so effektiv ist, müssen wir zunächst einige Hintergrundinformationen zu RAG selbst geben.
Was ist RAG?
RAG steht für Retrieval-Augmented Generation. Es handelt sich um eine Methode, die Informationsabruf mit generativen Modellen kombiniert. Ein RAG-Modell ruft zunächst relevante Informationen ab und generiert dann basierend darauf eine Antwort. Dies verbessert die Fähigkeit des Modells, komplexe Fragen zu beantworten. Es besteht aus zwei Teilen: einem Retriever und einem Generator. Der Retriever extrahiert basierend auf der Frage relevante Ausschnitte aus einem umfangreichen Dokumentenkorpus. Der Generator verwendet diese Ausschnitte dann, um eine schlüssige Antwort zu generieren. Dieser Ansatz eignet sich besser für die Beantwortung von Fragen in offenen Domänen, da er dynamisch die neuesten Informationen abrufen kann.
Vorteile und Einschränkungen von RAG-Modellen
Im Vergleich zu herkömmlichen Textabruf- und generativen Modellen haben RAG-Modelle einige Vorteile:
- Kann genauere und nützlichere Suchergebnisse liefern
- Kann komplexe Abfragen und lange Texte verarbeiten
- Kann personalisierte Suchergebnisse basierend auf der Benutzerabsicht generieren
Allerdings unterliegen RAG-Modelle auch einigen Einschränkungen:
- Training und Inferenz sind rechenintensiv
- Hohe Anforderungen an Trainingsdaten und Modellkapazität
- Schwierigkeiten bei der Bearbeitung von Anfragen und Texten aus Fachdomänen
Die Rolle von Einbettungen in RAG
Nachdem wir die Grundlagen von RAG behandelt haben, wollen wir uns nun damit befassen, wie Einbettungen eine entscheidende Rolle spielen und optimiert werden können.

Erinnern Sie sich an den Vergleich verschiedener Einbettungsmodelle auf Domänendaten
In diesem Experiment wurden mehr als 30.000 Wissensfragmente und 600 Standardbenutzerfragen für den Rückruftest verwendet. Wir verglichen hauptsächlich die Rückrufleistung der Modelle m3e-base, bge-base-zh und bce-embedding-base_v1 anhand chinesischer und englischer Eingabedaten.
Feinabstimmung des Einbettungsmodells auf Domänendaten
- Datenerfassung: Erfassen Sie ausreichend domänenbezogene Daten, darunter Dokumente, Frage-und-Antwort-Paare usw. Diese Daten sollten wichtige Wissenspunkte und häufige Fragen in der Domäne abdecken.
- Vorverarbeitung: Bereinigen und vorverarbeiten Sie die Daten, um Rauschen und Redundanz zu entfernen und so die Datenqualität sicherzustellen.
- Feinabstimmung: Optimieren Sie ein vortrainiertes eingebettetes Modell (z. B. BERT) anhand der Domänendaten. Kontinuierliches Training mit Domänendaten hilft dem Modell, sich besser an die Semantik und den Sprachgebrauch in dieser Domäne anzupassen.
- Auswertung und Optimierung: Bewerten Sie die Leistung des fein abgestimmten Embedding-Modells in RAG und passen Sie die Trainingsparameter und Datensätze nach Bedarf an, um die Leistung weiter zu optimieren.
Durch Feinabstimmung kann das Embedding-Modell die domänenspezifische Semantik besser verstehen, wodurch die Abruf- und Generierungsfunktionen des RAG-Modells verbessert und die Antwortraten und -qualität gesteigert werden.
Am Beispiel des m3e-Modells:
Herunterladen: https://huggingface.co/moka-ai/m3e-base
Referenz zur Feinabstimmung: https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
Nach der Feinabstimmung der Domänendaten und dem erneuten Testen des Rückrufs stellten wir eine direkte Steigerung der Rückrufrate um 33% fest – ein sehr vielversprechendes Ergebnis.
Abschluss
Die Feinabstimmung des Embedding-Modells ist ein effektiver Weg, die RAG-Antwortraten zu verbessern. Durch die Feinabstimmung der Domänendaten kann das Embedding-Modell die domänenspezifische Semantik besser verstehen und so die Gesamtleistung des RAG-Modells steigern. Obwohl RAG-Modelle in der Open-Domain-Qualitätssicherung erhebliche Vorteile bieten, muss ihre Leistung in spezifischen Domänen noch weiter optimiert werden. Zukünftige Forschung könnte weitere Methoden zur Feinabstimmung und Verbesserung der Datenqualität erforschen, um die Antwortgenauigkeit und Benutzerfreundlichkeit von RAG-Modellen domänenübergreifend weiter zu verbessern.


