Bei meinen jüngsten Modellevaluierungen taucht immer wieder eine Frage auf: Kann ein Codierungsagent auch dann schnell, zuverlässig und kostengünstig bleiben, wenn Aufgaben die Bearbeitung mehrerer Dateien, wiederholtes Debuggen und den Einsatz von Werkzeugen umfassen – und nicht nur die Beantwortung einzelner Fragen? MiniMax M2.5 ist eine der wenigen Veröffentlichungen, die mit ausreichend Gesamteffizienz und Preisdetails um diese Frage konkret zu prüfen.
Warum ich der M2.5 meine Aufmerksamkeit schenke
Ich konzentriere mich weniger auf den „besten Benchmark-Wert“ und mehr darauf, ob ein Modell reale Arbeitsabläufe bewältigen kann:
- Komplette Lieferung: Umfang → Implementierung → Validierung → Ergebnisse
- Betriebliche Effizienz: Toolaufruf-Iterationen, Token-Nutzung und Laufzeitstabilität
- Agent Wirtschaft: ob das Preismodell langlaufende Agenten und wiederholte Iterationen unterstützt
MiniMax M2.5 ist interessant, weil es auf Optimierung abzielt. Leistungsfähigkeit, Effizienz und Kosten in der gleichen Version – eine wichtige Kombination für Entwicklungsteams, die über die Bereitstellung entscheiden.
Wofür der M2.5 gebaut wurde
Basierend auf der offizielle Materialien, MiniMax M2.5 ist auf realweltliche Produktivitäts-Workloads in drei Hauptbereichen ausgerichtet:
- Für Softwareentwicklung (Agentencodierung): repräsentiert durch SWE-Bench Verified, Multi-SWE-Bench und einen Schwerpunkt auf stabile Leistung über verschiedene Kabelbäume hinweg.
- Für die interaktive Suche und Werkzeugnutzungeinschließlich BrowseComp, Wide Search und MiniMax's hauseigenem RISE-Benchmark, der eine tiefergehende Erkundung professioneller Webquellen abbilden soll.
- Für mehr Produktivität im Büro: Fokus auf ergebnisorientierte Aufgaben in Word, PowerPoint und Excel, unterstützt durch ein Bewertungsframework (GDPval-MM), das die Ausgabequalität, Agentenausführungsspuren und Tokenkosten berücksichtigt.
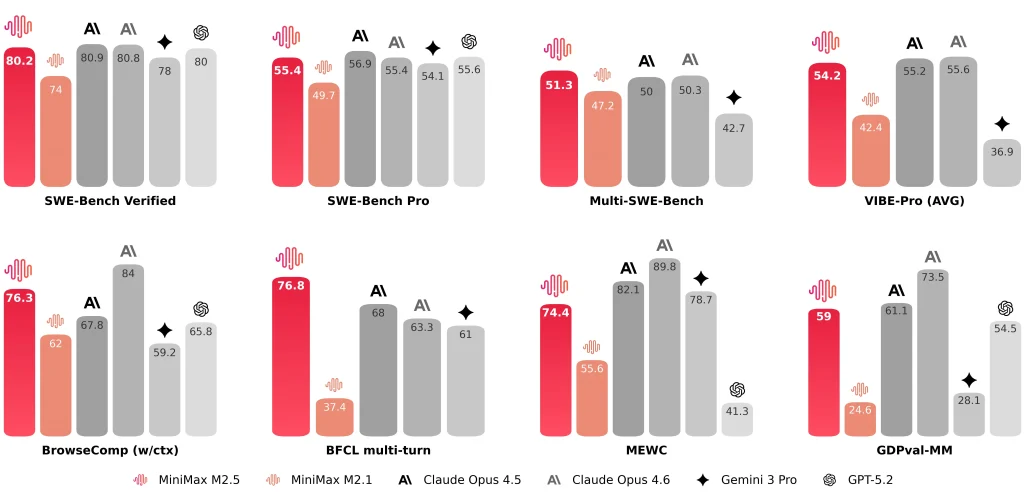
MiniMax veröffentlicht außerdem repräsentative Ergebnisse wie beispielsweise SWE-Bench-verifiziert 80.2%, Multi-SWE-Bench 51.3%, Und BrowseComp 76.3%.
MiniMax M2.5 vs. M2.1 und Claude Opus 4.6: Mein Vergleich
M2.5 vs M2.1 vs Claude Opus 4.6 (Tabelle der wichtigsten Kennzahlen)
| Dimension | M2.5 | M2.1 | Claude Opus 4.6 |
| SWE-Bench-verifiziert | 80.20% | 74.0% | 81.42% (Anthropologische Daten) ~78-80% (Öffentlicher Durchschnitt) |
| Durchschnittliche Gesamtzeit pro SWE-Aufgabe | 22,8 Min. | 31,3 Min. | 22,9 Min. |
| Tokens pro SWE-Aufgabe (Durchschnitt) | 3,52 Mio. | 3,72 Mio. | — (Wahrscheinlich >4M aufgrund der Ausführlichkeit) |
| Such-/Werkzeugiterationen im Vergleich zur vorherigen Generation | ~20% weniger Iterationen (gemeldet) | Ausgangswert | — |
| Cross-harness SWE-Bench (Droid) | 79.7 | 71.3 | 78.9 |
| Cross-harness SWE-Bench (OpenCode) | 76.1 | 72.0 | 75.9 |
| Durchsatzoptionen | ~50 Token/s (Standard) ~100 Token/s (Blitz) | ~57 Token/s | ~67-77 Token/s |
| Preisgestaltung (pro 1 Million Input-Token) | $0.3 (Standard & Lightning) | $0.3 | $5.0 |
| Preisgestaltung (pro 1 Million Output-Token) | $1.2 (Standard) $2.4 (Lightning) | $1.2 | $25.0 |
| Stündliche Intuition (kontinuierliche Ausgabe) | ~$0,3/Std. bei 50 t/s ~$1/Std. bei 100 t/s | ~$0,3/Std. bei 57 t/s | ~$6,50/Std. bei 70 t/s |
Anmerkungen:
- „—“ bedeutet, dass der Wert in den hier zusammengefassten Unterlagen nicht angegeben wurde.
- Benchmarks können je nach Testumgebung, Werkzeugkonfiguration, Eingabeaufforderungen und Berichtskonventionen variieren, daher behandle ich sie als Bereichsanzeigen, keine absoluten Ranglisten.
M2.5 vs M2.1: Schnellere End-to-End-Verarbeitung, geringerer Tokenverbrauch, weniger Suchiterationen
Der offizielle Vergleich wird in einer für Ingenieure verständlichen Weise präsentiert. Ich achte dabei auf drei spezifische Kennzahlen:
- End-to-End-Laufzeit: Die durchschnittliche Bearbeitungszeit für Softwareentwicklungsaufgaben sinkt von 31,3 Minuten (M2.1) Zu 22,8 Minuten (M2,5), beschrieben als 37% Verbesserung.
- Token pro Aufgabe: Der Tokenverbrauch pro Aufgabe sinkt von 3,72 Mio. Zu 3,52 Mio..
- Effizienz der Such-/WerkzeugiterationBei BrowseComp, Wide Search und RISE erzielt MiniMax bessere Ergebnisse mit weniger Iterationen, wobei die Iterationskosten ungefähr 20% untere als M2.1.
Für mich sind diese Verbesserungen wichtiger als ein einzelner Benchmark-Wert, weil sie direkt bestimmen Agentendurchsatz Und nachhaltige Betriebskosten.
M2.5 vs Claude Opus 4.6: Ähnlicher Kodierungsbereich, der Bewertungskontext ist entscheidend
Beim Vergleich M2.5 mit Claude Opus 4.6Ich behandle Punktzahlen als Bereiche und nicht absolute Ranglisten, da sich Benutzerhandbücher, Werkzeugkonfigurationen, Eingabeaufforderungen und Berichtskonventionen unterscheiden können.
- Anthropisch stellt fest, dass Opus 4.6 wurde im SWE-Benchmark-Test verifiziert. Das Ergebnis ist ein Durchschnitt über 25 Versucheund erwähnt einen höheren beobachteten Wert (81,42%) unter sofortigen Anpassungen.
- MiniMax-Berichte SWE-Bench-verifiziert 80.2% für MiniMax M2.5.
Numerisch betrachtet scheinen die beiden in einem ähnlichen Wettbewerbsbereich für Coding-Agent-Benchmarks zu liegen. Aus technischer Sicht ist mir die Stabilität über reale Projektstrukturen hinweg – Frontend + Backend, verschiedene Scaffolds und Integrationen von Drittanbietern – wichtiger als eine einzelne Kennzahl.
Wie M2.5 meinen Workflow verändert (Praxisnotizen)
Geschwindigkeit und Workflow-Stil
Nach der Integration MiniMax M2.5 Bei der Betrachtung einer Coding-Agent-Toolchain fallen zwei Dinge besonders auf:
- Die Geschwindigkeit von MiniMax M2.5 verbessert die Iteration kurzer Aufgaben deutlich.Viele reale Aufgaben folgen dem Schema „kleine Änderung → Ausführung → Anpassung“. Wenn jede Schleife lange Wartezeiten verursacht, wird der Kontextwechsel kostspielig. MiniMax hebt explizit „schnellere End-to-End-Prozesse“ und „geringeren Tokenverbrauch“ als zentrale Ergebnisse hervor.
- MiniMax M2.5 neigt dazu, vor der Implementierung eine Spezifikation zu schreiben.Bei Aufgaben mit mehreren Dateien und Modulen bevorzuge ich ein Modell, das Bereichsgrenzen, Modulbeziehungen und Akzeptanzkriterien explizit vor dem Schreiben des Codes erfasst. Dadurch lässt sich die Ausführung leichter überprüfen und standardisieren, und M2.5 funktioniert mit dieser Struktur einwandfrei.
Diese Punkte sollten nicht übersehen werden.
Selbst bei einer insgesamt guten Leistung betrachte ich die folgenden Punkte dennoch als Einschränkungen, die Arbeitsablauf-Leitplanken erfordern:
- Die Debugging-Strategie ist nicht immer proaktiv.Bei schwer lokalisierbaren Fehlern kann das Modell die Implementierung wiederholt ändern, ohne automatisch auf Unit-Tests, Protokollierung oder minimale Reproduktionsschritte umzuschalten. Ich muss oft explizit anweisen: „Füge Protokolle hinzu / schreibe Tests / grenze den Fehlerpfad ein.“
- Externe Datenabfragen und die Integration von Drittanbietern können unzuverlässig sein.Bei der Integration bestimmter externer Dienste kann das Modell fehlerhafte Integrationsschritte erzeugen. Ich bevorzuge es, Eingaben anhand von Beispielen aus der offiziellen Dokumentation zu beschränken, anstatt mich auf automatisch generierten Code zu verlassen.
- Die Synchronisierung von Code und Dokumentation ist nicht durchgängig standardmäßig.Wenn eine Aufgabe die Aktualisierung des Codes sowie der Dokumentation/des Skill-Markdowns erfordert, verwende ich eine explizite Checkliste, um die Wahrscheinlichkeit zu verringern, dass nur der Code aktualisiert wird.
Diese Einschränkungen gelten nicht nur für M2.5; es handelt sich um Leitplanken, die ich bei den meisten Coding-Agent-Workflows anwende.
In dieser Phase positioniere ich mich MiniMax M2.5 als Ingenieurorientiertes agentenbasiertes ProduktivitätsmodellEs liefert nicht nur Benchmark-Ergebnisse, sondern legt auch die Laufzeit bis zum Ende, den Token-Verbrauch, die Iterationseffizienz und die Preisstruktur offen, wodurch ich die tatsächlichen Bereitstellungskosten anhand eines einheitlichen Satzes von Metriken bewerten kann.
Manche Nutzer könnten sich fragen, ob die Erstellung einer Spezifikation vor der Codierung die Tokenkosten erhöht und die Behauptung der „niedrigen Kosten“ untergräbt. Meine praktische Schlussfolgerung lautet:
- Ja, das Schreiben einer Spezifikation fügt einige Ausgabetoken hinzu.
- In vielen realen Arbeitsabläufen werden diese Kosten durch weniger Nachbearbeitungsschleifen und weniger Hin- und Her-Iterationen kompensiert.insbesondere für Aufgaben mit mehreren Dateien, modulübergreifenden Aufgaben oder hohem Debugging-Aufwand.
- Der Mehraufwand ist in der Regel kontrollierbar, solange die Spezifikation nicht übermäßig lang ist und keine Implementierungsdetails wiederholt.
Hier sind einige praktische Tipps zur Minimierung des Overheads für Spec-Token:
- Für kleine Aufgaben: explizit anfordern „keine Spezifikation; stattdessen Code-Diff und Testschritte bereitstellen“.
- Für mittelgroße/große Aufgaben: die Spezifikation einschränken auf X Linien / X Punkte (z. B. 10–15), wobei der Fokus ausschließlich auf Struktur und Akzeptanzkriterien, nicht Implementierungsdetails.
- In Agenten-Toolchains: Behandle die Spezifikation als die einzige Quelle der WahrheitAktualisieren Sie bei sich ändernden Anforderungen zuerst den entsprechenden Abschnitt der Spezifikation, bevor Sie mit der Codierung und Validierung fortfahren. Dadurch werden wiederholte Erklärungen und unnötiger Code durch die erneute Kontextualisierung vermieden.