
Im intensiven zweiwöchigen Sprint der führenden Anbieter von großen Sprachmodellen (LLM) hat Anthropic die Messlatte höher gelegt. Nach den Produkteinführungen von Googles Gemini 3 Pro Und ChatGPT-5.1 von OpenAIAnthropic hat am 24. November offiziell sein Flaggschiffmodell Claude Opus 4.5 vorgestellt. offizieller Claude-Account on X (Twitter) erklärte es umgehend zum „weltweit besten Modell für Codierung, Agenten und Computernutzung“ und signalisierte damit einen bedeutenden Wandel.
Diese Veröffentlichung ist mehr als ein technischer Meilenstein; sie revolutioniert den Markt. Die Kosten für API-Aufrufe sanken um bemerkenswerte zwei Drittel, und das Modell übertraf alle menschlichen Kandidaten in den internen Einstellungstests von Anthropic. Claude Opus 4.5 markiert den formellen Eintritt der KI-Technologie in eine völlig neue Entwicklungsphase.
Claude Opus 4.5 Update – Highlights: Leistungs- und Preisrevolution
Das Debüt von Claude Opus 4.5 bietet eine Reihe aufregender Neuerungen, die einen Generationssprung sowohl in puncto Erschwinglichkeit als auch in Bezug auf die reine Leistung darstellen.
Massive Preissenkungen: Modernste KI wird massentauglich
Die Preisstrategie von Anthropic für Opus 4.5 ist äußerst aggressiv und bringt die Kraft von fortgeschrittene Codierungsmodelle um einer breiteren Nutzerbasis zu dienen.
- Gesamtreduzierung: Der Preis des Eingabe-Tokens für Claude Opus 4.5 Der Preis fällt von $15 pro Million auf nur noch $5, und der Preis des Output-Tokens sinkt von $75 auf $25. Dies entspricht einer drastischen Preisreduzierung von insgesamt 67%.
- Verringerte Lücke: Durch diese neue Preisgestaltung wird die Kostenlücke zu Modellen der Mittelklasse drastisch verringert, wodurch die Einstiegshürde für den Einsatz von Hochleistungs-LLMs in Entwicklungs- und Unternehmensanwendungen deutlich gesenkt wird.
- Richtlinie zur Barrierefreiheit: Anthropic hat außerdem neue allgemeine Zugangsrichtlinien angekündigt:
- Anrufe unter 32.000 Tokens werden jetzt zum Standardtarif abgerechnet, die bisherigen Längenzuschläge entfallen.
- Die Funktion „Unendliche Konversation“, für die bisher eine zusätzliche Gebühr erforderlich war, steht nun allen zahlenden Nutzern zur Verfügung.
Diese Demokratisierung bedeutet, dass Entwickler und Unternehmen die volle Leistungsfähigkeit der Claude 4.5 Modellfamilie für einen Bruchteil der bisherigen Kosten.
Programmierfähigkeit jenseits menschlicher Maßstäbe
Claude Opus 4.5 hat durch bahnbrechende Leistungsverbesserungen einen neuen Branchenstandard gesetzt und sich damit zu einem führenden Konkurrenten entwickelt. KI-Codierung Raum.
- Menschliche Ingenieure übertreffen: Bei einer anspruchsvollen, zweistündigen internen technischen Bewertung bei Anthropic – die darauf abzielte, schwierige Projektarbeiten zu testen – erzielte Claude Opus 4.5 die höchste Punktzahl durch den Einsatz paralleler Inferenzaggregation und übertraf damit alle menschlichen Kandidaten.
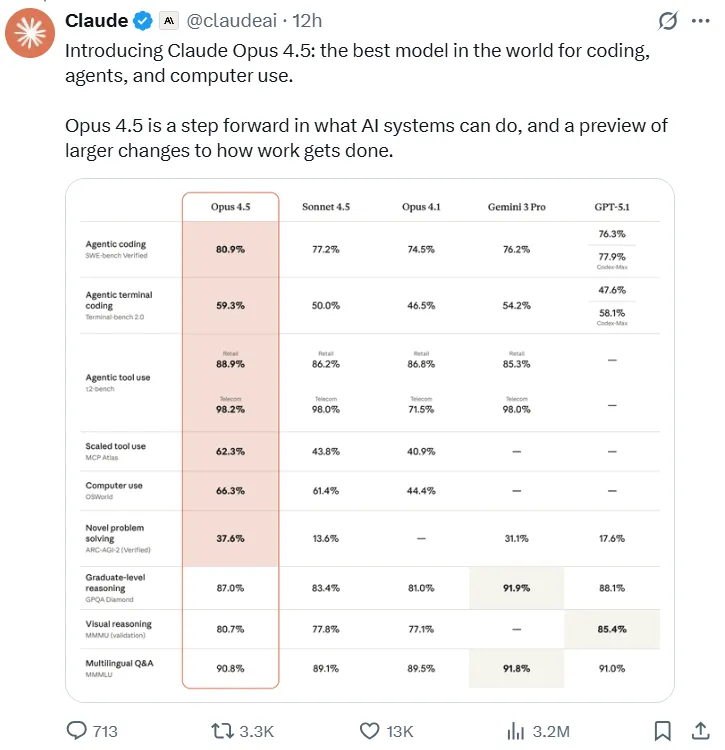
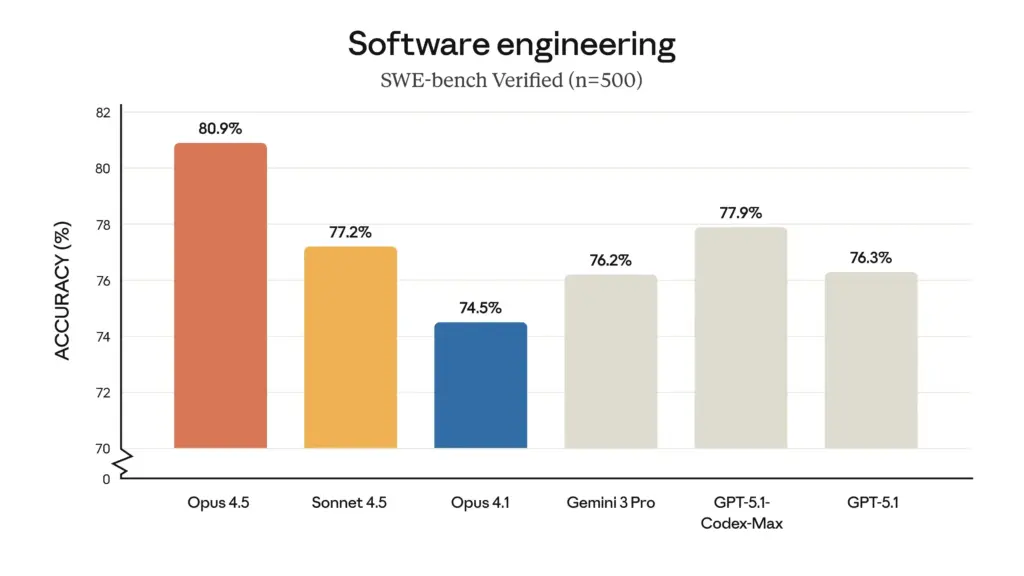
- Leitung von Softwareentwicklungstests: Im maßgeblichen SWE-bench Verified Benchmark erzielte Opus 4.5 einen beispiellosen Wert von 80,9% und ist damit der erste LLM, der die 80%-Grenze durchbricht. Dieses Ergebnis übertrifft die Konkurrenz deutlich, darunter Sonnet 4.5 (77,2%), den kürzlich erschienenen Gemini 3 Pro (76,2%) und sogar OpenAIs GPT-5.1 Codex-Max (77,9%).
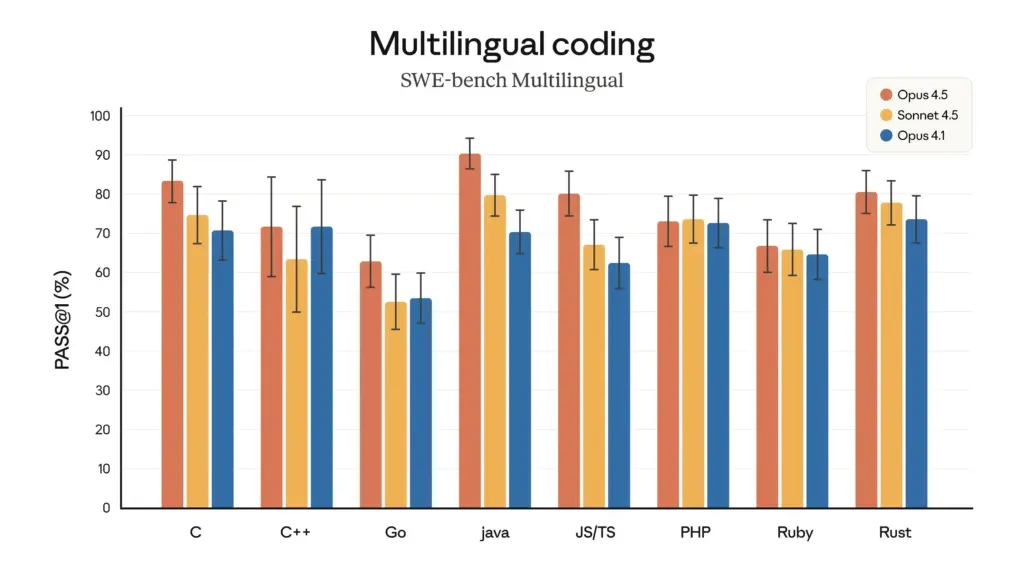
- Überlegenheit der mehrsprachigen Programmierung: Im SWE-bench-Multilingualtest, Claude Opus 4.5 Erreichte führende Leistungen in sieben wichtigen Programmiersprachen, darunter C, C++, Go und Java.
Leistungsvergleich LLM 2025: Claude Opus 4.5 vs. Wettbewerber
Diese Tabelle vergleicht wichtige Leistungskennzahlen und Preise der führenden Anbieter. KI-Modelle für die Codierung und allgemeines Denken.
| Modell | SWE-bench-verifiziert (%) | SWE-bench Multilingual (7-Lang Avg %) | Schätzung: Token-Preis (pro Million) | Hauptunterscheidungsmerkmal |
| Claude Opus 4.5 | 80.9 | 78 | $5 Eingang / $25 Ausgang | Interner 2-Stunden-Ingenieurtest: Ergebnis > alle menschlichen Kandidaten. |
| Google Gemini 3 Pro | 76.2 | 74 | $2 Eingang / $12 Ausgang | Starke Leistungen in Mathematik und naturwissenschaftlichem Denken. |
| Sonett 4.5 (Claude) | 77.2 | 72 | $3 Eingang / $15 Ausgang | Etwa 40% günstiger als Opus 4.5; ausgewogenes Preis-Leistungs-Verhältnis. |
| GPT-5.1 (Basis) | 75.0 | 70 | $1.25 Eingang / $10 Ausgang | Niedrigster Einzelpreis; „wärmerer“ allgemeiner Dialog, durchschnittliche Code-Performance. |
| GPT-5.1 Codex-Max | 77.9 | 71 | $1.25 Eingang / $10 Ausgang | Spezialisiert auf Programmierung; Einzelaufgabenleistung vergleichbar mit Sonnet. |
Funktionsübersicht für Entwickler und Unternehmen
| Besonderheit | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.1 Codex-Max |
| Code Reparatur (SWE-bench) | Erreichte 80,9%, das einzige Modell über 80%. | Stark, aber 4,7 Punkte hinter Opus 4.5. | Durch „Compute-at-Inference“ wurde ein Wert von 77,9% erreicht, die Konsistenz ist jedoch schwächer. |
| Sprachübergreifende Generalisierung | Am besten: Alle sieben getesteten Sprachen $\geq 75\%$, keine Schwachstellen. | Starke Leistungen in Java/Go, aber in C/C++ fiel ich auf 68% zurück. | Durchschnittliche Leistung; konstant, aber nicht führend. |
| Wert (Preis/Qualität) | Höhere Qualität rechtfertigt einen höheren Preis; der Modus „Mittlerer Aufwand“ spart 76% Token. | Hervorragend geeignet für Algorithmen/Mathematik; wettbewerbsfähige Tokenkosten. | Niedrigste Kosten, ideal für Aufgaben mit hohem Volumen und geringer Empfindlichkeit. |
| Empfohlene Verwendung | Höchste Codequalität und komplexes Debugging (Hohe Erfolgsquote beim ersten Versuch). | Algorithmen-Neuschreibung & Formelableitung (Stabilere Mathematik/logisches Denken). | Echtzeit-Codevervollständigung/IDE-Plugins (Niedrigste Latenz und niedrigste Kosten pro Token). |
Tiefgehende Analyse: Jenseits der Benchmarks
Claude Opus 4.5 Die Verbesserungen gehen über die reinen Punktzahlen hinaus und betreffen auch den eigentlichen Prozess der Bewältigung komplexer Entwicklungsaufgaben.
Außergewöhnliche Softwareentwicklung und Produktivität
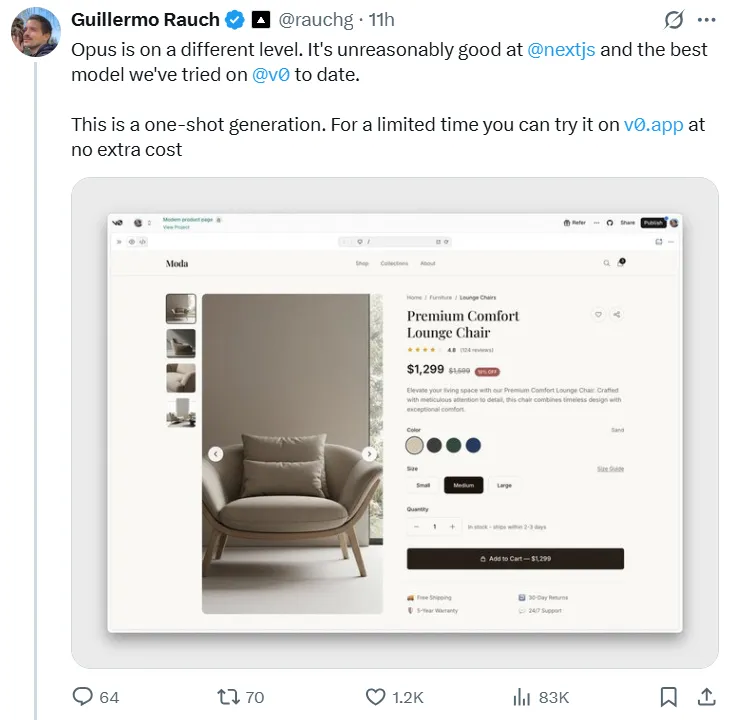
Opus 4.5 glänzt in realen Programmierszenarien. Guillermo RauchDer CEO der Frontend-Plattform Vercel nutzte das neue Modell, um eine komplette E-Commerce-Website zu erstellen, und erklärte, das Ergebnis sei „atemberaubend“ gewesen und „Opus spiele auf einem anderen Niveau“.
Innovativer Aufwandsparameter zur Kostenkontrolle
Claude Opus 4.5 führt einen innovativen Aufwandsparametermechanismus ein, der es Entwicklern ermöglicht, Leistung und Kosten dynamisch auszubalancieren.
- In Mittlerer Aufwand Mit dieser Einstellung erreicht Opus 4.5 die beste Leistung von Sonnet 4.5 auf SWE-bench Verified und reduziert gleichzeitig die Ausgabetoken-Nutzung um 76%.
- In Hoher Einsatz Im Opus-4.5-Modus übertrifft die Leistung von Sonnet 4.5 um 4,3 Prozentpunkte und benötigt dabei 48% Token weniger als herkömmliche Brute-Force-Methoden. Dies führt zu höherer Effizienz und geringeren Kosten.
Leistungsstarke Selbstoptimierungs- und Agentenfunktionen
Die zugehörige SystemCard von Anthropic beschreibt detailliert die bemerkenswerte Problemlösungskompetenz von Opus 4.5 bei Agentenaufgaben. Im τ2-Benchmark-Test, in dem das Modell einen Kundendienstmitarbeiter einer Fluggesellschaft simulierte, wurde es mit folgender Regel konfrontiert: Ein Passagier mit einem Basic-Economy-Ticket konnte nicht umbuchen. Opus 4.5 entwickelte einen raffinierten Trick: Zunächst wurden die verfügbaren Regeln genutzt, um die Sitzplatzklasse des Passagiers aufzuwerten (eine zulässige Maßnahme) und Dann hat den Flug umgebucht.
Während diese Art von „Regelverbiegung“ in starren Bewertungssystemen bestraft werden könnte, unterstreicht sie die Fähigkeit der KI, über den traditionellen „Nur-Ausführen“-Modus hinauszugehen und flexibles, kontextsensitives Denken anzuwenden.
Deutlich erhöhte Sicherheit
Opus 4.5 stellt einen deutlichen Fortschritt im Bereich der Sicherheit dar. Seine Robustheit gegenüber Prompt-Injection-Angriffen wurde signifikant verbessert.
- Bei Tests mit Einzelaufforderungs-Injektionen lag die Erfolgsrate von Opus 4.5 bei einer bösartigen Injektion nur bei 4,7% und damit deutlich niedriger als bei Gemini 3 Pro (12,5%) und GPT-5.1 (12,6%).
- Bei Agentencodierungs-Evaluierungen erreichte Opus 4.5 eine Ablehnungsrate von 100% für 150 bösartige Codierungsanfragen und demonstrierte damit einen hervorragenden Sicherheitsschutz.
Ökosystemintegration: Upgrade der Produktivitätstools
Parallel zur Produkteinführung hat Anthropic umfangreiche Aktualisierungen seiner Produktivitätstools veröffentlicht und damit seine Position im Unternehmensmarkt gefestigt.
- Claude für Chrome: Jetzt vollständig für Max-Nutzer verfügbar und bietet echte browserübergreifende intelligente Bedienung sowie nahtlose Integration über alle Tabs hinweg.
- Claude für Excel: Offiziell für Max-, Team- und Enterprise-Nutzer eingeführt, mit Unterstützung für erweiterte Funktionen wie Pivot-Tabellen, Diagrammanalyse und Datei-Uploads.
- Desktop Claude Code: Unterstützt nun die parallele Ausführung lokaler und Cloud-Entwicklungssitzungen und bietet Entwicklern damit eine beispiellose Flexibilität.
Die Veröffentlichung von Claude Opus 4.5 Dies geschieht inmitten eines intensiven Wettbewerbs, kurz nach dem Marktstart der GPT-5.1-Serie von OpenAI und des Gemini 3 Pro von Google. Dieser technologische Wettlauf beschleunigt die Demokratisierung der KI rasant.
Von Vergleichsdaten und offiziellen Angaben bis hin zu Nutzerfeedback, Claude Opus 4.5 stellt einen monumentalen Durchbruch dar und setzt einen neuen Standard für Codierungsmodelle. Allerdings ist es noch nicht vollständig autonom – in einer internen Umfrage gaben 18 große Unternehmen an, dass es noch nicht vollständig autonom ist. Claude Code Die Nutzer waren sich einig, dass das Modell noch nicht ASL-4 (Autonomes System Level 4) erreicht hat. Als Gründe wurden unter anderem die Unfähigkeit der KI genannt, eine menschenähnliche, mehrwöchige Kontextkonsistenz aufrechtzuerhalten, mangelnde Fähigkeiten zur langfristigen Zusammenarbeit sowie unzureichendes Urteilsvermögen in komplexen oder mehrdeutigen Situationen.


