
Am 27. Januar veröffentlichte DeepSeek OCR 2 als Open-Source-Modell. Nach der Analyse ihrer Technischer BerichtIch glaube, dies stellt einen systematischen Wandel im Umgang von KI mit visuellen Daten dar. Anstatt einfach die Anzahl der Parameter zu erhöhen, konzentrierte sich DeepSeek auf grundlegende architektonische Änderungen, um die Leistung über die Grenzen traditioneller Bildverarbeitungsmodelle (VLMs) hinaus zu verbessern.
DeepSeek OCR 2 ist mehr als nur Texterkennung.
DeepSeek OCR 2 ist ein Bildverarbeitungsmodell der nächsten Generation mit 3 Milliarden Parametern. Es unterscheidet sich deutlich von traditionellen Werkzeugen wie Tesseract oder einfachen visuellen Modellen. OCR 2 verfolgt zwei spezifische Ziele:
- Richtige Lesereihenfolge: Es sorgt für die korrekte Reihenfolge von mehrspaltigem Text, Fußnoten und dem Verhältnis zwischen Überschriften und Fließtext.
- Stabile Layoutstruktur: Es stellt sicher, dass Tabellen, Listen und gemischte Inhalte in verwendbare Strukturen formatiert werden.
Wenn Sie PDF-Scans für die Datenbankeingabe verarbeiten, Daten für RAG-Systeme bereinigen oder komplexe Finanzberichte analysieren müssen, bietet OCR 2 ein hohes Maß an Genauigkeit und logischer Rekonstruktion.
Architektonische Innovation: Warum ist DeepSeek OCR 2 so effizient?
Ersetzen von CLIP durch ein Sprachmodell
Die meisten älteren visuellen Modelle verwenden CLIP als Bildverarbeitungskomponente. CLIP wurde entwickelt, um Bilder mit Textbeschriftungen abzugleichen. Es fehlt ihm jedoch die Fähigkeit, die logischen Zusammenhänge zwischen verschiedenen Teilen eines komplexen Dokuments zu verstehen.
DeepSeek Lösung: Sie benutzten Qwen2-0,5B (eine LLM-basierte Architektur) als Kern des Bildcodierers.
Der Vorteil: Da der Encoder auf einem Sprachmodell basiert, verfügen die visuellen Token bereits in der Anfangsphase über eine grundlegende Schlussfolgerungsfähigkeit. Das Modell kann erkennen, welche Pixel zu einem Header und welche zu einer Tabellengrenze gehören, was eine präzisere Datenverarbeitung ermöglicht.
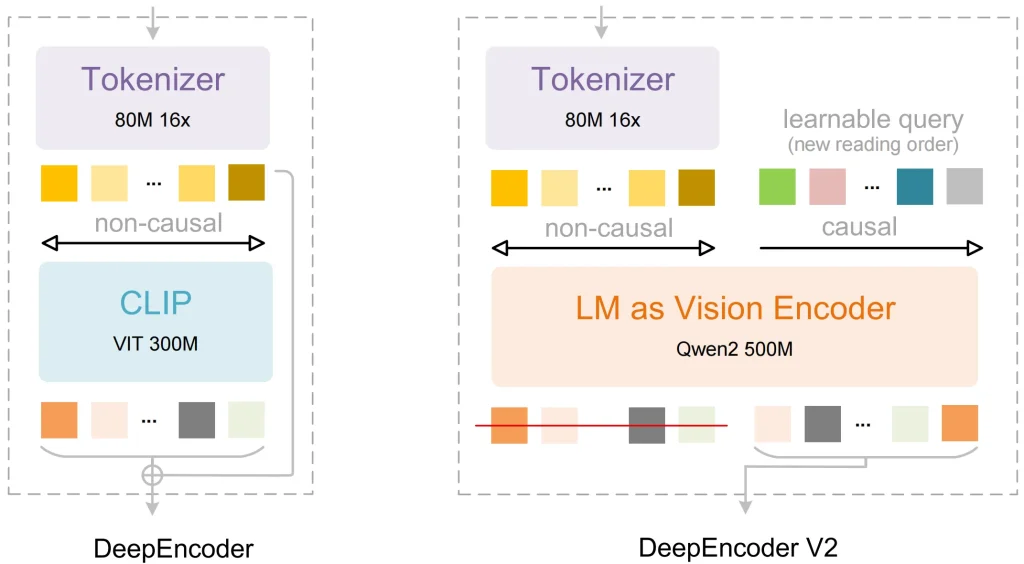
DeepEncoder V2 und Visual Causal Flow
Dies ist der bedeutendste technische Durchbruch in OCR 2. Viele Modelle verarbeiten Bilder in einem festen Raster von links oben nach rechts unten. Diese feste Reihenfolge führt häufig zu Fehlern, wenn das Modell auf komplexe Tabellen oder mehrspaltige Seiten trifft.
DeepSeek Lösung: Sie fügten hinzu Visueller Kausalzusammenhang zur DeepEncoder V2-Komponente:
- Das Modell erfasst zunächst die globalen Informationen der gesamten Seite.
- Es verwendet lernbare Abfragen, um die visuellen Token neu anzuordnen.
- Es sendet diese logisch organisierte Sequenz an den Decoder, um Text zu generieren.
Dadurch kann das Modell Informationen auf Grundlage der tatsächlichen Bedeutung der Daten erfassen. Da die Informationen bereits während der Kodierungsphase nach Layout und Semantik organisiert werden, ist das Endergebnis sehr stabil.
| Metrisch | Traditionelle OCR-Modelle | DeepSeek OCR 2 |
| Lesereihenfolgefehler | Hoch (hat Schwierigkeiten mit Säulen) | Deutlich niedriger (Editierdistanz sank auf 0,057) |
| Token-Komprimierung | Niedrig (Tausende von Token pro Seite) | Sehr hoch (256 – 1120 Token pro Seite) |
| Stabilität/Genauigkeit | Neigt zu Wiederholungen oder Fehlern | Genauigkeit des 97% (bei 10-facher Kompression) |
Visuelle Kodierung hin zu logischem Denken
Experten bezeichnen OCR 2 als einen „sprachmodellgesteuerten Bildcodierer“. Das bedeutet, dass sich der Codierer auf räumliche Beziehungen und Strukturinformationen konzentriert, anstatt nur grundlegende visuelle Merkmale zu extrahieren.
Die Ergebnisse:
Im professionellen OmniDocBench-Test v1.5 erzielte OCR 2 einen Wert von 91,09 Punkten. Dies entspricht einer Verbesserung um 3,73 Punkte gegenüber der Vorgängerversion. Der größte Fortschritt wurde bei der Genauigkeit der Lesereihenfolge und der Verarbeitung komplexer Layouts erzielt.
So verwenden Sie DeepSeek OCR 2: 3 schnelle Bereitstellungsmethoden
DeepSeek hat die Modellgewichte für Hugging Face veröffentlicht. Sie können das Modell für Produktion oder Forschungszwecke auf diese drei Arten nutzen:
Methode 1: Schnelles Feintuning über Unsloth(Empfohlen)
Unsloth ist für OCR 2 optimiert und reduziert den Speicherverbrauch deutlich.
from unsloth import FastVisionModel import torch # Load the model model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # Use 4-bit quantization to save memory ) # Prompt template prompt = " Bitte konvertieren Sie dieses Dokument in Markdown und extrahieren Sie alle Tabellen.Methode 2: Hochleistungsfähige Inferenz mit vLLM
Dies ist die beste Wahl für Organisationen, die viele Anfragen gleichzeitig bearbeiten müssen.
- Einstellungen: DeepSeek empfiehlt die Einstellung
Temperaturauf 0,0 für die konsistentesten Ergebnisse. - Sprachunterstützung: Sie können die Zielsprache in der Eingabeaufforderung angeben. Es werden über 100 Sprachen unterstützt.
Methode 3: Standard-Umarmungsgesicht-Transformatoren
Für maximale Flexibilität verwenden Sie die Standardbibliothek:
- Installieren Sie die erforderlichen Komponenten:
pip install transformers einops addict easydict. - Modell laden:
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", trust_remote_code=True).
Tipp: Bei der Verarbeitung von geneigten Scans kann eine Drehung des Bildes um nur 0,5 Grad zur Begradigung dazu beitragen, dass das Modell noch bessere Ergebnisse liefert.
Aus meiner langjährigen Beobachtung der KI-Branche geht hervor, dass DeepSeek stets als Vorreiter bei der Optimierung von Kernalgorithmen agiert hat. Ich stellte fest, dass ihre erstes OCR-Modell Im Oktober 2025 wurde bereits die Tokenkomprimierung zur Effizienzsteigerung eingesetzt.
OCR 2 ist nicht nur eine Leistungsverbesserung. Es stellt einen grundlegenden Wandel in der Art und Weise dar, wie KI visuelle Logik verarbeitet. Durch die Verwendung einer Sprachmodellarchitektur für die visuelle Kodierung hat DeepSeek die Tiefe des KI-Verständnisses komplexer Daten deutlich erhöht. Ich bin überzeugt, dass diese Bemühungen ein hohes Maß an Weitsicht beweisen. Diese Methode der Informationsorganisation auf der grundlegenden Ebene ermöglicht es der KI, Daten ähnlicher wie die menschliche Logik zu lesen, und setzt einen neuen Standard für die präzise Datenextraktion der Zukunft.


