
On March 4, 2026, Google officially introduced the latest addition to the Gemini 3 series—Gemini 3.1 Flash-Lite. Designed specifically for high-concurrency developer workloads and enterprise-scale deployment, this model is optimized for maximum speed and cost-effectiveness. Based on an analysis of official technical documentation and third-party evaluation data, this report outlines the model’s core performance, costs, and real-world application metrics.
Performance and Core Benchmark Results
Gemini 3.1 Flash-Lite has demonstrated significant technical competitiveness across several mainstream AI benchmarks. According to data from the Arena.ai leaderboard, the model achieved an Elo rating of 1432. In the GPQA Diamond test, which measures expert-level reasoning, it attained an accuracy of 86.9%, while scoring 76.8% in the MMMU Pro test for multimodal understanding.
The data indicates that Gemini 3.1 Flash-Lite’s overall capabilities not only surpass other models in its tier but also outperform the previous generation’s larger Gemini 2.5 Flash across multiple indicators. This performance leap allows developers to achieve higher logical processing power while maintaining low resource consumption.
Competitive Landscape: Cross-Generational and Peer Comparison
In the 2026 small-model market, Gemini 3.1 Flash-Lite competes primarily with GPT-5 mini Und Claude 4.5 Haiku. A direct comparison with its predecessor, Gemini 2.5 Flash, further illustrates its technical evolution:
| Metrisch | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | GPT-5 mini | Claude 4.5 Haiku |
| Output Speed | ~363-384 tokens/s | ~150-200 tokens/s | ~71 tokens/s | ~108 tokens/s |
| Zeit bis zum ersten Token (TTFT) | Fastest | Ausgangswert | Slower | Medium |
| Output Price (/1M) | $1.50 | $0.60 | $2.00 | $5.00 |
| SimpleQA Accuracy | 43.30% | 28.50% | 9.50% | 5.50% |
| Kontextfenster | 1 Million tokens | 1 Million tokens | 400k tokens | 200.000 Token |
The metrics show that while Gemini 3.1 Flash-Lite is priced higher than 2.5 Flash, its output speed has increased by approximately 45%, and the Time to First Token (TTFT) has been reduced to 40% of the previous baseline.
The Logic of Cost-Efficiency: Price-to-Token Complexity Ratio
While community discussions have noted the price increase for the Gemini 3 Flash series, focusing solely on token unit price lacks complete context. The core metric for model selection is the ratio of price to token complexity.
For instance, in other industry models, while Sonnet 5 may have a lower unit price, it might require significantly more tokens than Opus 4.6 to achieve the same result for complex tasks, leading to a higher actual total cost. The advantage of Gemini 3.1 Flash-Lite lies in its information density and execution efficiency per token. For developers, choosing a model should involve more than just benchmarks and token prices; it should focus on whether the model provides a tangible upgrade to the specific workflow.
Community Feedback and Real-World Visual Performance
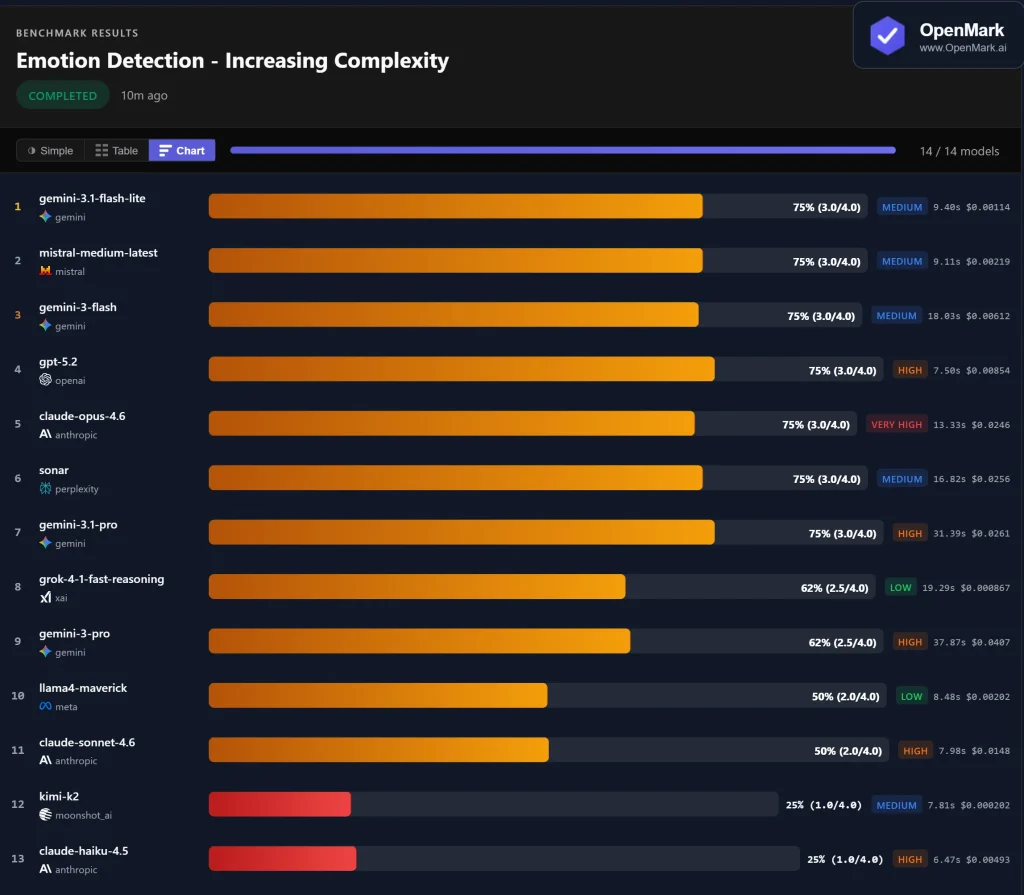
In practical applications, several users have already completed large-scale deployments of the model. In a visual benchmark test for human emotion detection involving 14 large models, Gemini 3 Flash ranked first based on a comprehensive evaluation of accuracy, response speed, and token consumption. This result validates its stability in handling complex multimodal inputs.
Early adopters such as Latitude, Cartwheel, and Whering report that the model remains stable in long-context processing and instruction following. In the e-commerce sector, it is being used to generate dynamic dashboards based on real-time data, while in the SaaS industry, it powers intelligent agents capable of executing multi-step tasks.
Despite its strengths, certain challenges have been identified by the community. Gemini 3.1 Flash-Lite tends toward verbosity, which may result in higher-than-expected output tokens in specific scenarios, thereby increasing costs. Additionally, the preview version has experienced response fluctuations during peak API usage, a factor that will require technical optimization during large-scale commercial rollouts.

