En mis recientes evaluaciones de modelos, surge una pregunta constantemente: ¿Puede un agente de codificación seguir siendo rápido, confiable y asequible cuando las tareas implican ediciones de múltiples archivos, depuración repetida y uso de herramientas, no solo respuestas de un solo turno? MiniMax M2.5 es uno de los pocos lanzamientos que se entrega con suficiente Eficiencia de extremo a extremo y detalle de precios para probar esa pregunta de manera concreta.
¿Por qué estoy prestando atención a M2.5?
Me concentro menos en "una mejor puntuación de referencia" y más en si un modelo puede completar flujos de trabajo reales:
- Entrega de extremo a extremo: alcance → implementación → validación → entregables
- Eficiencia operativa: iteraciones de llamadas de herramientas, uso de tokens y estabilidad en tiempo de ejecución
- Agente ciencias económicas: si el modelo de precios admite agentes de larga duración e iteraciones repetidas
MiniMax M2.5 es interesante porque tiene como objetivo optimizar capacidad, eficiencia y costo en la misma versión, una combinación importante para los equipos de ingeniería que toman decisiones de implementación.
Para qué está diseñado el M2.5
Basado en el materiales oficiales, MiniMax M2.5 está posicionado para cargas de trabajo de productividad del mundo real en tres áreas principales:
- Para ingeniería de software (codificación agentiva):representado por SWE-Bench Verified, Multi-SWE-Bench y un énfasis en el rendimiento estable en diferentes arneses.
- Para búsqueda interactiva y uso de herramientas:incluido BrowseComp, Wide Search y el punto de referencia interno RISE de MiniMax, diseñado para reflejar una exploración más profunda dentro de fuentes web profesionales.
- Para la productividad en la oficina:centrado en tareas orientadas a entregables en Word, PowerPoint y Excel, respaldado por un marco de evaluación (GDPval-MM) que considera la calidad de salida, los rastros de ejecución del agente y el costo del token.
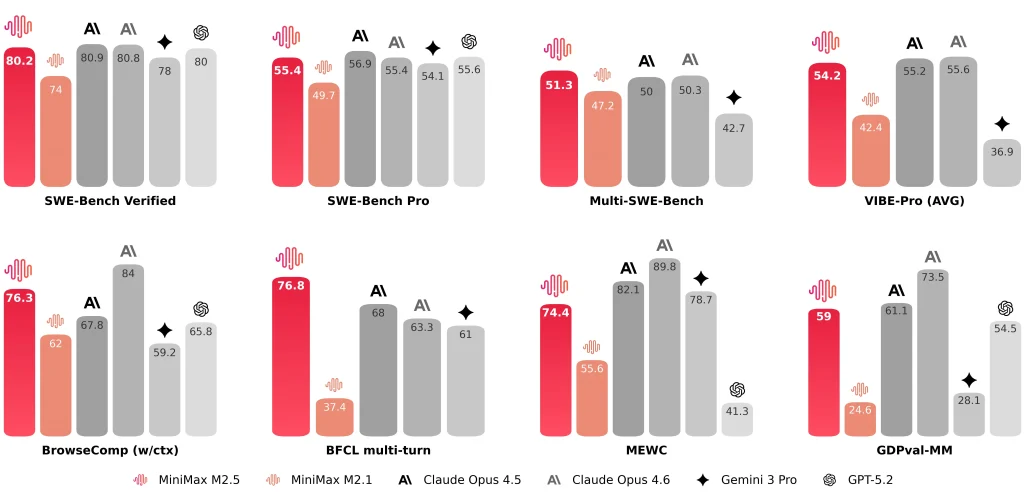
MiniMax también revela resultados representativos como SWE-Bench verificado 80.2%, Banco multiusos SWE 51.3%, y BrowseComp 76.3%.
MiniMax M2.5 vs M2.1 y Claude Opus 4.6: ¿Qué comparo?
M2.5 vs M2.1 vs Claude Opus 4.6 (Tabla de métricas clave)
| Dimensión | M2.5 | M2.1 | Claude Opus 4.6 |
| SWE-Bench verificado | 80.20% | 74.0% | 81.42% (Antrópico reportado) ~78-80% (promedio público) |
| Tiempo promedio de extremo a extremo por tarea SWE | 22,8 minutos | 31,3 minutos | 22,9 minutos |
| Tokens por tarea SWE (promedio) | 3,52 millones | 3,72 millones | — (Probablemente >4M debido a la verbosidad) |
| Iteraciones de búsqueda/herramientas vs. generación anterior | ~20% menos iteraciones (reportadas) | Base | — |
| Banco SWE de arnés cruzado (droide) | 79.7 | 71.3 | 78.9 |
| Banco SWE de arnés cruzado (código abierto) | 76.1 | 72.0 | 75.9 |
| Opciones de rendimiento | ~50 tokens/s (estándar) ~100 fichas/s (Lightning) | ~57 fichas/s | ~67-77 fichas/s |
| Precios (por 1 millón de tokens de entrada) | $0.3 (estándar y Lightning) | $0.3 | $5.0 |
| Precios (por 1 millón de tokens de salida) | $1.2 (estándar) $2.4 (Rayo) | $1.2 | $25.0 |
| Intuición horaria (salida continua) | ~$0,3/h a 50 t/s ~$1/h a 100 t/s | ~$0,3/h a 57 t/s | ~$6,50/h a 70 t/s |
Notas:
- “—” significa que el valor no fue proporcionado en los materiales resumidos aquí.
- Los puntos de referencia pueden variar según el arnés, la configuración de la herramienta, las indicaciones y las convenciones de informes, por lo que los trato como indicadores de rango, no clasificaciones absolutas.
M2.5 vs. M2.1: Mayor velocidad de extremo a extremo, menor uso de tokens, menos iteraciones de búsqueda
La comparación oficial se presenta de forma intuitiva. Presto atención a tres métricas específicas:
- Tiempo de ejecución de extremo a extremo:el tiempo promedio de la tarea SWE disminuye de 31,3 minutos (M2.1) a 22,8 minutos (M2,5), descrito como un Mejora del 37%.
- Tokens por tarea:el uso de tokens por tarea disminuye de 3,72 millones a 3,52 millones.
- Eficiencia de iteración de búsqueda/herramienta:en BrowseComp, Wide Search y RISE, MiniMax informa mejores resultados con menos iteraciones, con un costo de iteración de aproximadamente 20% inferior que M2.1.
Para mí, estas mejoras importan más que una sola puntuación de referencia porque determinan directamente rendimiento del agente y costo operativo sostenible.
M2.5 vs. Claude Opus 4.6: rango de codificación similar, el contexto de evaluación es importante
Al comparar M2.5 con Claude Opus 4.6Trato las puntuaciones como rangos en lugar de clasificaciones absolutas, porque los arneses, las configuraciones de herramientas, las indicaciones y las convenciones de informes pueden diferir.
- Antrópico toma nota de que SWE-bench de Opus 4.6 verificado El resultado es un promedio de 25 ensayos, y menciona un valor observado más alto (81.42%) bajo ajustes rápidos.
- Informes de MiniMax SWE-Bench verificado 80.2% para MiniMax M2.5.
Numéricamente, ambos parecen estar en un rango competitivo similar en cuanto a los benchmarks de agentes de codificación. Desde una perspectiva de ingeniería, me preocupa más la estabilidad en las distintas configuraciones de proyectos reales (front-end + back-end, diferentes estructuras e integraciones de terceros) que una sola cifra.
Cómo M2.5 cambia mi flujo de trabajo (Notas prácticas)
Velocidad y estilo de flujo de trabajo
Después de la integración MiniMax M2.5 En una cadena de herramientas de agente de codificación, se destacan dos cosas:
- La velocidad del MiniMax M2.5 mejora sustancialmente la iteración de tareas cortasMuchas tareas reales siguen el ciclo «pequeño cambio → ejecución → ajuste». Si cada ciclo introduce largas esperas, el cambio de contexto se vuelve costoso. MiniMax destaca explícitamente «mayor rapidez de extremo a extremo» y «menor uso de tokens» como resultados clave.
- MiniMax M2.5 tiende a escribir una especificación antes de la implementaciónPara tareas con múltiples archivos y módulos, prefiero que el modelo capture explícitamente los límites del alcance, las relaciones entre módulos y los criterios de aceptación antes de escribir el código. Esto facilita la auditoría y estandarización de la ejecución, y M2.5 funciona bien con esta estructura.
Estos puntos no deben pasarse por alto
Incluso con un sólido desempeño general, aún considero las siguientes como restricciones que requieren protecciones en el flujo de trabajo:
- La estrategia de depuración no siempre es proactivaPara errores difíciles de localizar, el modelo puede modificar repetidamente la implementación sin cambiar automáticamente a pruebas unitarias, registro o pasos mínimos de reproducción. A menudo necesito indicar explícitamente: "Añadir registros / escribir pruebas / delimitar la ruta de fallos".
- La recuperación externa y la integración de terceros pueden no ser confiablesAl integrar ciertos servicios externos, el modelo puede generar pasos de integración incorrectos. Prefiero restringir las entradas con ejemplos de documentación oficial en lugar de depender de código ensamblado para la recuperación.
- La sincronización de código y documentos no es siempre la predeterminada:cuando una tarea requiere “actualizar el código y también actualizar la documentación/rebaja de habilidades”, uso una lista de verificación explícita para reducir la posibilidad de que solo se actualice el código.
Estas restricciones no son exclusivas de M2.5; son barreras que aplico a la mayoría de los flujos de trabajo de agentes de codificación.
En esta etapa me posiciono MiniMax M2.5 como un modelo de productividad agencial orientado a la ingenieríaNo solo proporciona resultados de referencia, sino que también revela el tiempo de ejecución de extremo a extremo, el consumo de tokens, la eficiencia de iteración y la estructura de precios, lo que me permite evaluar el costo real de implementación utilizando un conjunto consistente de métricas.
Algunos usuarios podrían preguntarse si generar una especificación antes de codificar aumenta el costo del token y socava la afirmación de "bajo costo". Mi conclusión práctica es:
- Sí, escribir una especificación agrega algunos tokens de salida.
- En muchos flujos de trabajo reales, ese costo se compensa con menos ciclos de reelaboración y menos iteraciones de ida y vuelta., especialmente para tareas que involucran múltiples archivos, módulos cruzados o que requieren mucha depuración.
- La sobrecarga generalmente es controlable siempre que la especificación no sea excesivamente larga y no repita detalles de implementación.
A continuación se ofrecen algunos consejos prácticos para minimizar la sobrecarga del token de especificación:
- Para pequeñas tareas:solicito explícitamente “sin especificaciones; proporcionar una diferencia de código más pasos de prueba”.
- Para tareas medianas/grandes: restringir la especificación a X líneas / X balas (por ejemplo, 10–15), centrándose solo en estructura y criterios de aceptación, no detalles de implementación.
- En las cadenas de herramientas del agente:tratar la especificación como la fuente única de verdadActualice primero la sección de especificaciones correspondiente cuando cambien los requisitos y luego proceda a la codificación y validación. Esto reduce las explicaciones repetidas y el desperdicio de tokens ocultos al replantear el contexto.