
El 27 de enero, DeepSeek lanzó OCR 2 como modelo de código abierto. Tras analizar sus... informe técnicoCreo que esto representa un cambio sistemático en la forma en que la IA interpreta los datos visuales. En lugar de simplemente aumentar el número de parámetros, DeepSeek se centró en cambios arquitectónicos fundamentales para mejorar el rendimiento más allá de los límites de los Modelos de Lenguaje de Visión (VLM) tradicionales.
DeepSeek OCR 2 es más que un simple reconocimiento de texto
DeepSeek OCR 2 es un modelo de visión y lenguaje de última generación con 3 mil millones de parámetros. Se diferencia significativamente de herramientas tradicionales como Tesseract o modelos visuales básicos. OCR 2 prioriza dos objetivos específicos:
- Orden de lectura correcto: Mantiene la secuencia adecuada para texto de varias columnas, notas al pie y la relación entre encabezados y cuerpo del texto.
- Estructura de diseño estable: Asegura que las tablas, listas y contenido mixto tengan formato de estructuras utilizables.
Si necesita procesar escaneos PDF para ingresar a bases de datos, limpiar datos para sistemas RAG o analizar informes financieros complejos, OCR 2 proporciona un alto nivel de precisión y reconstrucción lógica.
Innovación arquitectónica: ¿Por qué DeepSeek OCR 2 es tan eficiente?
Reemplazar CLIP con un modelo de lenguaje
La mayoría de los modelos visuales antiguos utilizan CLIP como componente de procesamiento de imágenes. CLIP se diseñó para asociar imágenes con etiquetas de texto. Sin embargo, carece de la capacidad de comprender la relación lógica entre las diferentes partes de un documento denso.
La búsqueda profunda Solución: Ellos usaron Qwen2-0.5B (una arquitectura basada en LLM) como núcleo del codificador de visión.
El beneficio: Dado que el codificador se basa en un modelo de lenguaje, los tokens visuales tienen una capacidad de razonamiento básica durante la etapa inicial. El modelo puede identificar qué píxeles pertenecen a un encabezado y cuáles a un límite de tabla, lo que permite un procesamiento de datos más preciso.
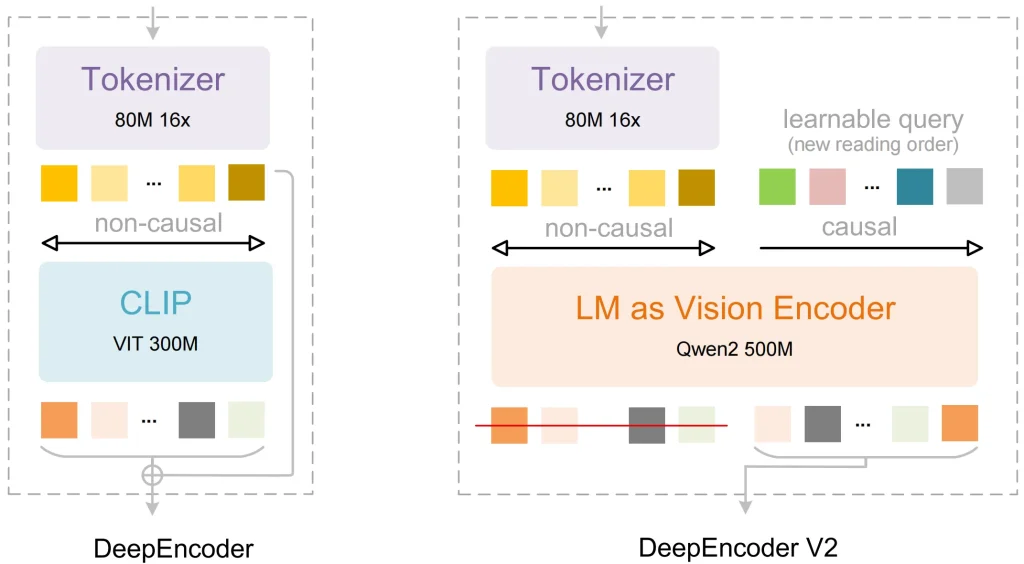
DeepEncoder V2 y flujo causal visual
Este es el avance técnico más significativo de OCR 2. Muchos modelos procesan las imágenes en una cuadrícula fija, de arriba a la izquierda a abajo a la derecha. Este orden fijo suele causar errores cuando el modelo encuentra tablas complejas o páginas con varias columnas.
La búsqueda profunda Solución: Agregaron Flujo causal visual al componente DeepEncoder V2:
- El modelo primero recopila la información global de toda la página.
- Utiliza consultas aprendibles para reordenar los tokens visuales.
- Envía esta secuencia organizada lógicamente al decodificador para generar texto.
Esto permite que el modelo recopile información basándose en el significado real de los datos. Dado que la información se organiza por diseño y semántica durante la etapa de codificación, el resultado final es muy estable.
| Métrico | Modelos tradicionales de OCR | OCR 2 de DeepSeek |
| Error de orden de lectura | Alto (lucha con las columnas) | Significativamente más bajo (la distancia de edición se redujo a 0,057) |
| Compresión de tokens | Bajo (miles de tokens por página) | Muy alto (256 – 1120 tokens por página) |
| Estabilidad/Precisión | Propenso a repeticiones o errores | Precisión del 97% (con compresión 10x) |
Avanzando la codificación visual hacia el razonamiento
Los expertos describen OCR 2 como un «codificador de visión basado en modelos de lenguaje». Esto significa que el codificador se centra en las relaciones espaciales y la información estructural, en lugar de limitarse a extraer características visuales básicas.
Los resultados:
En la prueba profesional OmniDocBench v1.5, OCR 2 obtuvo una puntuación de 91,09. Esto representa una mejora de 3,73 puntos con respecto a la versión anterior. La mayor parte del progreso se centró en la precisión de las órdenes de lectura y el manejo de diseños complejos.
Cómo usar DeepSeek OCR 2: 3 métodos de implementación rápida
DeepSeek ha publicado los pesos del modelo de Hugging Face. Puedes usar estos tres métodos para acceder al modelo para producción o investigación:
Método 1: Ajuste rápido mediante Sin pereza(Recomendado)
Unsloth está optimizado para OCR 2 y reduce significativamente el uso de memoria.
de unsloth import FastVisionModel import torch # Cargar el modelo model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # Usar cuantificación de 4 bits para ahorrar memoria ) # Plantilla de solicitud prompt = " \n<|grounding|>Convierta este documento a Markdown y extraiga todas las tablas.Método 2: Inferencia de alto rendimiento con vLLM
Esta es la mejor opción para las organizaciones que necesitan gestionar muchas solicitudes a la vez.
- Ajustes: DeepSeek recomienda configurar el
temperaturaa 0,0 para obtener los resultados más consistentes. - Soporte de idiomas: Puede especificar el idioma de destino en la solicitud. Admite más de 100 idiomas.
Método 3: Transformadores estándar de caras abrazadas
Para obtener la máxima flexibilidad, utilice la biblioteca estándar:
- Instalar los requisitos:
Instalación de pip para transformadores einops addict easydict. - Cargar el modelo:
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", código remoto de confianza=Verdadero).
Consejo: Al procesar escaneos inclinados, rotar la imagen solo 0,5 grados para enderezarla puede ayudar a que el modelo produzca resultados aún mejores.
Según mi larga experiencia en la industria de la IA, DeepSeek ha sido siempre pionero en la optimización de algoritmos centrales. Observé que sus primer modelo de OCR En octubre de 2025 ya se utilizó la compresión de tokens para mejorar la eficiencia.
OCR 2 no es solo una actualización de rendimiento. Representa un cambio fundamental en la forma en que la IA procesa la lógica visual. Al utilizar una arquitectura de modelo de lenguaje para la codificación visual, DeepSeek ha aumentado la profundidad con la que la IA comprende datos complejos. Creo que estos esfuerzos demuestran un alto nivel de visión de futuro. Este método de organización de la información a nivel básico permite a la IA leer de una forma más similar a la lógica humana y proporciona un nuevo estándar para la extracción precisa de datos en el futuro.


