À mesure que les systèmes de questions-réponses se perfectionnent, les développeurs explorent de nouvelles techniques pour optimiser leurs performances. Une approche prometteuse est le modèle RAG (Retrieval-Augmented Generation), qui combine la recherche d'informations et des capacités de langage génératif. En affinant l'intégration utilisée pour la recherche de données spécifiques à un domaine, les chercheurs ont trouvé un moyen d'améliorer significativement la précision des réponses des modèles RAG. Cet article détaille cette technique.
Introduction au RAG
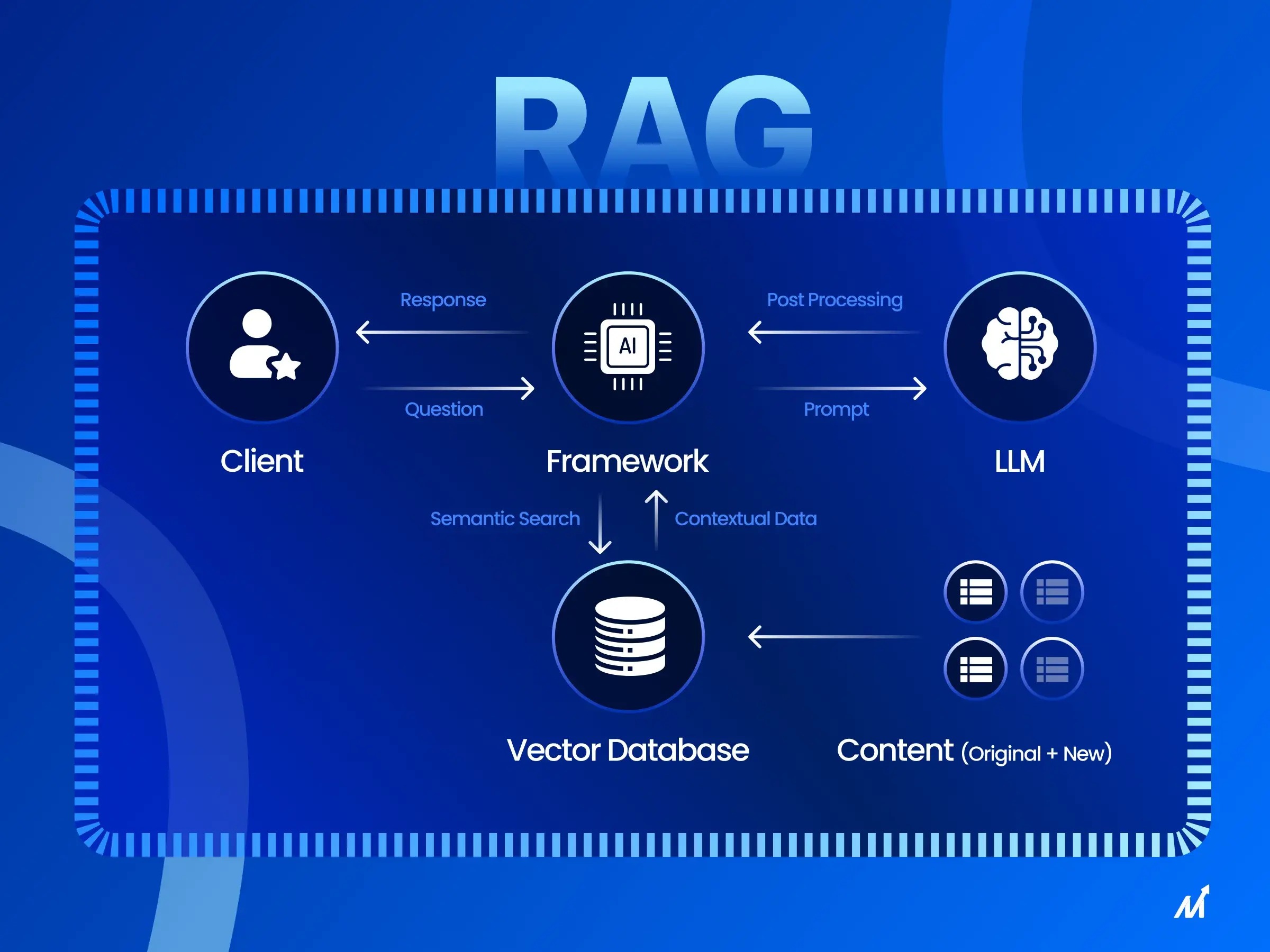
Pour mieux comprendre pourquoi le réglage des intégrations est si efficace pour les modèles RAG, nous devons d’abord couvrir quelques informations sur RAG lui-même.
Qu'est-ce que RAG ?
RAG signifie « Retrieval-Augmented Generation ». Il s'agit d'une méthode combinant la recherche d'informations et les modèles génératifs. Un modèle RAG récupère d'abord les informations pertinentes, puis génère une réponse basée sur ces informations. Cela renforce sa capacité à répondre à des questions complexes. Il se compose de deux parties : un récupérateur et un générateur. Le récupérateur extrait des extraits pertinents d'un vaste corpus de documents en fonction de la question. Le générateur utilise ensuite ces extraits pour générer une réponse cohérente. Cette approche est particulièrement adaptée aux questions ouvertes, car elle permet d'extraire dynamiquement les informations les plus récentes.
Avantages et limites des modèles RAG
Par rapport aux modèles traditionnels de recherche de texte et de génération, les modèles RAG présentent certains avantages :
- Peut fournir des résultats de recherche plus précis et plus utiles
- Peut gérer des requêtes complexes et des textes longs
- Peut générer des résultats de recherche personnalisés en fonction de l'intention de l'utilisateur
Cependant, les modèles RAG présentent également certaines limites :
- La formation et l’inférence sont coûteuses en termes de calcul
- Exigences élevées en matière de données de formation et de capacité du modèle
- Difficulté à gérer les requêtes et les textes provenant de domaines spécialisés
Le rôle des intégrations dans RAG
Maintenant que nous avons abordé les bases du RAG, examinons comment les intégrations jouent un rôle crucial et peuvent être optimisées.

Comparaison de rappel de différents modèles d'intégration sur des données de domaine
Cette expérience a utilisé plus de 30 000 extraits de connaissances et 600 questions utilisateur standard pour les tests de rappel. Nous avons principalement comparé les performances de rappel des modèles m3e-base, bge-base-zh et bce-embedding-base_v1 sur des données d'entrée en chinois et en anglais.
Ajustement du modèle d'intégration sur les données du domaine
- Collecte de données : Collectez suffisamment de données liées au domaine, y compris des documents, des paires de questions-réponses, etc. Ces données doivent couvrir les points de connaissances clés et les questions courantes dans le domaine.
- Prétraitement : nettoyez et prétraitez les données pour supprimer le bruit et la redondance, garantissant ainsi la qualité des données.
- Affinement : Affiner un modèle intégré pré-entraîné (par exemple, BERT) sur les données du domaine. L'entraînement continu sur les données du domaine permet au modèle de mieux s'adapter à la sémantique et au langage du domaine.
- Évaluation et optimisation : évaluez les performances du modèle d'intégration affiné dans RAG et ajustez les paramètres de formation et les ensembles de données selon les besoins pour optimiser davantage les performances.
Grâce à un réglage précis, le modèle d'intégration peut mieux comprendre la sémantique spécifique au domaine, améliorant ainsi les capacités de récupération et de génération du modèle RAG et augmentant les taux de réponse et la qualité.
Prenons l’exemple du modèle m3e :
Télécharger : https://huggingface.co/moka-ai/m3e-base
Référence de réglage fin : https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
Après avoir peaufiné les données du domaine et retesté le rappel, nous avons constaté une augmentation directe du taux de rappel de 33% – un résultat très prometteur.
Conclusion
Le réglage fin du modèle d'intégration est un moyen efficace d'améliorer les taux de réponse des RAG. Grâce à ce réglage fin sur les données du domaine, le modèle d'intégration peut mieux comprendre la sémantique spécifique à ce domaine, améliorant ainsi ses performances globales. Bien que les modèles RAG présentent des avantages significatifs en matière d'assurance qualité en domaine ouvert, leurs performances dans des domaines spécifiques nécessitent encore des optimisations. Des recherches futures pourraient explorer davantage de méthodes de réglage fin et d'amélioration de la qualité des données afin d'améliorer la précision des réponses et la facilité d'utilisation des modèles RAG dans tous les domaines.


