
J'évalue GLM-5 principalement comme un modèle d'ingénierie, et non pas comme un modèle de chat général qui doit simplement « sonner juste ». Mon approche est simple : j’utilise d’abord des benchmarks publics largement référencés pour confirmer la position de GLM-5 parmi les meilleurs, puis je valide ces signaux avec un flux de travail reproductible pour vérifier si GLM-5 est réellement plus stable et plus pratique pour des tâches d'ingénierie concrètes. Sur la base de ce processus, ma conclusion est que les progrès de GLM-5 ne se limitent pas à l'échelle ; ils concernent également… efficacité à long terme, formation des agents, et stabilité de sortie de qualité ingénierie Parallèlement, cette combinaison explique en partie pourquoi ses performances se rapprochent de celles des meilleurs modèles fermés, tant dans les classements composites que lors des évaluations d'agents en situation réelle.
J'utilise deux indicateurs pour établir la position de GLM-5
Pour éviter de me fier uniquement à des impressions subjectives, j'ancre mon évaluation de GLM-5 dans deux axes d'évaluation complémentaires en matière d'analyse artificielle :
- Indice d'intelligence artificielle (score de capacité composite) : Scores GLM-5 50ce qui le place dans la catégorie des meilleurs. Parmi les scores supérieurs, on trouve Claude Opus 4.6 (raisonnement adaptatif) à 53 et GPT-5.2 (xhigh) à 51, tandis que Claude Opus 4.5 figure également dans le 50 Échelle. Cet indice agrège plusieurs évaluations en un score unique qui reflète la force globale en matière de raisonnement, de codage et de capacités connexes.
- GDPval-AA (évaluation concrète du travail intellectuel par les agents) : Le GLM-5 possède un Classement Elo de 1412En termes simples, Elo est un système de notation mathématique. score de force relative en confrontation directeUn score Elo plus élevé signifie un taux de réussite global plus élevé sur un même ensemble de tâches. GDPval-AA est conçu pour reproduire des situations de travail réelles (par exemple, la récupération d'informations, leur analyse et la production de livrables) et permet aux modèles de fonctionner dans un environnement d'agents avec accès aux outils.
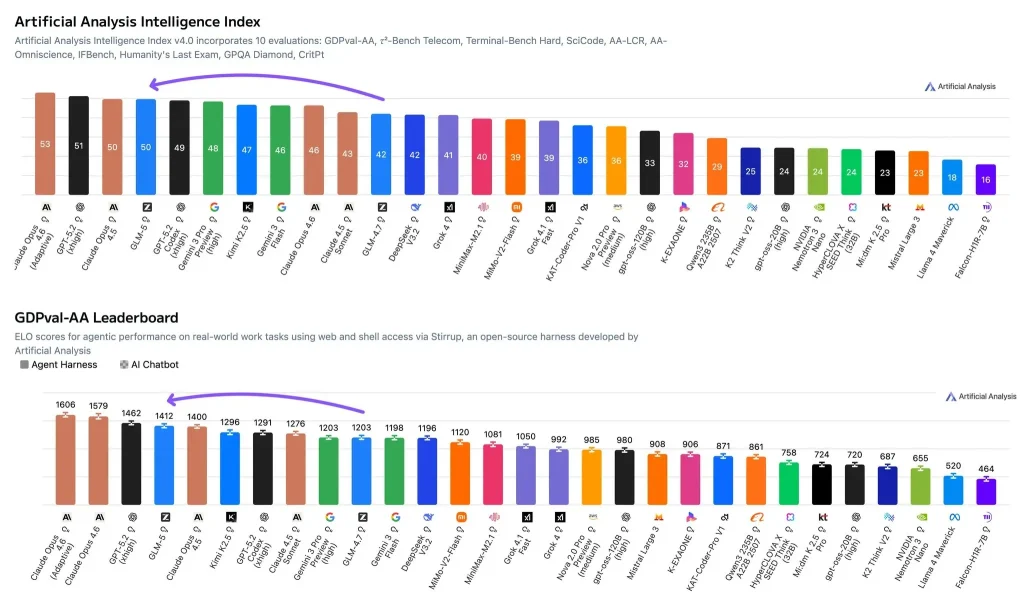
Pris ensemble, ces deux indicateurs convergent vers une hypothèse claire : L'avantage de GLM-5 ne provient probablement pas de simples « astuces » appliquées à des ensembles de tests spécifiques. Il provient plus vraisemblablement de la qualité et de la stabilité de l'exécution des tâches complexes à plusieurs étapes.
Comment je teste GLM-5 : trois flux de travail d’ingénierie à haute fréquence
Mes tests pratiques s'apparentent davantage à une validation technique qu'à une simple démonstration. Je me concentre moins sur la capacité du modèle à générer des explications plus longues que sur sa capacité à fournir des résultats corrects et exploitables malgré les contraintes. Je teste principalement trois types de flux de travail :
- Tâches d'ingénierie logicielle à long terme : Je fournis un segment de code plus long ainsi que des contraintes de documentation, et j'exige la localisation des problèmes entre les fichiers et une proposition de correction avec un minimum de modifications.
- Modifications incrémentales du code : Je demande des modifications limitées à une fonction ou un module spécifique, en conservant le reste de la structure intact, et je demande un correctif de type diff ainsi que la prise en compte des risques de régression.
- Chaînes de tâches centrées sur les outils : Je structure les tâches comme suit : récupérer → synthétiser → produire un livrable, et je vérifie si le modèle peut demander clairement les entrées manquantes et proposer un chemin de nouvelle tentative fiable en cas d'échec.
J'utilise ces flux de travail car les améliorations de l'indice d'intelligence et du PIBval-AA devraient apparaître plus clairement dans chaînes de production longues, utilisation d'outils et livrables d'ingénierie plutôt que par de courtes invites à un seul tour.
Les principales avancées du GLM-5 : une mise à niveau structurelle grâce à trois modifications de renforcement
L'attention parcimonieuse du DSA rend le contexte long économiquement viable.
Dans les documents publics et le papier, GLM-5 met l'accent sur l'adoption DSA (Attention clairsemée à recherche profonde)En clair : lorsque les entrées deviennent très longues, le modèle n’a pas besoin de consacrer la même quantité de ressources de calcul à chaque jeton. Il alloue plutôt davantage de ressources aux jetons les plus importants et pertinents, réduisant ainsi les coûts d’entraînement et d’inférence tout en préservant la qualité du contexte long.
Dans mes tests, l'implication pratique est cohérente avec cet objectif de conception : à mesure que le contexte s'élargit, la latence tend à augmenter plus progressivement., et La cohérence de sortie tend à rester plus stableCela est important dans le contexte de l'ingénierie car l'exploration du code source, l'accumulation des exigences et l'exécution à long terme élargissent naturellement le contexte au fil du temps.
L'infrastructure RL asynchrone (« slime ») est mieux adaptée aux interactions à long terme.
GLM-5 décrit publiquement une configuration d'apprentissage par renforcement asynchrone qui découple la génération de trajectoires (déploiement) de l'entraînement afin d'améliorer le débit et l'efficacité. Concrètement, cela signifie que le modèle peut apprendre plus efficacement à partir de grands volumes de traces d'interaction. comment mener à bien des tâches de bout en bout, plutôt que d'apprendre seulement à produire des réponses qui paraissent plausibles prises isolément.
Dans les flux de travail pratiques, je le constate le plus clairement dans la gestion des erreurs : au lieu de boucler sur du texte improductif, GLM-5 revient plus souvent aux contraintes et propose nouvelles étapes exécutableset il précise plus clairement quelles données sont manquantes.
Les objectifs de formation évoluent vers l'ingénierie de l'agentivité, et non plus vers l'acquisition de compétences ponctuelles.
GLM-5 se positionne explicitement comme passant d'une « programmation guidée par invite » à une approche différente. ingénierie agentiqueJ'interprète cela comme un objectif de formation qui va au-delà de l'écriture de code ou de la résolution de problèmes de raisonnement isolés : le modèle doit planifier, exécuter et réfléchir sur des horizons plus longs, produisant des résultats utilisables dans les flux de travail d'ingénierie.
Ce cadre permet d'expliquer pourquoi GLM-5 peut être performant sur GDPval-AA (tâches d'agents de travail de connaissances) tout en obtenant des résultats compétitifs sur l'indice d'intelligence composite.
Pourquoi le GLM-5 reste « juste derrière » les fleurons fermés : l’écart est plus faible, mais pas nul.
GLM-5 se situe déjà dans la même tranche de scores élevée.
UN 50 L'indice d'intelligence suggère l'absence de faiblesses majeures dans l'ensemble des évaluations ; autrement, il serait difficile de maintenir un score aussi élevé. Il se situe dans la même catégorie que Claude Opus 4.5, et légèrement en dessous de Claude Opus 4.6 (raisonnement adaptatif) et de GPT-5.2 (xhigh).
GLM-5 est proche des projets phares en matière de travail du savoir réel Agent Tâches
Un Elo de 1412 L'utilisation de GDPval-AA indique des taux de réussite relatifs élevés pour les tâches intellectuelles réalisées à l'aide d'outils. Pour les décisions de déploiement, ce résultat est souvent plus prédictif qu'une précision statique sur un banc d'essai restreint, car de nombreux scénarios de production impliquent la recherche, l'analyse, la rédaction et la coordination des outils.
Les différences restantes se manifestent dans les situations de difficulté extrême et de maturité politique.
Les systèmes phares fermés conservent souvent des avantages en matière de maturité des politiques : autocontrôle plus cohérent, limites de refus plus fiables et moins d’erreurs dans les cas limites. GLM-5 peut s’en approcher, mais pour un sous-ensemble de tâches complexes, il peut encore nécessiter des contraintes plus claires ou des garde-fous système plus robustes pour garantir un fonctionnement constant.
Avantages que je confirme en pratique : GLM-5 se comporte davantage comme un copilote d’ingénierie que comme un chatbot.
Des modifications incrémentales plus fiables, moins de réécritures inutiles
Lorsque j'ai besoin de modifications localisées tout en préservant la structure environnante, GLM-5 privilégie les remplacements ciblés ou les modifications de type diff plutôt que la réécriture de modules entiers. Cela réduit la charge de travail liée à la révision et facilite la gestion des risques de régression.
Meilleure cohérence des contraintes sur des chaînes de tâches plus longues
Lorsque je divise une tâche en plusieurs tours et que j'impose des contraintes strictes à partir des étapes précédentes, GLM-5 est plus susceptible de maintenir la cohérence de ces contraintes à mesure que le contexte s'élargit, réduisant ainsi les hypothèses contradictoires.
Des sorties de chaîne d'outils plus exploitables et une meilleure récupération après les pannes
Dans les flux de travail récupération → synthèse → livraison, je m'attache à vérifier si le modèle peut générer des étapes exécutables et une liste claire des données manquantes. GLM-5 fait généralement progresser le flux de travail plutôt que de se limiter à la couche explicative.
Limites à connaître au préalable : ce qui peut bloquer l’adoption en production
Les coûts de déploiement et des systèmes restent élevés.
GLM-5 est un modèle MoE de pointe. Même si seule une partie du modèle est activée par jeton, l'auto-hébergement nécessite un travail considérable en matière de planification de la mémoire, d'ordonnancement de la concurrence, de stratégie de cache KV, de quantification et de compatibilité avec le moteur d'inférence.
Cela ne garantira pas la victoire dans tous les marchés verticaux spécialisés.
L'indice d'intelligence et GDPval-AA privilégient le raisonnement général et les tâches intellectuelles. Si votre domaine est très spécialisé (par exemple, des processus de conformité stricts, des démonstrations mathématiques formelles de niche ou un contrôle de style extrêmement précis), il est tout de même conseillé de réaliser des tests A/B ciblés avant de prendre une décision.
Un modèle performant ne remplace pas une ingénierie des systèmes performante.
Dans les déploiements d'agents, la défaillance la plus courante n'est pas « le modèle ne peut pas répondre », mais « la chaîne d'exécution n'est pas contrôlée ». Les autorisations des outils, l'isolation de sécurité, l'observabilité, la logique de nouvelle tentative et la vérification des preuves restent nécessaires pour transformer les capacités du modèle en performances de production stables.
Quand je donnerais la priorité à GLM-5
Si mon objectif est qu'un modèle prenne en charge une part significative d'un flux de travail d'ingénierie (et non pas qu'il produise uniquement des réponses ponctuelles), GLM-5 est un candidat de premier ordre, notamment pour :
- Tâches d'ingénierie à long terme : Débogage inter-fichiers, refactorisation, localisation de problèmes complexes
- Flux de travail centrés sur les outils : récupération, écriture de scripts, synthèse de données, livrables documentaires
- Exigences relatives aux poids ouverts : déploiement sur site, personnalisation et limites de coûts/contrôle plus strictes
Si votre charge de travail est dominée par des questions-réponses courtes, est extrêmement sensible au coût/QPS, ou si vous travaillez dans des conditions de conformité très strictes sans appétit pour les garde-fous au niveau du système, je commencerais par des modèles plus légers ou des modèles phares fermés comme base et n'ajouterais GLM-5 que s'il apporte un retour sur investissement clair.


