
Dans mes récentes évaluations de modèles, une question revient sans cesse : Un agent de codage peut-il rester rapide, fiable et abordable lorsque les tâches impliquent des modifications de plusieurs fichiers, un débogage répété et l'utilisation d'outils, et non pas seulement des réponses en une seule étape ? Le MiniMax M2.5 est l'un des rares modèles livrés avec suffisamment de batterie. Détails de l'efficacité et des prix de bout en bout pour tester cette question de manière concrète.
Pourquoi je m'intéresse à M2.5
Je me concentre moins sur « le meilleur score de référence » et plus sur la capacité d'un modèle à exécuter des flux de travail réels :
- Livraison de bout en bout: périmètre → mise en œuvre → validation → livrables
- efficacité opérationnelle: itérations d'appel d'outils, utilisation des jetons et stabilité d'exécution
- Agent économie: si le modèle de tarification prend en charge les agents actifs sur le long terme et les itérations répétées
Le MiniMax M2.5 est intéressant car il vise à optimiser capacité, efficacité et coût dans la même version – une combinaison importante pour les équipes d'ingénierie qui prennent des décisions de déploiement.
À quoi sert le M2.5
D'après documents officiels, MiniMax M2.5 est positionné pour répondre aux charges de travail de productivité réelles selon trois axes principaux :
- Pour le génie logiciel (codage génétique): représenté par les certifications SWE-Bench Verified et Multi-SWE-Bench, et par une priorité accordée à la stabilité des performances sur différents types de harnais.
- Pour la recherche interactive et l'utilisation des outils: y compris BrowseComp, Wide Search et le benchmark interne RISE de MiniMax, conçu pour refléter une exploration plus approfondie des sources Web professionnelles.
- Pour la productivité au bureau: axé sur les tâches orientées livrables dans Word, PowerPoint et Excel, soutenu par un cadre d'évaluation (GDPval-MM) qui prend en compte la qualité de la sortie, les traces d'exécution de l'agent et le coût du jeton.
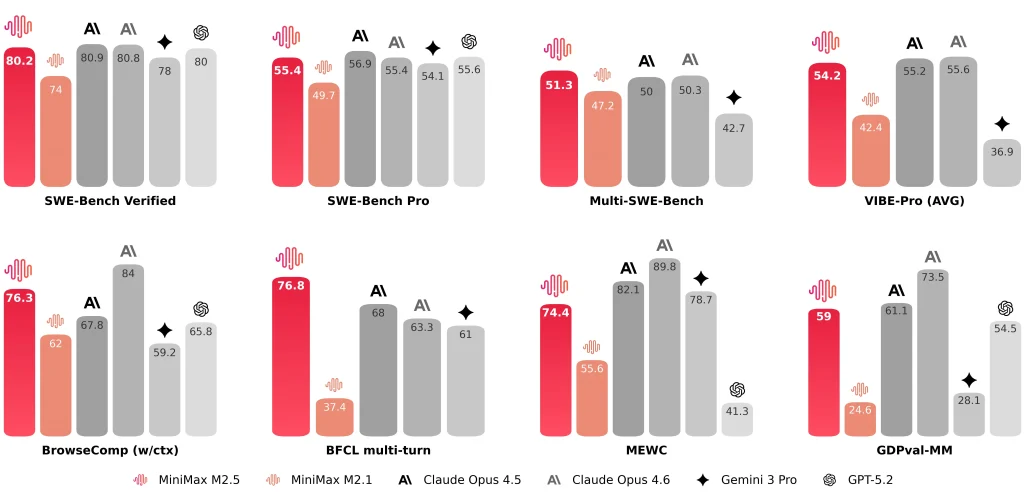
MiniMax divulgue également des résultats représentatifs tels que Vérifié par SWE-Bench : 80,2%, Banc d'essai multi-SWE 51.3%, et BrowseComp 76.3%.
Comparatif MiniMax M2.5 vs M2.1 et Claude Opus 4.6
M2.5 vs M2.1 vs Claude Opus 4.6 (Tableau des indicateurs clés)
| Dimension | M2.5 | M2.1 | Claude Opus 4.6 |
| Vérifié par SWE-Bench | 80.20% | 74.0% | 81.42% (Rapport anthropique) ~78-80% (Moyenne publique) |
| Temps moyen de bout en bout par tâche SWE | 22,8 min | 31,3 min | 22,9 min |
| Jetons par tâche SWE (moyenne) | 3,52 m | 3,72 m | — (Probablement >4M en raison de sa verbosité) |
| Itérations de recherche/outil par rapport à la génération précédente | ~20% itérations en moins (signalées) | Ligne de base | — |
| Banc SWE à faisceau croisé (Droid) | 79.7 | 71.3 | 78.9 |
| Cross-harness SWE-Bench (OpenCode) | 76.1 | 72.0 | 75.9 |
| options de débit | ~50 jetons/s (standard) ~100 jetons/s (Lightning) | ~57 jetons/s | ~67-77 jetons/s |
| Tarification (par million de jetons d'entrée) | $0.3 (standard et Lightning) | $0.3 | $5.0 |
| Tarification (par million de jetons de sortie) | $1.2 (standard) $2.4 (Éclair) | $1.2 | $25.0 |
| Intuition horaire (production continue) | ~$0,3/h à 50 t/s ~$1/h à 100 t/s | ~$0,3/h à 57 t/s | ~$6,50/h à 70 t/s |
Remarques :
- « — » signifie que la valeur n’a pas été fournie dans les documents résumés ici.
- Les performances peuvent varier selon le harnais, la configuration des outils, les invites et les conventions de rapport ; je les considère donc comme indicateurs de portée, et non des classements absolus.
M2.5 vs M2.1 : Plus rapide de bout en bout, utilisation de jetons réduite, moins d’itérations de recherche
Le tableau comparatif officiel est présenté de manière à être compréhensible par les ingénieurs. Je porte une attention particulière à trois indicateurs :
- Durée d'exécution de bout en bout: le temps moyen de traitement des tâches SWE diminue de 31,3 minutes (M2.1) à 22,8 minutes (M2,5), décrit comme un Amélioration 37%.
- Jetons par tâche: l'utilisation des jetons par tâche diminue de 3,72 m à 3,52 m.
- efficacité de l'itération de recherche/outilSur BrowseComp, Wide Search et RISE, MiniMax obtient de meilleurs résultats avec moins d'itérations, le coût par itération étant d'environ 20% inférieur que M2.1.
Pour moi, ces améliorations sont plus importantes qu'un simple score de référence car elles déterminent directement débit des agents et coût d'exploitation durable.
M2.5 vs Claude Opus 4.6 : Plage de codage similaire, le contexte d’évaluation est important
Lors de la comparaison M2.5 avec l' Claude Opus 4.6Je considère les scores comme gammes plutôt que des classements absolus, car les harnais, les configurations d'outils, les invites et les conventions de rapport peuvent différer.
- Anthropique note que Vérifié par SWE-bench pour Opus 4.6 le résultat est une moyenne sur 25 essais, et mentionne une valeur observée plus élevée (81,42%) sous ajustements rapides.
- Rapports MiniMax Vérifié par SWE-Bench : 80,2% pour MiniMax M2.5.
Numériquement, les deux semblent se situer dans une fourchette concurrentielle similaire pour les benchmarks d'agents de codage. D'un point de vue technique, je privilégie la stabilité sur des projets concrets (front-end et back-end, différentes architectures et intégrations tierces) plutôt qu'un simple chiffre.
Comment M2.5 change mon flux de travail (Notes pratiques)
Style de vitesse et de flux de travail
Après intégration MiniMax M2.5 Dans une chaîne d'outils d'agents de codage, deux éléments ressortent :
- La vitesse du MiniMax M2.5 améliore sensiblement l'itération des tâches courtes.De nombreuses tâches réelles suivent la boucle « petite modification → exécution → ajustement ». Si chaque itération introduit de longs temps d'attente, les changements de contexte deviennent coûteux. MiniMax met explicitement en avant un « taux de bout en bout plus rapide » et une « consommation de jetons réduite » comme principaux résultats.
- MiniMax M2.5 a tendance à rédiger un cahier des charges avant l'implémentation.Pour les tâches impliquant plusieurs fichiers et modules, je préfère que le modèle définisse explicitement les limites de portée, les relations entre les modules et les critères d'acceptation avant l'écriture du code. Cela facilite l'audit et la standardisation de l'exécution, et M2.5 fonctionne de manière optimale avec cette structure.
Ces points ne doivent pas être négligés.
Même avec des performances globales solides, je considère toujours les éléments suivants comme des contraintes nécessitant des garde-fous dans le flux de travail :
- La stratégie de débogage n'est pas toujours proactive.Pour les bogues difficiles à localiser, le modèle peut modifier l'implémentation à plusieurs reprises sans basculer automatiquement vers les tests unitaires, la journalisation ou les étapes minimales de reproduction. Je dois souvent donner des instructions explicites : « Ajoutez des journaux / écrivez des tests / identifiez la cause de l'échec. »
- La récupération externe et l'intégration tierce peuvent être peu fiables.Lors de l'intégration de certains services externes, le modèle peut générer des étapes d'intégration incorrectes. Je préfère contraindre les entrées à l'aide d'exemples issus de la documentation officielle plutôt que de me fier à du code « assemblé à partir de données récupérées ».
- La synchronisation du code et de la documentation n'est pas systématiquement activée par défaut.: lorsqu'une tâche exige « mettre à jour le code et également la documentation/le markdown des compétences », j'utilise une liste de contrôle explicite pour réduire le risque que seul le code soit mis à jour.
Ces contraintes ne sont pas propres à M2.5 ; ce sont des garde-fous que j'applique à la plupart des flux de travail d'agents de codage.
À ce stade, je positionne MiniMax M2.5 comme un modèle de productivité agentique orienté ingénierieIl ne se contente pas de fournir des résultats de référence ; il révèle également le temps d’exécution de bout en bout, la consommation de jetons, l’efficacité des itérations et la structure tarifaire, ce qui me permet d’évaluer le coût réel du déploiement à l’aide d’un ensemble cohérent de mesures.
Certains utilisateurs pourraient se demander si la génération d'une spécification avant le codage n'augmente pas le coût des jetons et ne remet pas en cause l'argument du « faible coût ». Ma conclusion pratique est la suivante :
- Oui, la rédaction d'une spécification ajoute des jetons de sortie.
- Dans de nombreux flux de travail réels, ce coût est compensé par une réduction des boucles de retouche et des allers-retours., notamment pour les tâches impliquant plusieurs fichiers, plusieurs modules ou nécessitant un débogage important.
- Les frais généraux sont généralement maîtrisables tant que la spécification n'est pas excessivement longue et ne répète pas les détails d'implémentation.
Voici quelques conseils pratiques pour minimiser la surcharge liée aux jetons de spécification :
- Pour les petites tâches: demander explicitement « pas de spécification ; fournir une différence de code ainsi que les étapes de test ».
- Pour les tâches de moyenne/grande envergure: contraindre la spécification à Lignes X / Puces X (par exemple, 10 à 15), en se concentrant uniquement sur structure et critères d'acceptation, et non les détails d'implémentation.
- Dans les chaînes d'outils d'agents: traiter la spécification comme la source unique de véritéMettez à jour la section correspondante des spécifications en cas de changement d'exigences, puis passez au codage et à la validation. Cela évite les explications répétitives et le gaspillage de jetons liés à la répétition du contexte.


