
Ce qu'Alibaba a réellement publié avec Qwen 3.5 : clarification de la gamme de versions
À mon avis, la première étape pour comprendre Alibaba Qwen 3.5 il s'agit de séparer clairement le modèle à poids ouvert de la hébergé dans le cloud API offre:
- Qwen3.5-397B-A17BLe modèle à poids libre. Alibaba fournit les principales caractéristiques techniques de Hugging Face, telles que : 397B paramètres totaux, 17B activés par jeton, et 60 couches.
- Qwen3.5-PlusLa version de l'API hébergée sur Alibaba Cloud Model Studio. Alibaba indique qu'elle correspond au modèle 397B-A17B et ajoute des fonctionnalités de production telles que : une fenêtre de contexte par défaut de 1M jetons, outils intégrés, et appel d'outil adaptatif.
Cette distinction revient à plusieurs reprises dans Reddit discussions. Beaucoup de gens confondent Plus, le modèle à pondération ouverte et les « extensions d’outils/de contexte », ce qui accroît la confusion lors de l’évaluation.
Ce que je considère comme les principales améliorations de Qwen 3.5
Je regroupe les améliorations en deux catégories : changements fondamentaux au niveau du modèle et optimisations d'ingénierie pour l'efficacité. Messagerie publique également mis en évidence coût inférieur, débit plus élevéet une attention particulière portée à IA agentique.
MoE extrêmement rare
Ministère de l'Éducation (Mélange d'experts) On peut la concevoir comme une architecture de modèle comportant de nombreux sous-réseaux « experts ». Lors de l’inférence, un mécanisme de routage n’active qu’un petit sous-ensemble d’experts, au lieu d’exécuter tous les paramètres à chaque fois. Les principaux avantages sont :
- Nombre total de paramètres élevé: capacité du modèle plus élevée (le modèle peut représenter davantage de modèles).
- Nombre de paramètres activés faible: le calcul d'inférence est plus proche d'un modèle plus petit, ce qui peut améliorer le débit et réduire les coûts.
Pour Qwen3.5-397B-A17B, les chiffres publiés sont 397B paramètres totaux et 17B activéReuters rapporte également les affirmations d'Alibaba concernant coût d'utilisation réduit et débit plus élevé par rapport à la génération précédente, notamment avec des affirmations telles que « environ 60% moins cher » et une capacité améliorée à gérer des charges de travail plus importantes.
Lors de l'évaluation pratique du MoE, j'envisage deux avantages : (1) à budget égal, on peut utiliser un modèle à plus grande capacité, et (2) à débit cible égal, on peut réduire la charge de calcul. Toutefois, ces gains dépendent d'un routage robuste, d'une parallélisation efficace et d'un entraînement stable. Dans le cas contraire, les systèmes MoE peuvent présenter des variations de qualité ou une instabilité de service.
Prédiction conjointe native multi-jetons
Les modèles autorégressifs traditionnels prédisent un jeton suivant par étapeL'objectif de prédiction conjointe multi-jetons est de produire des prédictions pour plusieurs postes futurs en une seule passe avant, tout en entraînant explicitement le modèle à maintenir la cohérence de ces prédictions.
Voici, en termes simples, l'impact pratique sur la vitesse d'inférence :
- Si le modèle peut « anticiper » de manière fiable et prédire plusieurs jetons à la fois, et si une politique d'acceptation ne conserve que les résultats à haute confiance, il peut réduire le nombre d'étapes de décodage.
- Un nombre réduit d'étapes de décodage augmente généralement le débit, notamment pour les sorties longues ou les charges de travail à contexte long.
Quelques cartes modèles tierces et les résumés des écosystèmes traitent également prédiction multi-jetons comme un facteur important expliquant les gains de débit de Qwen 3.5.
Lors de l'évaluation de cette technique, je me concentre sur deux points : la stabilité de la stratégie d'acceptation et son comportement lors d'un échantillonnage à basse ou haute température. D'après mon expérience, les charges de travail de préremplissage importantes et une forte concurrence ont tendance à révéler plus rapidement l'instabilité.
Multimodalité native
Blog officiel de Qwen d'Alibaba positions Qwen 3.5 comme « agents multimodaux natifs », en soulignant qu'il s'agit d'un Modèle vision-langage natif Conçu pour la compréhension des images/vidéos et les flux de travail des agents.
Je résume ainsi la valeur de la multimodalité native :
- La vision et le langage sont entraînés dans le même espace de paramètres, ce qui peut faciliter la contribution des signaux visuels au raisonnement, à l'utilisation d'outils et aux décisions d'action ultérieures.
- Elle correspond mieux aux tâches des « agents visuels ». Reuters mentionne également des fonctionnalités liées à l'exécution de tâches sur des applications mobiles et de bureau.
Comment j'interprète le profil de capacités de Qwen 3.5 : forces et limites
Je ne recommande pas de se fier à un ou deux classements. Une approche plus pertinente consiste à répartir les compétences en catégories correspondant à vos tâches métier.
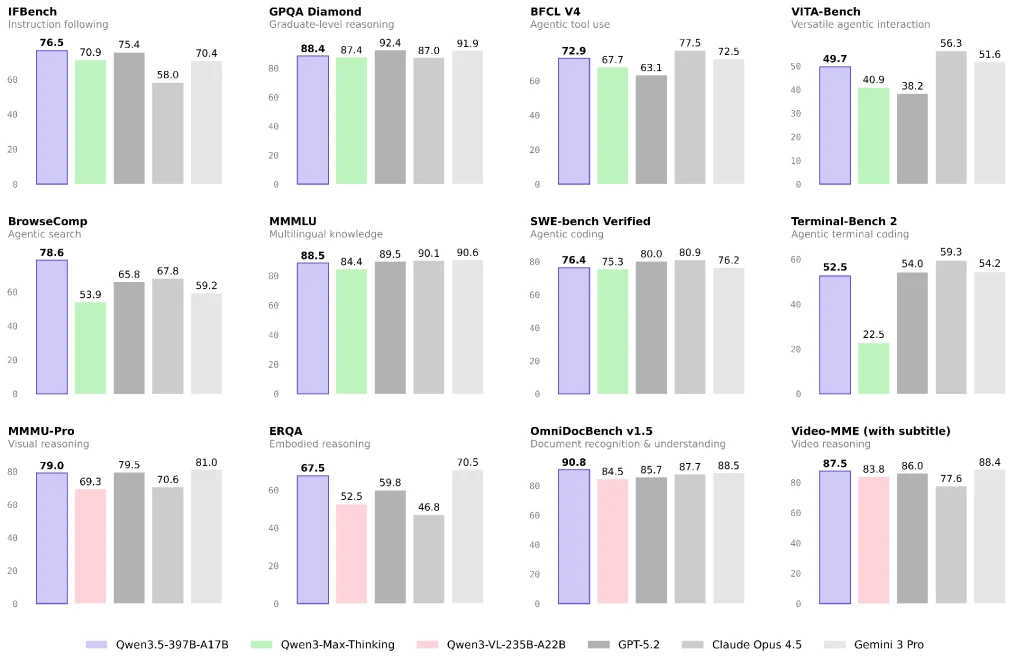
Langage et raisonnement général : proches du sommet du modèle fermé, mais la variété des tâches compte
Les rapports officiels et ceux de tiers suggèrent que Qwen 3.5 obtient d'excellents résultats sur de multiples tests de langage/raisonnement et met l'accent sur une capacité élevée par unité de coût.
Si votre activité consiste principalement en des questions-réponses, la création de contenu ou des analyses générales, Qwen 3.5 peut offrir un excellent rapport qualité-prix. Je recommande toutefois de réaliser un test A/B à petite échelle sur votre environnement de production réel plutôt que de se fier uniquement aux benchmarks.
Vision, documents et vidéo : un axe prioritaire pour Qwen 3.5
Qwen3.5-397B-A17B est catégorisé sur Hugging Face comme un modèle doté de capacités de vision, et le blog d'Alibaba le présente comme un outil pour les cas d'utilisation d'agents multimodaux.
Si votre application comprend les éléments suivants, je pense que Qwen 3.5 mérite d'être évalué en priorité :
- Compréhension de la mise en page complexe des documents et processus de conversion OCR-raisonnement
- Raisonnement visuel, graphiques et tableaux
- Entrée vidéo longue pour la synthèse structurée ou l'extraction d'informations (selon que vous utilisiez ou non Qwen3.5-Plus et ses capacités contextuelles)
Utilisation des agents et des outils : Je fais la distinction entre les « agents de recherche » et les « agents d’outils généraux ».
Les performances des agents varient considérablement, tant lors des évaluations que lors des déploiements réels :
- Agents de recherche Les résultats dépendent fortement de la stratégie de recherche, des politiques de repliement/compression du contexte et de l'orchestration des outils. Les discussions au sein de la communauté soulignent également que différentes stratégies peuvent engendrer d'importantes différences de score.
- Agents d'outils généraux dépendent davantage des protocoles d'outils, de la récupération des erreurs, de la stabilité à long terme et des limites d'autorisation.
Reuters note les améliorations apportées à Qwen 3.5 pour l'exécution des tâches sur les applications mobiles et de bureau, ce qui implique généralement un investissement important dans les « agents visuels + outils ».
Coût et accès : comment je choisirais entre les différentes options
Si vous souhaitez une mise en production rapide, je vous recommande de commencer par Qwen 3.5-Plus.
Ma raison est simple : Plus est livré avec des paramètres par défaut orientés production tels que une fenêtre de contexte de 1 million de jetons, outils intégrés, et appel d'outil adaptatif.
Alibaba Cloud Model Studio propose également une tarification des jetons à plusieurs niveaux (les prix varient selon le contexte).
Si vous avez besoin d'un contrôle de conformité et d'une propriété prévisible, les poids ouverts peuvent mieux convenir, mais avec des coûts d'ingénierie plus élevés.
Pour le choix des haltères, je divise le coût en trois parties :
- Calcul et mémoire pour l'inférence (MoE peut être sensible à la parallélisation et à la prise en charge du framework)
- Outils et alignement (récupération/navigation, exécution de code, isolation des permissions)
- assurance qualité (jeux d'évaluation, tests de régression, surveillance et récupération)
Mon flux de travail de validation recommandé pour un déploiement réel
- Définir la proportion des trois types de tâches : questions-réponses textuelles / documents et vision / outils et recherche
- Corriger les contraintes d'entrée/sortie : longueur du contexte, autorisation des outils et nécessité de citations
- Utiliser un seul cadre d'évaluation pour deux itinéraires :
- Route A : Qwen3.5-Plus (obtenir rapidement une base de référence)
- Route B : Poids libre 397B-A17B (mesurer le coût et la stabilité de l'auto-hébergement)
- Concentrez-vous sur les cas d'échec : défaillances d'outils dans les chaînes de traitement longues, erreurs d'interprétation des documents et pertes d'informations dues aux stratégies de recherche.
D'après les informations publiques, je vois l'orientation de Qwen 3.5 d'Alibaba comme une évolution d'un « modèle de chat » vers multimodalité + outils + exécution multiplateforme pour les flux de travail d'agents, tout en utilisant ministère de l'Éducation peu fourni et prédiction multi-jetons pour réduire les coûts d'inférence et augmenter le débit.
Si votre activité repose sur la compréhension de documents, le raisonnement visuel, la recherche ou les flux de travail inter-applications, Qwen 3.5 devrait figurer parmi vos premières options d'évaluation. En revanche, si vos besoins principaux concernent les calculs mathématiques complexes ou le raisonnement poussé, je suggère une comparaison plus rigoureuse, tâche par tâche, avec d'autres solutions de pointe avant de définir une stratégie de solution principale ou de secours.
FAQ : Questions les plus fréquentes lors de l’évaluation
Q1 : Quelle est la différence entre le Qwen 3.5 et des modèles comme le « Qwen 3 Max-Thinking » ?
J'interprète les différences selon deux dimensions :
- PositionnementQwen 3.5 met davantage l'accent sur la multimodalité native et les flux de travail multi-agents.
- Forme du produitPlus est une offre hébergée « améliorée » qui inclut souvent des paramètres par défaut pour le contexte, les outils et les politiques. C’est aussi pourquoi certains utilisateurs de la communauté trouvent les relations entre les versions peu claires.
Q2 : Pourquoi devrais-je me soucier d’un « MoE extrêmement faible » ?
Car elle influe directement sur le coût par requête et votre débit maximal. Pour les requêtes et réponses à forte concurrence et l'analyse de contexte étendu, cette architecture est plus susceptible de gérer un trafic plus important avec un budget fixe. Les paramètres et les détails structurels sont clairement indiqués dans la fiche technique.
Q3 : La prédiction conjointe multi-jetons va-t-elle nuire à la qualité de la génération ?
L'objectif est de réduire les étapes de décodage et d'améliorer le débit, mais l'impact sur la qualité dépend des politiques d'entraînement et d'inférence. Je recommande de tester séparément les tâches de sortie de format long et les tâches d'échantillonnage aléatoire élevé, et d'éviter de tirer des conclusions d'un seul test de performance.


