
AlibabaがQwen 3.5で実際にリリースしたもの:バージョンラインナップの明確化
私の考えでは、理解への第一歩は アリババ・クウェン 3.5 明確に区別することです オープンウェイトモデル から クラウドホスト型 API 提供:
- クウェン3.5-397B-A17B: オープンウェイトモデル。AlibabaはHugging Faceのコアスペックとして、 合計397Bのパラメータ, トークンあたり17Bがアクティブ化、 そして 60層.
- Qwen3.5プラスAlibaba Cloud Model StudioでホストされているAPIバージョン。Alibabaは、397B-A17Bモデルに対応し、次のような製品機能が追加されていると説明しています。 デフォルトの100万トークンのコンテキストウィンドウ, 組み込みツール、 そして 適応型ツールの呼び出し.
この区別は繰り返し登場する レディット 議論。多くの人が混同している プラス、オープンウェイトモデル、および「ツール/コンテキスト拡張」により、評価中に混乱が増大します。
Qwen 3.5のコアアップグレードについて
アップグレードを 2 つのカテゴリに分類します。 基本的なモデルレベルの変更 そして 効率性のためのエンジニアリングの最適化. パブリックメッセージ またハイライト 低コスト, より高いスループット、そして焦点 エージェントAI.
極端にまばらなMoE
MoE(専門家の混合) 多数の「エキスパート」サブネットワークを持つモデルアーキテクチャとして理解できます。推論中、ルーティングメカニズムは、毎回すべてのパラメータを実行するのではなく、エキスパートの小さなサブセットのみをアクティブにします。主な利点は次のとおりです。
- パラメータの総数が多い: モデル容量が高くなります (モデルが表現できるパターンが増えます)。
- 有効パラメータ数が少ない: 推論計算はより小さなモデルに近くなり、スループットが向上し、コストが削減されます。
のために クウェン3.5-397B-A17B公表されている数字は 合計397Bのパラメータ そして 17Bが活性化ロイター通信は、アリババの主張についても報じている。 使用コストの低減とスループットの向上 前世代と比較して、「約 60% 安価」や、より重いワークロードを処理する能力が向上したなどの特徴があります。
MoEを実際に評価する際には、2つのメリットを考えています。(1) 同じ予算でより高容量のモデルを使用できる、(2) 同じスループット目標でコンピューティング使用量を削減できる、という点です。しかし、これらのメリットは、強力なルーティング、並列化、そして安定した学習に依存します。そうでなければ、MoEシステムは品質のばらつきやサービスの不安定さを示す可能性があります。
ネイティブマルチトークンジョイント予測
従来の自己回帰モデルは、 ステップごとに次のトークンが1つの目標は マルチトークンジョイント予測 予測を立てることです 複数の将来の役職 予測の一貫性を保つためにモデルを明示的にトレーニングしながら、単一のフォワードパスで実行します。
推論速度への実際的な影響をわかりやすく説明すると次のようになります。
- モデルが確実に「先読み」して一度に複数のトークンを予測でき、受け入れポリシーが信頼性の高い出力のみを保持する場合、デコード手順の数を減らすことができます。
- デコード手順が少なくなると、特に長い出力や長いコンテキストのワークロードの場合、スループットが向上します。
いくつかの サードパーティのモデルカード エコシステムの概要では、 マルチトークン予測 Qwen 3.5 のスループット向上の重要な要素として。
この手法を評価する際には、2つの点に注目します。1つは受け入れ戦略が安定しているかどうか、もう1つは低温サンプリングと高温サンプリングでどのように動作するかです。私の経験では、長時間のプレフィルワークロードと高い同時実行性は、不安定性を早期に顕在化させる傾向があります。
ネイティブマルチモダリティ
アリババの公式Qwenブログ ポジション クウェン 3.5 「ネイティブマルチモーダルエージェント」として、 ネイティブ視覚言語モデル 画像/ビデオの理解とエージェントのワークフロー向けに設計されています。
ネイティブマルチモーダル性の価値を次のようにまとめます。
- 視覚と言語は同じパラメータ空間で訓練されるため、視覚信号が推論、ツールの使用、その後の行動決定に貢献しやすくなります。
- これは「ビジュアルエージェント」のタスクとの整合性がより高くなります。ロイターは、モバイルアプリケーションとデスクトップアプリケーションをまたいでタスクを実行する機能についても言及しています。
Qwen 3.5 の能力プロファイルの解釈:強みと限界
1つか2つのリーダーボードの結果に頼ることはお勧めしません。より効果的なアプローチは、ビジネスタスクに一致するカテゴリに機能を分類することです。
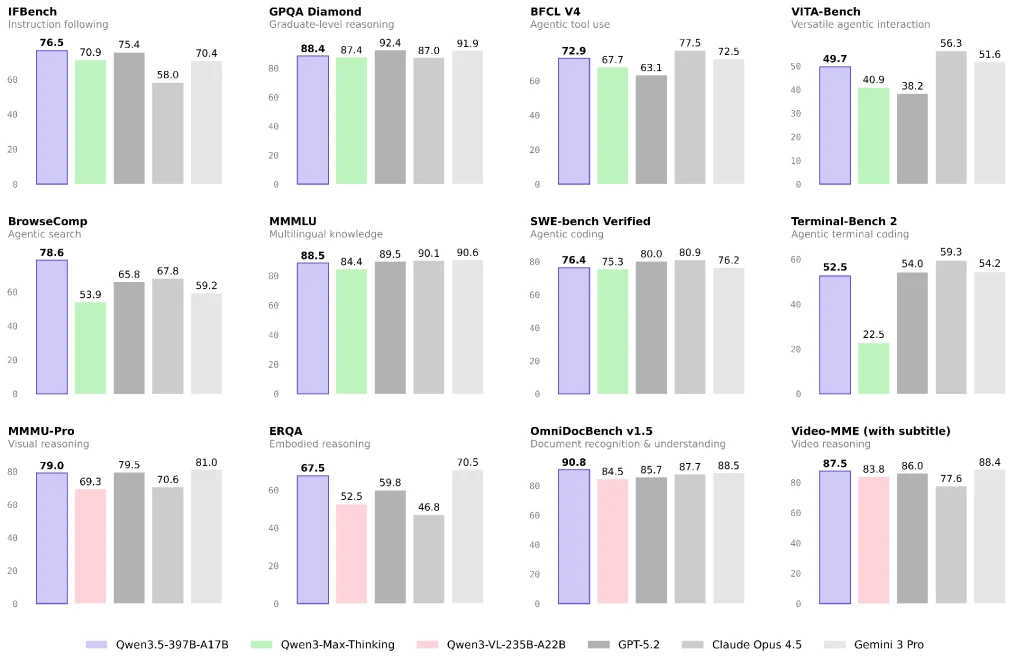
言語と一般推論:クローズドモデルのトップ層に近いが、タスクの組み合わせが重要
公式レポートおよびサードパーティレポートによると、Qwen 3.5 は複数の言語/推論ベンチマークで優れたパフォーマンスを発揮し、ユニットコストあたりの高い機能を重視しています。
ワークロードが主にナレッジQ&A、コンテンツ生成、または一般的な分析である場合、Qwen 3.5はコストパフォーマンスに優れた強力な選択肢となります。ベンチマークのみで結論付けるのではなく、実際の本番環境のタスクミックスで小規模なA/Bテストを実行することをお勧めします。
ビジョン、ドキュメント、ビデオ: Qwen 3.5 の明確な焦点領域
Qwen3.5-397B-A17B は、Hugging Face では視覚機能を備えたモデルとして分類されており、Alibaba のブログではマルチモーダル エージェントの使用例向けにフレーム化されています。
アプリケーションに以下の内容が含まれている場合は、Qwen 3.5 を優先して評価する価値があると思います。
- 複雑な文書レイアウトの理解とOCRから推論へのパイプライン
- 視覚的推論、グラフ、表
- 構造化要約または情報抽出のための長いビデオ入力(使用するかどうかによって異なります) Qwen3.5プラス およびそのコンテキスト機能)
エージェントとツールの使用:「検索エージェント」と「一般ツールエージェント」を区別する
「エージェントのパフォーマンス」は、評価と実際の展開の両方で大きく異なります。
- エージェントを検索 検索戦略、コンテキストの折り畳み/圧縮ポリシー、そしてツールのオーケストレーションに大きく依存します。コミュニティの議論では、異なる戦略によってスコアに大きな差が生じる可能性があることも指摘されています。
- 一般的なツールエージェント ツール プロトコル、エラー回復、長期的な安定性、および権限の境界に大きく依存します。
ロイターは、モバイル アプリとデスクトップ アプリ間でタスクを実行するための Qwen 3.5 の改善について言及しており、これは通常、「ビジュアル エージェント + ツール」への有意義な投資を意味します。
コストとアクセス:選択肢の中からどのように選ぶか
最速で本番環境に移行したいなら、Qwen3.5-Plusから始めるのがお勧めです。
理由は簡単です。 プラス 次のような本番環境向けのデフォルトが付属しています 100万トークンのコンテキストウィンドウ, 組み込みツール、 そして 適応型ツールの呼び出し.
アリババクラウドモデルスタジオ 段階的なトークン価格設定も提供します (価格はコンテキスト範囲によって異なります)。
コンプライアンス管理と予測可能な所有権が必要な場合は、オープンウェイトの方が適している可能性がありますが、エンジニアリングコストは高くなります。
オープンウェイトを選択する場合、コストを 3 つの部分に分割します。
- 推論計算とメモリ(MoE は並列化とフレームワークのサポートに敏感です)
- ツールと調整(取得/閲覧、コード実行、権限の分離)
- 品質保証(評価セット、回帰テスト、監視、回復)
実際の導入に向けた推奨検証ワークフロー
- 3つのタスクタイプの割合を定義します: テキストQ&A / ドキュメントとビジョン / ツールと検索
- 入力/出力制約を修正: コンテキストの長さ、ツールの許容範囲、引用が必要かどうか
- 2 つのルートで 1 つの評価フレームワークを使用します。
- ルートA: Qwen3.5プラス (ベースラインを素早く取得)
- ルートB: オープンウェイト 397B-A17B (セルフホスティングのコストと安定性を測定)
- 失敗事例に焦点を当てる: 長いチェーンにおけるツールの失敗、文書理解エラー、検索戦略による情報損失
公開情報に基づくと、アリババのQwen 3.5の方向性は「チャットモデル」から マルチモダリティ + ツール + クロスデバイス実行 エージェントワークフローでは、 まばらなMoE そして マルチトークン予測 推論コストを削減し、スループットを向上させます。
文書理解、視覚的推論、検索、あるいはクロスアプリケーションワークフローといった業務に携わるなら、Qwen 3.5は最初の評価候補リストに入れるべきです。競技レベルの数学や高度な推論が主なニーズであれば、メインモデル/バックアップモデルの戦略を決める前に、他のトップモデルとタスクごとに厳密に比較することをお勧めします。
FAQ: 評価中によく寄せられる質問
Q1: Qwen 3.5 と「Qwen 3 Max-Thinking」などのモデルの違いは何ですか?
私はその違いを2つの側面から解釈します。
- ポジショニングQwen 3.5 では、ネイティブ マルチモーダル性とエージェント ワークフローにさらに重点が置かれています。
- 製品形態: Plusはホスト型の「拡張」サービスであり、コンテキスト、ツール、ポリシーのデフォルト設定が含まれていることがよくあります。そのため、一部のコミュニティユーザーはバージョンの関係が不明瞭だと感じています。
Q2: 「極端にスパースなMoE」をなぜ気にする必要があるのでしょうか?
これは、リクエストあたりのコストとスループットの上限に直接影響するためです。高同時実行のQ&Aやロングコンテキスト分析の場合、このアーキテクチャは固定予算内でより高いトラフィックを実現できる可能性が高くなります。パラメータと構造の詳細は、モデルカードに明記されています。
Q3: 複数トークンの共同予測は生成品質に悪影響を及ぼしますか?
目標はデコードステップ数を削減し、スループットを向上させることですが、品質への影響はトレーニングと推論のポリシーに依存します。長文出力タスクと高ランダム性サンプリングタスクは別々にテストし、単一のベンチマークから結論を導き出さないことをお勧めします。


