Valuto GLM-5 principalmente come un modello ingegneristico, non come un modello di chat generale che deve solo "suonare bene". Il mio approccio è semplice: prima utilizzo benchmark pubblici ampiamente referenziati per confermare dove si colloca GLM-5 nel livello superiore, quindi convalido quei segnali con un flusso di lavoro ripetibile per verificare se GLM-5 sia realmente più stabile e pratico per compiti ingegneristici reali. Sulla base di questo processo, la mia conclusione è che il progresso di GLM-5 non riguarda solo la scala, ma anche i progressi efficienza a lungo contesto, formazione degli agenti, E stabilità di output di livello ingegneristico Allo stesso tempo. Questa combinazione aiuta a spiegare perché le sue prestazioni si avvicinano a quelle dei modelli chiusi leader sia nelle classifiche composite che nelle valutazioni agentiche del mondo reale.
Utilizzo due parametri per stabilire la posizione del GLM-5
Per evitare di basarmi solo su impressioni soggettive, ancoro la mia valutazione del GLM-5 a due percorsi di valutazione complementari dell'Analisi Artificiale:
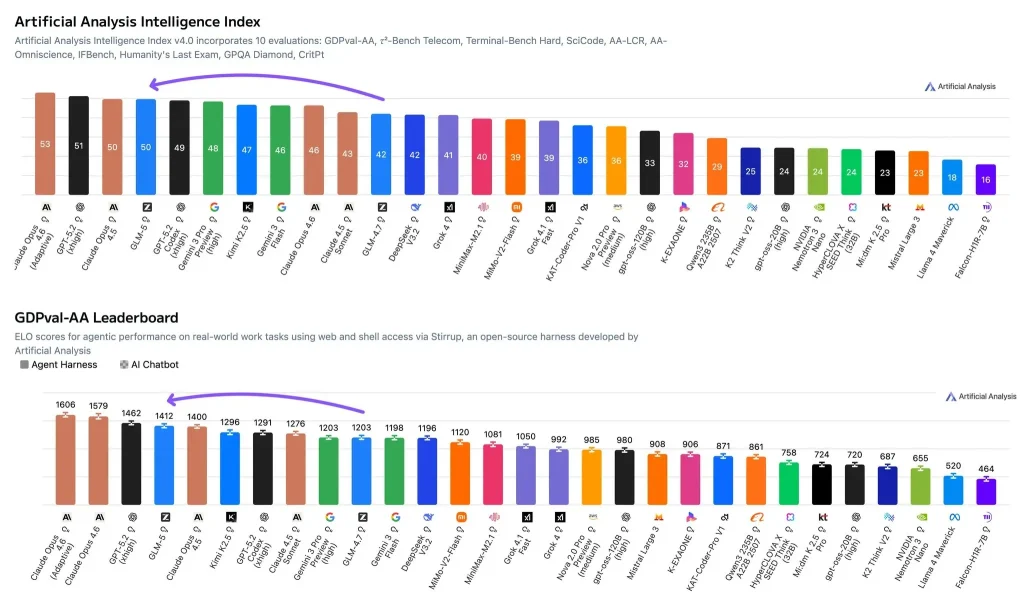
- Indice di intelligenza dell'analisi artificiale (punteggio di capacità composito): punteggi GLM-5 50, che lo colloca al livello più alto. I punteggi più alti includono Claude Opus 4.6 (Ragionamento adattivo) a 53 e GPT-5.2 (xhigh) a 51, mentre Claude Opus 4.5 è anche nella 50 intervallo. Questo indice aggrega più valutazioni in un unico punteggio che riflette la forza complessiva in termini di ragionamento, codifica e capacità correlate.
- GDPval-AA (valutazione agentiva del lavoro di conoscenza nel mondo reale): GLM-5 ha un Valutazione Elo di 1412In parole povere, Elo è un punteggio di forza relativa testa a testa—un Elo più alto significa un tasso di vincita complessivo più elevato nello stesso set di attività. GDPval-AA è progettato per riprodurre il lavoro reale (ad esempio, il recupero di informazioni, la loro analisi e la produzione di risultati) e consente ai modelli di operare in un ambiente di agenti con accesso agli strumenti.
Nel complesso, queste due metriche indicano un'ipotesi chiara: È improbabile che il vantaggio del GLM-5 derivi da isolati "trucchi dei set di test". È più probabile che derivi dalla qualità del completamento e dalla stabilità di attività complesse e articolate in più fasi.
Come testo GLM-5: tre flussi di lavoro di ingegneria ad alta frequenza
I miei test pratici sono più simili a un controllo di accettazione ingegneristico che a una "vetrina immediata". Mi concentro meno sulla capacità del modello di produrre spiegazioni più approfondite e più sulla sua capacità di fornire risultati corretti e utilizzabili in presenza di vincoli. Testo principalmente tre tipi di flusso di lavoro:
- Attività di ingegneria del software di lungo contesto: Fornisco un segmento di codice più lungo, oltre a vincoli di documentazione, e richiedo la localizzazione dei problemi tra file e una proposta di correzione con modifiche minime.
- Modifiche incrementali al codice: Ho bisogno di modifiche limitate a una funzione o a un modulo specifico, mantenendo intatto il resto della struttura, e chiedo una patch in stile diff più i rischi di regressione.
- Catene di attività incentrate sugli strumenti: Strutturo le attività come recupero → sintesi → produzione di un risultato e verifico se il modello può richiedere in modo chiaro gli input mancanti e proporre un percorso di ripetizione affidabile quando qualcosa fallisce.
Utilizzo questi flussi di lavoro perché i miglioramenti sull'Intelligence Index e sul GDPval-AA dovrebbero essere più evidenti in catene lunghe, utilizzo di utensili e risultati ingegneristici piuttosto che in brevi prompt a singola svolta.
Le innovazioni fondamentali del GLM-5: un aggiornamento strutturale grazie a tre modifiche di rinforzo
L'attenzione scarsa dei DSA rende il contesto lungo economicamente sostenibile
Nei materiali pubblici e carta, GLM-5 sottolinea l'adozione DSA (DeepSeek Sparse Attention)In parole povere: quando gli input diventano molto lunghi, il modello non ha bisogno di dedicare la stessa attenzione di calcolo a ogni token. Piuttosto, alloca più calcolo ai token che hanno maggiori probabilità di essere più importanti e rilevanti, riducendo i costi di addestramento e inferenza e puntando al contempo a preservare la qualità del contesto lungo.
Nei miei test, l'implicazione pratica è coerente con quell'obiettivo di progettazione: man mano che il contesto cresce, la latenza tende ad aumentare in modo più fluido, E la coerenza dell'output tende a rimanere più stabileCiò è importante in ambito ingegneristico perché l'esplorazione della base di codice, l'accumulo di requisiti e l'esecuzione a lungo termine ampliano naturalmente il contesto nel tempo.
L'infrastruttura RL asincrona ("slime") si adatta meglio all'interazione a lungo termine
GLM-5 descrive pubblicamente una configurazione di apprendimento per rinforzo asincrono che disaccoppia la generazione di traiettorie (rollout) dall'addestramento per migliorare la produttività e l'efficienza. Un modo pratico per interpretare questo è che il modello può apprendere in modo più efficace da grandi volumi di tracce di interazione su come completare le attività dall'inizio alla fine, piuttosto che imparare a produrre solo risposte che sembrano plausibili in modo isolato.
Nei flussi di lavoro pratici, lo vedo più chiaramente nella gestione degli errori: invece di continuare a ripetere il testo improduttivo, GLM-5 torna più spesso ai vincoli e propone nuovi passaggi eseguibilied è più esplicito riguardo agli input mancanti.
Gli obiettivi di formazione si spostano verso l'ingegneria agentiva, non verso l'acquisizione di competenze a punto singolo
GLM-5 si posiziona esplicitamente come un passaggio dalla “codifica guidata dai prompt” verso ingegneria agenticaInterpreto questo come un obiettivo formativo che va oltre la scrittura di codice o la risoluzione di problemi di ragionamento isolati: il modello deve pianificare, eseguire e riflettere su orizzonti più ampi, producendo risultati utilizzabili nei flussi di lavoro di ingegneria.
Questa inquadratura aiuta a spiegare perché il GLM-5 può essere forte nei GDPval-AA (attività di agente di lavoro di conoscenza) e allo stesso tempo ottenere punteggi competitivi nell'Indice di intelligenza composito.
Perché il GLM-5 si colloca ancora “appena dietro” alle ammiraglie chiuse: il divario è più piccolo, ma non nullo
GLM-5 è già nella stessa fascia di punteggio più alta
UN 50 Il punteggio dell'Intelligence Index suggerisce che non ci sono punti deboli significativi nelle valutazioni aggregate, altrimenti sarebbe difficile mantenere un punteggio di quel livello. Si colloca nella stessa fascia di Claude Opus 4,5 e leggermente al di sotto di Claude Opus 4,6 (Ragionamento Adattivo) e GPT-5,2 (molto alto).
GLM-5 è vicino alle ammiraglie del vero lavoro di conoscenza Agente Compiti
UN Elo del 1412 L'utilizzo di GDPval-AA implica elevati tassi di successo relativi nelle attività di knowledge work basate su strumenti. Per le decisioni di deployment, questo è spesso più predittivo dell'accuratezza statica su un benchmark ristretto, poiché molti scenari di produzione implicano il recupero, l'analisi, la scrittura e il coordinamento degli strumenti.
Le differenze rimanenti si manifestano nell’estrema difficoltà e nella maturità delle politiche
Le soluzioni di punta chiuse spesso mantengono vantaggi in termini di maturità delle policy: auto-verifica più coerente, limiti di rifiuto più affidabili e meno errori nei casi limite. GLM-5 può avvicinarsi al loro livello, ma per un sottoinsieme di attività complesse potrebbe comunque richiedere vincoli più chiari o guardrail più rigorosi a livello di sistema per garantire risultati coerenti.
Vantaggi che confermo nella pratica: GLM-5 si comporta più come un copilota di ingegneria che come un chatbot
Modifiche incrementali più affidabili, meno riscritture inutili
Quando ho bisogno di apportare modifiche localizzate preservando la struttura circostante, GLM-5 produce più spesso sostituzioni mirate o modifiche in stile diff invece di riscrivere interi moduli. Questo riduce il sovraccarico di revisione e semplifica la gestione dei rischi di regressione.
Migliore coerenza dei vincoli su catene di attività più lunghe
Quando divido un compito su più turni e applico rigidi vincoli derivanti dai passaggi precedenti, è più probabile che GLM-5 mantenga tali vincoli coerenti man mano che il contesto cresce, riducendo le ipotesi contraddittorie.
Output della catena di strumenti più eseguibili e migliore ripristino dopo i guasti
Nei flussi di lavoro "recupera → sintetizza → distribuisci", mi concentro sulla capacità del modello di produrre passaggi eseguibili e una chiara checklist degli "input mancanti". GLM-5 spesso guida il flusso di lavoro in avanti piuttosto che rimanere al livello di spiegazione.
Limitazioni da conoscere in anticipo: cosa può bloccare l'adozione della produzione
I costi di distribuzione e dei sistemi sono ancora elevati
GLM-5 è un modello MoE di punta. Anche se solo una parte del modello viene attivata per token, l'auto-hosting richiede comunque un notevole lavoro di pianificazione della memoria, pianificazione della concorrenza, strategia di cache KV, quantizzazione e compatibilità con il motore di inferenza.
Non vincerà automaticamente ogni verticale specializzato
L'Intelligence Index e il GDPval-AA tendono a privilegiare il ragionamento generale e le attività di knowledge work. Se il tuo dominio è altamente specializzato, ad esempio flussi di lavoro di conformità rigorosi, dimostrazioni matematiche formali di nicchia o controllo di stile estremamente dettagliato, dovresti comunque eseguire test A/B mirati prima di impegnarti.
Un modello forte non sostituisce una solida ingegneria dei sistemi
Nelle distribuzioni agentiche, l'errore più comune non è "il modello non può rispondere", ma "la catena di esecuzione non è controllata". Permessi degli strumenti, isolamento di sicurezza, osservabilità, logica di ripetizione e verifica delle prove restano necessari per trasformare la capacità del modello in prestazioni di produzione stabili.
Quando darei priorità a GLM-5
Se il mio obiettivo è che un modello rappresenti una parte significativa di un flusso di lavoro ingegneristico (non solo produrre risposte una tantum), GLM-5 è un candidato di alto livello, soprattutto per:
- Attività di ingegneria a lungo contesto: debugging tra file, refactoring, localizzazione di problemi complessi
- Flussi di lavoro incentrati sugli strumenti: recupero, scripting, sintesi dei dati, documenti consegnati
- Requisiti per pesi aperti: distribuzione on-premise, personalizzazione e limiti più rigidi di costi/controllo
Se il tuo carico di lavoro è dominato da brevi domande e risposte, è estremamente sensibile al rapporto costi/QPS o operi entro limiti di conformità molto rigidi senza essere disposto a rispettare misure di sicurezza a livello di sistema, inizierei con modelli più leggeri o ammiraglie chiuse come base e aggiungerei GLM-5 solo se offre un ritorno chiaro.