
1월 27일, DeepSeek은 OCR 2를 오픈 소스 모델로 공개했습니다. DeepSeek은 OCR 2를 분석한 결과, 기술 보고서저는 이것이 AI가 시각 데이터를 이해하는 방식에 있어 체계적인 변화를 나타낸다고 생각합니다. DeepSeek은 단순히 매개변수 개수를 늘리는 대신, 기존의 시각-언어 모델(VLM)의 한계를 뛰어넘는 성능 향상을 위해 근본적인 아키텍처 변경에 집중했습니다.
DeepSeek OCR 2는 단순한 텍스트 인식 그 이상입니다.
DeepSeek OCR 2는 30억 개의 파라미터를 가진 차세대 비전-언어 모델입니다. Tesseract나 기본적인 시각 모델과 같은 기존 도구와는 확연히 다릅니다. OCR 2는 두 가지 특정 목표를 우선시합니다.
- 올바른 읽기 순서: 이 기능은 다단 텍스트, 각주, 그리고 제목과 본문 텍스트 간의 관계를 올바른 순서로 유지합니다.
- 안정적인 레이아웃 구조: 이 기능은 표, 목록 및 혼합 콘텐츠를 사용 가능한 구조로 포맷팅해 줍니다.
데이터베이스 입력을 위해 PDF 스캔 파일을 처리하거나, RAG 시스템용 데이터를 정리하거나, 복잡한 재무 보고서를 분석해야 하는 경우 OCR 2는 높은 수준의 정확도와 논리적 재구성 기능을 제공합니다.
아키텍처 혁신: DeepSeek OCR 2가 그토록 효율적인 이유는 무엇일까요?
CLIP을 언어 모델로 대체하기
대부분의 기존 시각 모델은 이미지 처리 구성 요소로 CLIP을 사용합니다. CLIP은 이미지와 텍스트 레이블을 매칭하도록 설계되었지만, 내용이 빽빽하게 담긴 문서의 각 부분 간의 논리적 관계를 이해하는 데는 한계가 있습니다.
딥시크 해결책: 그들은 사용했다 퀘인2-0.5B 비전 인코더의 핵심으로는 (LLM 기반 아키텍처)가 사용됩니다.
장점: 인코더는 언어 모델을 기반으로 하기 때문에 시각적 토큰은 초기 단계에서 기본적인 추론 능력을 갖습니다. 이 모델은 어떤 픽셀이 헤더에 속하고 어떤 픽셀이 테이블 경계에 속하는지 식별할 수 있어 더욱 정확한 데이터 처리가 가능합니다.
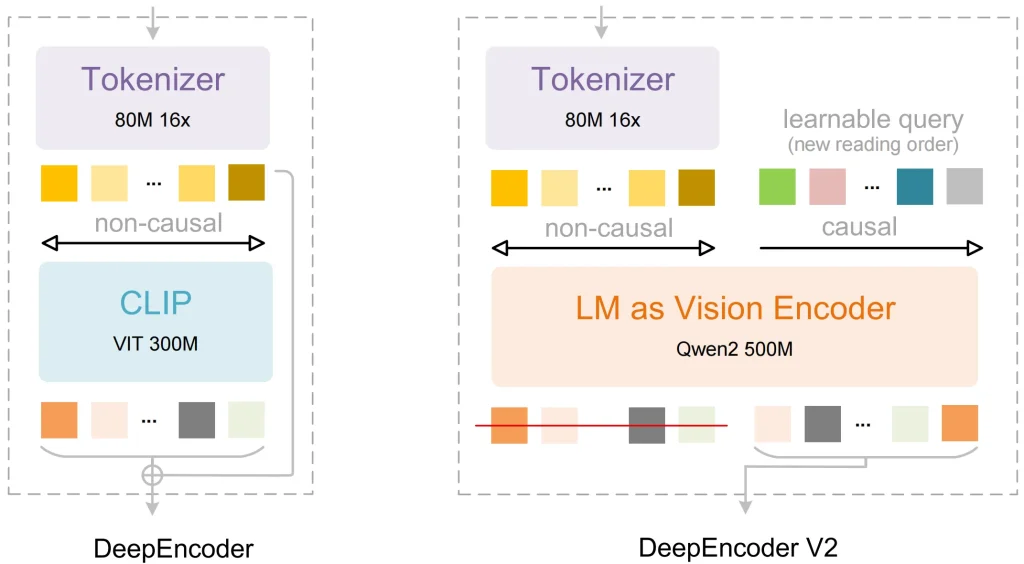
DeepEncoder V2 및 시각적 인과 흐름
이는 OCR 2에서 가장 중요한 기술적 혁신입니다. 많은 모델이 왼쪽 위에서 오른쪽 아래로 고정된 격자 순서로 이미지를 처리합니다. 이러한 고정된 순서는 모델이 복잡한 표나 여러 열로 구성된 페이지를 만날 때 오류를 발생시키는 경우가 많습니다.
딥시크 해결책: 그들은 덧붙였다 시각적 인과 흐름 DeepEncoder V2 구성 요소로:
- 이 모델은 먼저 페이지 전체의 전역 정보를 수집합니다.
- 이 시스템은 학습 가능한 쿼리를 사용하여 시각적 토큰의 순서를 재정렬합니다.
- 이 시스템은 논리적으로 구성된 순서를 디코더로 보내 텍스트를 생성합니다.
이를 통해 모델은 데이터의 실제 의미를 기반으로 정보를 수집할 수 있습니다. 인코딩 단계에서 정보가 레이아웃과 의미론에 따라 구성되므로 최종 출력은 매우 안정적입니다.
| 미터법 | 기존 OCR 모델 | DeepSeek OCR 2 |
| 읽기 순서 오류 | 높음 (기둥을 다루는 데 어려움을 겪음) | 상당히 낮아짐 (편집 거리가 0.057로 감소) |
| 토큰 압축 | 낮음 (페이지당 수천 개의 토큰) | 매우 높음 (페이지당 256~1120 토큰) |
| 안정성/정확도 | 반복이나 오류가 발생하기 쉬움 | 97% 정확도 (10배 압축 시) |
시각적 인코딩을 추론 방향으로 발전시키기
전문가들은 OCR 2를 "언어 모델 기반 비전 인코더"라고 설명합니다. 이는 인코더가 기본적인 시각적 특징 추출에만 집중하는 것이 아니라 공간적 관계와 구조적 정보에 초점을 맞춘다는 것을 의미합니다.
결과:
OmniDocBench v1.5 전문가용 테스트에서 OCR 2는 91.09점을 기록했습니다. 이는 이전 버전보다 3.73점 향상된 수치입니다. 이러한 성능 향상은 주로 문서 순서 읽기 정확도와 복잡한 레이아웃 처리 능력에서 나타났습니다.
DeepSeek OCR 2 사용 방법: 3가지 빠른 배포 방법
DeepSeek에서 Hugging Face 모델의 가중치를 공개했습니다. 다음 세 가지 방법을 사용하여 프로덕션 또는 연구 목적으로 모델에 접근할 수 있습니다.
방법 1: FastFine-Tuning을 통한 미세 조정 게으름을 떨쳐내다(추천)
Unsloth는 OCR 2에 최적화되어 있으며 메모리 사용량을 크게 줄여줍니다.
from unsloth import FastVisionModel import torch # 모델 로드 model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # 메모리 절약을 위해 4비트 양자화 사용 ) # 프롬프트 템플릿 prompt = " 이 문서를 마크다운으로 변환하고 모든 표를 추출해 주세요.방법 2: vLLM을 이용한 고성능 추론
이는 한 번에 많은 요청을 처리해야 하는 조직에 가장 적합한 선택입니다.
- 설정: DeepSeek은 다음 설정을 권장합니다.
온도가장 일관된 결과를 얻으려면 값을 0.0으로 설정하십시오. - 언어 지원: 프롬프트에서 대상 언어를 지정할 수 있습니다. 100개 이상의 언어를 지원합니다.
방법 3: 표준형 얼굴 밀착형 변환기
최대한의 유연성을 확보하려면 표준 라이브러리를 사용하십시오.
- 필수 구성 요소를 설치하세요.
pip install transformers einops addict easydict. - 모델을 불러오세요:
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", trust_remote_code=True).
팁: 기울어진 스캔 이미지를 처리할 때, 이미지를 0.5도만 회전시켜 똑바로 맞추면 모델이 훨씬 더 나은 결과를 내는 데 도움이 될 수 있습니다.
제가 AI 산업을 오랫동안 관찰해 온 결과, DeepSeek은 핵심 알고리즘 최적화 분야에서 꾸준히 선구적인 역할을 해왔습니다. 저는 그들의... 첫 번째 OCR 모델 2025년 10월에는 이미 토큰 압축을 사용하여 효율성을 개선했습니다.
OCR 2는 단순한 성능 향상이 아닙니다. 이는 AI가 시각적 논리를 처리하는 방식에 근본적인 변화를 가져왔습니다. DeepSeek은 시각적 인코딩을 위한 언어 모델 아키텍처를 사용하여 AI가 복잡한 데이터를 이해하는 깊이를 향상시켰습니다. 이러한 노력은 미래지향적인 사고의 수준을 보여준다고 생각합니다. 정보를 기초 수준에서 구성하는 이 방식은 AI가 인간의 논리와 더욱 유사한 방식으로 읽을 수 있도록 하며, 미래에 정확한 데이터 추출을 위한 새로운 기준을 제시합니다.


