Anthropic’s latest Claude 4 models – Claude Opus 4, its upgrade Claude Opus 4.1, and Claude Sonnet 4 – are redefining AI capabilities in 2025. But what are their key differences, and how can you leverage each effectively? This in-depth guide will explore the strengths of these three Claude models, the ideal use cases for each (from summarization to coding to creative writing), and practical Claude AI prompt engineering techniques to maximize their potential. We’ll also compare Claude 4 with OpenAI’s newest GPT-5 to see how they stack up in price, speed, reasoning, and user experience. Whether you’re a developer, content creator, or business user, read on to discover which Claude model best suits your needs – and how platforms like iWeaver.ai let you harness the power of Claude and GPT together for optimal productivity.
Key Differences and Strengths of Claude Sonnet 4, Opus 4, and Opus 4.1
If you prefer not to read through these detailed comparisons, you can simply check out Prompt Engineering Tips for Claude AI Models and the final Q&A.
Anthropic’s Claude 4 series consists of two model families: Claude Opus 4 (with its enhanced revision Claude Opus 4.1) and Claude Sonnet 4. All are state-of-the-art large language models, but they are tailored for different needs. In essence, Claude Opus is the “maximal” model focusing on top-tier performance (especially in complex coding and reasoning), while Claude Sonnet is optimized for high-volume, fast responses with excellent efficiency. Let’s break down their key differences:
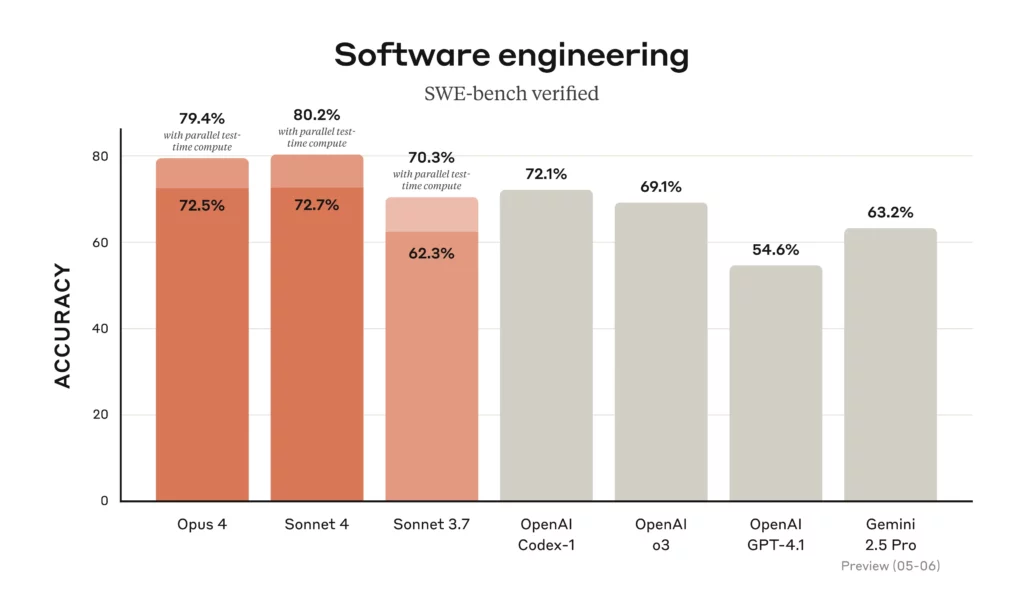
- Model Size & Power: Claude Opus 4 is Anthropic’s most powerful model, renowned as one of the world’s best coding AIs. It achieves top scores on coding benchmarks (SWE-bench ~72.5%) and can sustain long, complex reasoning tasks for extended periods. Claude Sonnet 4, while slightly less powerful, is a significant upgrade over the previous Sonnet 3.7 and delivers state-of-the-art performance in coding as well (SWE-bench ~72.7%). Sonnet 4 provides an optimal blend of capability and practicality, handling most tasks nearly as well as Opus but with lower computational overhead. In practice, Opus excels in the most challenging problems and lengthy “thinking” sessions, whereas Sonnet shines in everyday tasks with speed and precision.
- Speed & Efficiency: Claude Sonnet 4 operates in a near-instant response mode, making it highly responsive for interactive chats and high-volume queries. It’s designed for efficiency – including use in real-time applications and serving many users at once – without compromising much on quality. Claude Opus 4 can also respond quickly for typical prompts, but it truly stands out when allowed to engage in “extended thinking” mode for difficult tasks. This extended mode lets Opus deliberate through multi-step problems (even running for several hours if needed) to produce superior answers, something Sonnet doesn’t match on the toughest challenges. In short, Sonnet 4 is tuned for speed and cost-efficiency, whereas Opus 4 trades a bit of latency for deeper reasoning when required.
- Memory & Context: All Claude 4 models boast an industry-leading 200,000-token context window. This means they can handle extremely large inputs and conversations (roughly 150k+ words) in one go – an order of magnitude beyond what most other AI models manage. Both Sonnet and Opus share this capability, so you can feed long documents or multi-file data into either. However, Opus 4 has enhanced mechanisms for maintaining working memory during extended tool-assisted reasoning. For example, it can create and refer to “memory files” when given the ability to write to local storage, helping it remember key facts over a lengthy problem-solving session. In standard chat usage, Claude Sonnet 4 and Opus 4 will both remember details across very long dialogues, but Opus may maintain coherence slightly better in ultra-complex threads due to its advanced reasoning focus.
- Pricing & Access: One major difference is cost. Claude Opus 4 is about 5× more expensive to use than Sonnet 4. As of their release, Opus 4 is priced at $15 per million input tokens and $75 per million output tokens, whereas Sonnet 4 costs only $3 per million input and $15 per million output. This reflects Opus’s higher compute usage. Consequently, Anthropic currently provides Claude Sonnet 4 access even to free-tier users on the Claude web interface (it’s the default model for most users), making cutting-edge AI accessible to all. Claude Opus 4, on the other hand, is available to paid subscribers and enterprise plans, as well as via API and partner platforms. The Claude Opus 4.1 update carries the same pricing as Opus 4. In practice, you’ll want to deploy Opus for cases where its extra power justifies the cost, and rely on Sonnet for routine tasks to save budget.
- Claude Opus 4.1 – What’s New?: Released in August 2025, Opus 4.1 is a minor version bump to Opus 4 that brings notable quality improvements. It advances Claude’s state-of-the-art coding performance from 72.5% to 74.5% on SWE-bench, now matching or exceeding the very latest competitors. Users have observed Opus 4.1 handling multi-file code refactoring and large codebase navigation even more adeptly than 4.0. For instance, GitHub noted significantly better results on complex coding tasks like refactoring multiple files, and internal benchmarks at companies like Rakuten showed Opus 4.1 pinpointing bug fixes with greater precision (avoiding unnecessary changes). In terms of reasoning, Opus 4.1 also improved detail tracking during analytical tasks and “agentic” problem solving (where the AI must search or use tools autonomously). Importantly, Opus 4.1’s behavior and interface remain the same as Opus 4 – it’s simply a drop-in superior model. If you have access to Opus, upgrading to 4.1 is recommended for all uses, as it retains the same cost but yields better accuracy and reliability.
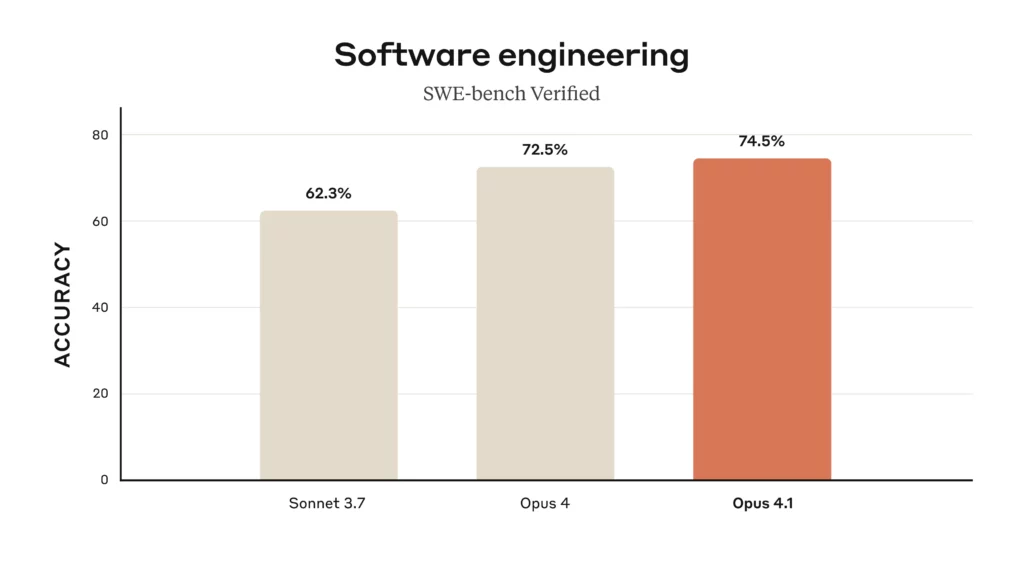
To summarize these differences, here’s a quick comparison table:
| Model | Context Window | Pricing (per 1M tokens) | Strengths | Ideal For |
|---|---|---|---|---|
| Claude Sonnet 4 | 200k tokens | $3 input / $15 output | Fast, near-instant responses; strong coding & reasoning (72.7% SWE-bench); highly efficient; available to all users. | Everyday tasks, high-volume queries, customer-facing chatbots, summary & writing tasks where speed/cost matter. |
| Claude Opus 4 | 200k tokens | $15 input / $75 output | Anthropic’s flagship model; best-in-class coding (72.5% SWE-bench); sustained deep reasoning on long tasks; extended tool use & memory. | Complex coding projects, multi-step analytical problems, AI agents requiring long reasoning, and scenarios demanding maximum accuracy. |
| Claude Opus 4.1 | 200k tokens | $15 input / $75 output (same as Opus 4) | Enhanced version of Opus 4 with improved coding accuracy (~74.5%); better multi-file code refactoring and precise problem solving; otherwise same capabilities as Opus 4. | All use cases where Opus 4 is used – Opus 4.1 should be used preferentially due to its higher quality at no extra cost. |

Use Cases: Where Each Claude Model Excels
Choosing between Sonnet 4 and Opus 4.1 depends largely on your specific use case. Here we highlight several common scenarios and note which Claude model is the best fit for each:
- Large-Scale Summarization & Document Analysis: If you need to summarize or analyze very long documents (reports, research papers, e-books, etc.), Claude Sonnet 4 is a superb choice. With its 200K-token context, it can ingest hundreds of pages and produce concise summaries or extract key insights with low hallucination rates. Sonnet’s efficiency means it can handle bulk document processing (even multiple files in one chat) quickly and affordably. Claude Opus 4, however, might be employed for especially complex or technical documents where deeper reasoning is required. Opus can provide more nuanced, detailed breakdowns of dense material (for example, legal contracts or intricate academic papers) thanks to its extended thinking ability. In most general cases, though, Sonnet 4 will be sufficient and cost-effective for summarization tasks, whereas Opus is reserved for when you need that extra layer of comprehension and accuracy.
- Coding, Debugging & Software Development: Here Claude Opus 4/4.1 truly shines. Opus 4 is widely recognized as one of the best AI coding assistants available, outperforming other models on software engineering tasks. It can handle complex programming challenges – from writing functions and fixing bugs to refactoring large codebases – while maintaining high accuracy. For example, Opus can work through multi-file projects and long debugging sessions without losing context, even improving code quality as it goes. The updated Opus 4.1 further cements this lead with even better performance on coding benchmarks and an ability to precisely locate errors in large codebases. If you’re a developer tackling a tricky algorithm or large-scale project, Opus is the go-to model. Claude Sonnet 4, on the other hand, is no slouch with code either – it scored on par with Opus in many coding benchmarks and is perfectly capable for simpler coding tasks. Sonnet 4 can generate code snippets, provide explanations, and solve moderate difficulties quickly. It’s ideal for day-to-day coding Q&A, pseudo-code generation, or acting as a pair programmer for straightforward problems. In short, use Opus for mission-critical or highly complex development work, and Sonnet for quick coding assistance or when cost/speed is a priority.
- Creative Writing & Content Generation: Both Claude models are skilled at generating text, but there are subtle differences. Claude Sonnet 4 is tuned for a warm, conversational tone and improved content generation capabilities. It can produce compelling stories, blog articles, marketing copy, and more. Sonnet’s outputs are often concise and on-point, which is great when you need a quick creative piece or a well-structured answer. Claude Opus 4.1 can certainly handle creative writing as well, and with its advanced reasoning, it may excel at longer and more complex narratives or thematic consistency across a very long piece. If you were writing a novel or a detailed report that requires the AI to “remember” many elements and weave them together, Opus’s stronger long-range coherence might be beneficial. However, for most creative tasks like social media content, short stories, brainstorming, or drafting emails, Sonnet 4’s speed and low cost make it the practical choice. It’s worth noting that both models have been trained to understand nuances and tone – users have praised Claude for producing human-like, engaging prose. If one model’s output isn’t perfectly in line with your creative vision, you can always try the other; but generally Sonnet 4 offers more than enough creativity for everyday needs, while Opus 4.1 is there if you hit the limits and need that extra depth or length.
- Chatbots & Customer Support Agents: When building an interactive assistant or customer service bot, consistency, speed, and accuracy are key. Claude Sonnet 4 is ideal here – it offers “superior instruction following” and can handle complex queries in a conversational setting with ease. Sonnet’s ability to quickly respond and its low cost means it can scale to handle many simultaneous conversations, which is important for customer support scenarios. It’s also designed to correct its own mistakes on the fly and follow up queries seamlessly, giving a very human-like support experience. Claude Opus 4 could be used for a chatbot as well, especially if your bot needs to perform very complex multi-step actions or analyses during a chat (for example, guiding a user through a complicated troubleshooting process). But in most cases, a well-prompted Sonnet 4 will suffice for support and FAQ bots – it’s capable of advanced reasoning in a chat context and even integrating tools when necessary. Many teams might deploy Sonnet for the front-line agent and reserve Opus for escalation or specialized requests that demand heavy reasoning. In summary, Sonnet 4 is the go-to for AI chatbots and virtual assistants serving customers, thanks to its speed and strong dialogue skills, while Opus 4 is on call for the exceptionally hard questions.
- “AI Agent” Automation & Tool Use: One of Claude 4’s groundbreaking features is its ability to use tools and function as an autonomous agent for complex tasks. Both Sonnet and Opus models can utilize external tools (via APIs or integrations) such as web search, code execution, or even controlling a computer interface. If you are building an AI that needs to take actions – like searching information online, executing calculations, or manipulating documents – Claude Opus 4.1 is generally the best choice. Opus’s extended thinking mode was designed for agentic workflows, allowing it to alternate between reasoning and tool calls in long chains of thought without losing effectiveness. It can plan multi-step solutions and adjust its approach based on tool outputs better than any previous Claude. Claude Sonnet 4 also supports these capabilities and can power many automation tasks (indeed, Sonnet 4 itself can use tools and act in agent-like scenarios). The difference is that Opus might pursue a deeper strategy if the task is very complicated or if an agent needs to run for an extended time to achieve a goal. For example, for a workflow that involves searching a database, then analyzing results, then writing a report, an Opus agent could handle it end-to-end with fewer errors. Sonnet could certainly attempt the same, but might simplify steps to finish faster. In summary, for AI-driven task automation and agents, Sonnet 4 is capable for straightforward or shorter autonomous tasks, while Opus 4.1 is preferable for long-horizon, complex decision sequences where absolute thoroughness is needed.
Prompt Engineering Tips for Claude AI Models

Effective prompt engineering is crucial to get the best results from Claude Opus 4/4.1 and Claude Sonnet 4, especially since these models are very powerful (and the Opus series comes with a higher token cost for lengthy outputs). By crafting prompts thoughtfully, you can improve response quality, control the output format, and avoid unnecessary token usage. Below are some proven prompt-engineering techniques and tips for Claude models, along with common pitfalls to avoid:
- Be Clear and Explicit in Instructions: Claude 4 models respond best to specific, detailed instructions. Avoid ambiguity. Rather than a generic prompt like “Write a summary,” provide concrete details about what you need. For example: “Summarize the attached report in 3 paragraphs, focusing on the key findings and recommendations, and use a formal tone.” The more explicitly you describe the desired output, the more likely Claude will deliver exactly what you want. Opus and Sonnet are both capable of “reading between the lines,” but with Claude 4 you often get better results by stating your requirements outright. If you enjoyed how older Claude versions would sometimes go “above and beyond,” you can still get that – just ask for it explicitly (e.g. “Feel free to provide additional insights or creative suggestions beyond the basics”).
- Provide Context or Examples: Claude models benefit from context that explains why or how to fulfill the request. If your prompt includes a rationale or background, the model can tailor its answer more appropriately. For instance, instead of just commanding “Never use slang in the response,” you might say “The audience is a group of executives, so please avoid slang and use professional language.” This gives Claude a reason to follow the guideline, resulting in more consistent output. Similarly, few-shot examples can be very effective. If you want a response in a specific format or style, show a short example in your prompt. For instance: “Answer the question in a JSON format as follows: {‘answer’: ‘…’, ‘source’: ‘…’}.” Claude will pick up on the pattern. Just ensure any examples you give exactly reflect the style or behavior you want – the model will generalize from them, so incorrect or irrelevant examples can mislead it.
- Use Step-by-Step Reasoning (Chain-of-Thought): Claude 4 models are adept at complex reasoning, and you can prompt them to “think through” a problem step by step. If you have a complicated question, consider asking Claude to show its reasoning process. For example: “Break down your reasoning step by step before giving the final answer.” Claude might then enumerate its thought process (you can even request it in a structured format or in a hidden
<!-- -->block if you don’t want it in the final answer). This approach, often called chain-of-thought prompting, can lead to more accurate answers on tasks like math problems or logical puzzles because the model will carefully derive the solution rather than jumping to a conclusion. Claude Opus 4 in particular was designed with this extended thinking in mind and will readily comply with such prompts. Just note that showing the reasoning will use more tokens – for everyday use you might not need it, but for tricky problems it’s a great technique. - Control the Output Format: If you need the answer in a particular structure (bullet points, JSON, markdown table, etc.), explicitly instruct Claude on the format. Claude 4 is quite obedient to format requests. For example: “List the steps as bullet points.” or “Provide the output as a table with columns X, Y, Z.” You can even use special tokens or XML-like tags to enforce format (as suggested by Anthropic). For instance: “Answer in
<analysis>tags with one<step>per thought.” Generally, it’s easier to just describe the format in plain language, and maybe give an example. Claude will usually follow it closely. One thing to avoid is telling it only what not to do (“Don’t write too verbosely” etc.) – it’s better to phrase positive instructions (“Keep the answer concise and to the point”). Claude responds better when you say what to do rather than what not to do. If the format is critical, double-check the output; if it’s slightly off, you can reiterate the format instructions or use a follow-up prompt like “please correct the format to XYZ.” - Leverage System & Role Prompts: Both Claude Sonnet and Opus support a “system” message (or you can simply prepend a role-playing instruction) that sets the context or persona of the AI. For example, telling Claude “You are an expert financial advisor…” at the start of your prompt can guide the style and depth of the response. Use this to your advantage for prompt engineering: establish the role, tone, or relevant knowledge domain upfront. A system prompt can also include the rules the AI should follow (for instance, “Always cite sources for any factual statements” or “If you don’t know the answer, say so directly”). Claude 4 models follow these quite reliably throughout the conversation once set. Many users find that by defining the role or goal clearly at the beginning, the rest of the interaction goes much more smoothly. Just be careful not to overload the system prompt with too many instructions – keep it focused and let the main user prompt handle the specific query.
- Watch Out for Token Count: Because Claude models can handle very long inputs/outputs, it’s easy to accidentally generate extremely verbose answers which incur high token usage (especially with Opus, which is costlier per token). To avoid this pitfall, consider setting expectations on length: e.g. “Answer in about 3-4 sentences” or “Keep the response under 200 words.” Claude will generally comply with length guidance. Also, be concise in your own prompt – you don’t need to ramble, as the model might mirror that. If you attach very large files or context, try to ask targeted questions about them, so the answer stays focused. Another tip: Anthropic’s system offers a prompt caching feature to reuse context without re-sending it, which can save cost if you’re calling the API repeatedly. For interactive use, simply remember that more content = more tokens, so guide Claude to be as verbose or as brief as suits your needs. The great thing is that Claude will follow your lead on brevity vs. detail – you just need to specify it.
By applying these prompt engineering strategies, you’ll not only get more accurate and relevant answers from Claude, but also optimize your usage (saving time and tokens). Both Claude Sonnet 4 and Opus 4 respond well to well-crafted prompts, so a little extra thought before you hit enter can go a long way in harnessing their full potential.
Claude 4/4.1 vs. GPT-5: Price, Speed, and Capabilities
With OpenAI’s GPT-5 now on the scene, how do Claude Opus 4.1 and Sonnet 4 compare to this latest rival? Both Claude 4 and GPT-5 represent the cutting-edge in AI as of 2025, but there are some important differences in their offerings. Here’s a direct comparison across key dimensions:

- Raw Performance & Intelligence: Early evaluations suggest GPT-5 has edged ahead of Claude 4 in several benchmarks. For instance, GPT-5 achieved nearly 95% on difficult math exams and ~89% on PhD-level science questions, surpassing previous models and even Claude in many reasoning-heavy tasks. It’s touted as being extremely strong in logical reasoning and creative problem-solving – some testers say GPT-5 feels like “talking to a human expert” in its ability to handle complex questions. Claude 4 (Opus 4.1), meanwhile, was the prior leader especially in coding and certain types of planning. On coding benchmarks, GPT-5 is reported to match or slightly exceed Claude Opus 4.1 in accuracy, meaning OpenAI caught up to Anthropic’s lead there. That said, Claude Opus 4.1 remains exceptionally capable – it excelled in many areas like multi-file coding, and its performance on knowledge and reasoning is not far behind GPT-5. In fact, for some tasks (like lengthy coding sessions or sustained “agent” operations), Claude’s architecture might still hold an edge in reliability. One way to put it: GPT-5 is currently the overall leader on paper (with top scores across many academic benchmarks), but Claude 4 is extremely close and sometimes better on specific domains (coding agents, etc.). Both are vastly powerful; the gap is not huge, and day-to-day you might not notice a difference except in the most challenging queries.
- Creativity and Style: GPT-5 is widely praised for its creativity in content generation. It can produce very rich narratives, vivid descriptions, and handle open-ended creative tasks exceptionally well. For example, writing stories, poetry, or doing imaginative brainstorming, GPT-5 might give more original or “out-of-the-box” outputs (it even supports multimodal creativity, like describing images in poetic ways). Claude is also strong in creative tasks – it has a friendly, thoughtful tone by design – but some users find GPT-5’s responses to be more entertaining or nuanced for creative writing. Claude’s style tends to be measured and comprehensive, which is often great for clarity and thoroughness. In contrast, GPT-5 might take more liberties in a fun way. Depending on your preference, you might favor one or the other. Importantly, Claude is known for its safe and thoughtful responses – it carefully avoids controversial or harmful content and follows instructions diligently, which can be a plus if you need a reliable assistant that doesn’t go off the rails. GPT-5 by all accounts has also improved safety a lot (virtually no hallucinations in certain tests, and high factual accuracy), so both are solid in that regard. Overall, for pure creative flair, GPT-5 might have a slight edge; for balanced, methodical explanations with a polite tone, Claude 4 is wonderful. Many people actually run both side by side and appreciate the differences: it can be subjective which “style” you prefer.
- Speed and User Experience: In terms of latency, both Claude and GPT-5 are quite fast given their complexity, but Claude Sonnet 4 has an advantage in speed because it’s optimized for near-instant responses. Users often note that Claude (especially the Sonnet model) feels very responsive in a chat setting – it starts generating answers almost immediately for typical questions. GPT-5, being a large model (likely even larger than GPT-4), can sometimes be a bit slower to respond, although OpenAI likely optimized it for faster output than GPT-4. For single-turn prompts of moderate length, you might not see much difference – both will usually return an answer within a few seconds. In extended sessions or very large prompts, the differences might show: Claude’s handling of long contexts is efficient, and it might maintain performance even as the conversation grows, whereas GPT-5’s performance on huge contexts isn’t fully known yet (GPT-4 was limited to 32K context unless using special versions). As for user experience: Claude.ai’s interface is clean and focused on the conversation, with the handy file upload feature and no throttling for the free tier (beyond some rate limits). ChatGPT’s interface (for GPT-5) is presumably an evolution of the familiar ChatGPT UI; it might offer things like suggested follow-up questions or voice input (just speculating, since GPT-5 is new). One key difference: OpenAI’s GPT-5 is expected to be accessible via a ChatGPT Plus-style subscription for unlimited use, whereas Claude offers a free usage tier for Sonnet (with some limits) plus paid plans for Opus. So from a user perspective, if cost is no issue, both are easy to use; if you don’t want to pay at all, Claude’s free tier gives you advanced AI power (Sonnet 4) without subscription, which is a big perk.
- Pricing Comparison: Pricing models differ. Claude, as mentioned, charges per token for API usage (with Sonnet being much cheaper than Opus). For casual users on claude.ai, Sonnet 4 is free to use within daily limits, and Opus 4.1 requires a paid plan (often usage-based or tier-based). GPT-5, according to expectations, will likely require a subscription (e.g. ChatGPT Premium) for general use, and will have its own API pricing for developers (likely per 1K tokens as with previous models). That means if you’re using GPT-5 via ChatGPT, you pay a fixed monthly fee for unlimited chats (subject to fairness policies), whereas with Claude you could either use a limited free service or pay as you go for the bigger model. For businesses, both OpenAI and Anthropic offer enterprise plans. It’s hard to directly compare costs without specific numbers: if you have heavy usage (millions of tokens), Claude Sonnet 4’s $3/million input is extremely affordable, potentially cheaper than a flat subscription if you’re not using it constantly. Opus 4 at $75/million output is pricey but might still be cost-effective for what it offers (some might argue GPT-5’s ability to do tasks in fewer tokens could offset costs – it’s all relative). In summary, Claude gives a very budget-friendly option via Sonnet, and a premium option via Opus; GPT-5 likely has a single premium access model for full capability. If cost is a deciding factor and your tasks can be handled by Sonnet, Claude is the winner in value. If you need the absolute best model and are willing to subscribe, GPT-5’s cost would be justified by its top performance.

- Context Length & Data Handling: One area Claude still clearly leads is context length. Claude 4 offers up to 200K tokens of context, which vastly exceeds what was publicly known for GPT-4 (32K). For GPT-5, OpenAI has hinted at improved long conversation handling, but they haven’t confirmed a specific context size. It might be larger than 32K, but likely not as high as 200K unless they made a significant breakthrough. Additionally, Google’s Gemini is rumored to go even further (some say 1 million tokens), but that’s another story. For now, if you need to have the AI consider an extremely large amount of text, Claude is the safer bet due to its known capacity. This ties into Claude’s strength with file uploads and analysis – you can literally input a book-length text. GPT-5 might require chunking content or might not accept as large a single input. On the plus side for GPT-5, it’s multimodal not just for images but possibly video and audio in real-time (though how exactly that works isn’t fully revealed yet). Claude’s multimodality covers images and text, but not audio/video. So if your use case involves analyzing a video or an audio clip, GPT-5 (with the right interface) could do things Claude can’t currently. In summary, Claude 4 wins on sheer text context size and heavy document use, while GPT-5 pushes the envelope in multimodal input types.
Internal Linking Note: If you want a deeper dive into GPT-5’s features and how it stacks up, check out our in-depth article “GPT-5 vs The World: Why This AI Might Be the Last Tool You Ever Need” which covers its innovations.Ultimately, from a user perspective, having access to both Claude and GPT-5 is ideal – they each excel in different aspects, and platforms like iWeaver.ai conveniently support both ecosystems so you can choose the best AI for each task.
Frequently Asked Questions (FAQs)
Q: What is the difference between Claude Sonnet 4 and Claude Opus 4?
A: Claude Sonnet 4 and Claude Opus 4 are based on the same core technology but tuned for different purposes. Sonnet 4 is a high-performance model optimized for speed and efficiency – it gives near-instant answers and is cost-effective, making it great for everyday use and high-volume tasks. Opus 4 is the flagship model focused on maximum capability – it excels in more complex reasoning and lengthy tasks (especially coding or multi-step analyses) but is slower and about 5× more expensive per token. In short, Sonnet 4 = fast and economical, Opus 4 = powerful and thorough. Both have the same 200K context and support similar features, but Opus will outperform Sonnet on the very hardest problems, while Sonnet is often sufficient for most needs.
Q: What about Claude Opus 4.1? How is it different from Opus 4?
A: Claude Opus 4.1 is essentially an improved version of Claude Opus 4. It was released later with upgrades in performance – notably, it’s about 74.5% on a key coding benchmark vs. 72.5% for Opus 4. It handles coding tasks, especially multi-file and debugging tasks, with even greater precision. It also has some fine-tuned improvements in reasoning, based on user and partner feedback (e.g. better at tracking details and not making unnecessary changes). Importantly, the price is the same as Opus 4 and it functions the same way. Think of Opus 4.1 as “Claude Opus 4 with some extra polish and brainpower.” If you have access to Opus 4, you should use 4.1 since it’s strictly better but otherwise identical in usage.
Q: Which Claude model is best for coding – Sonnet or Opus?
A: Claude Opus 4 (or 4.1) is the best for coding, especially for complex projects. It’s literally described by Anthropic as the world’s best coding model. If you have a large codebase, tricky bug, or need multi-step code generation/refactoring, Opus will handle it more reliably. That said, Claude Sonnet 4 is also a very capable coder – it even scored slightly higher on one coding benchmark under certain conditions*(see chart: Claude 4 models ~72% vs GPT-4.1 ~55%)*. Sonnet can write functions, explain code, and solve typical coding interview problems just fine. It might struggle only with the most extreme cases (very large, complex code requiring extensive planning), where Opus shines. So if it’s general coding help or smaller scripts, Sonnet 4 is often enough (and cheaper). For any critical or highly complex coding tasks, go with Opus 4/4.1.
Q: How do Claude models compare to GPT-5? Are they better or worse?
A: They each have their strengths. GPT-5 is newer and has shown higher scores in many areas (math, knowledge, creative writing) – it’s arguably the single most advanced model overall. For example, GPT-5 likely outperforms Claude in complex logical reasoning and offers truly impressive creativity. However, Claude 4 isn’t far behind. In coding, Claude Opus 4.1 was a leader and GPT-5 only matches or slightly exceeds it. Claude also has practical advantages: a much larger context window (200K vs whatever GPT-5 currently has), the ability to easily handle huge documents, and a very stable, safe performance. Claude’s style is often more verbose and explanatory (which some prefer for clarity), whereas GPT-5 might be more concise and “clever” in responses. So there’s no simple “better/worse” – it depends on your use case. If you have access to iWeaver, you can choose GPT-5 for tasks needing the utmost creativity or highest reasoning accuracy, and choose Claude for tasks needing large context handling, tool use, or when you want a second opinion. Many users find Claude and GPT-5 complementary, rather than one outright replacing the other.
Q: How can I access and use Claude Sonnet 4 or Opus 4.1?
A: There are a few ways:
- Claude.ai: The easiest is to sign up at claude.ai (Anthropic’s official chat interface). Free users automatically get Claude Sonnet 4. You can start chatting and also upload files for it to analyze. If you have a paid plan, you can switch to Claude Opus 4.1 for more powerful responses.
- iWeaver.ai: On iWeaver, Claude models are integrated and you can choose Claude Sonnet 4 or Opus 4.1 within various agents (for writing, summarizing, coding, etc.). This is a convenient option if you want to use Claude alongside GPT-5 in one place. No coding required – just select the model in the interface.
- API Access: If you’re a developer, you can get API access from Anthropic. They offer keys to use Claude in your own apps. You’d choose the model (
claude-sonnet-4orclaude-opus-4.1) and then you can programmatically send prompts and get completions. This is how you’d integrate Claude into other software (Slack bots, IDE plugins, etc.). - Third-Party Integrations: Some tools and services have built-in Claude support. For example, there’s an official Claude Slack app, and some automation platforms let you add Claude as a step in workflows. Check if the tool you use has a Claude integration. In summary, for most users the claude.ai website or iWeaver will be the simplest way to play with Claude 4 models. Developers have the API route for custom integrations.
Q: Any tips for writing good prompts for Claude? (to avoid mistakes or weird outputs)
A: Yes – many of the prompt tips we gave earlier apply. In brief: be specific in what you ask, give context or examples if possible, and don’t be afraid to tell Claude your expectations (format, style, length). Claude generally doesn’t need as much hand-holding to avoid inappropriate content (it has strong safety measures), but if you want a certain tone (e.g. “be casual and friendly” or “be formal and technical”), just say so. A common pitfall is asking overly broad questions – try to break down tasks. For example, instead of “Analyze this huge dataset for everything interesting,” you might ask “Find the three most notable trends in this dataset and explain them.” Also, because Claude can output a lot, if it starts giving too long an answer, you can interject or use a follow-up like “summarize that in one paragraph.” One more tip: use the conversation. You can refine your prompt in follow-ups if the first answer isn’t on point – Claude will take the feedback and adjust. It’s quite good at iterative refinement. And of course, check out the “Prompt Engineering Tips” section above for detailed advice!
Q: How does iWeaver.ai fit into this? Why use iWeaver for Claude or GPT-5?
A: iWeaver is a platform that brings together multiple AI models and tools in one place to streamline your workflow. Instead of juggling separate interfaces for Claude and GPT-5, iWeaver lets you access both under one roof. You can use Claude Sonnet 4 or Opus 4.1 for one task and GPT-5 for another, whichever is best suited, without switching platforms. Moreover, iWeaver provides specialized “agents” (like summarizers, mind-map creators, Q&A agents, etc.) that leverage these models with pre-designed prompts. It basically enhances user experience by simplifying prompt engineering for you and integrating with things like document uploads, mind mapping, etc. If you’re someone who wants the best of both Claude + GPT worlds and an efficient way to use them, iWeaver is a great solution. Plus, it’s aimed at an international audience (with multilingual support), which aligns with this bilingual article’s spirit!
Conclusion: Unleashing Claude and GPT Synergy on iWeaver
In the rapidly evolving AI landscape of 2025, Claude Sonnet 4, Claude Opus 4.1, and GPT-5 stand out as groundbreaking tools. Each has its unique strengths – Sonnet 4 with its speed and efficiency, Opus 4.1 with its unmatched coding and deep reasoning prowess, and GPT-5 with its leap in creativity and overall intelligence. Rather than seeing one as strictly better than the other, savvy users are finding that the real power comes from using them together: leveraging the right model for the right task.
This is where iweaver.ai shines. As a unified AI productivity platform, iWeaver supports Claude and GPT models side-by-side, giving you a seamless environment to tap into both. Need a quick, cost-effective summary of a long report? Claude Sonnet 4 on iWeaver is at your service. Have a demanding coding problem or a multi-step analysis? Claude Opus 4.1 is ready to help, with its integration in the same platform. Want to explore the very latest in reasoning and multimodal understanding? GPT-5 is a click away on iWeaver, empowering you with its advanced capabilities. You can effortlessly switch contexts, compare outputs, and even have these models work in tandem for your projects.
In conclusion, Claude Sonnet 4, Claude Opus 4.1, and Claude Opus 4 bring unprecedented value in coding, content generation, and interactive reasoning – and when combined with GPT-5’s frontier capabilities, they form a complementary arsenal for tackling any task. By applying smart prompt engineering and choosing the appropriate model for each job, you can dramatically boost your productivity and achieve results that were impossible just a year ago. And with iWeaver making this technology accessible globally, there’s never been a better time to integrate AI into your daily workflow.
Ready to experience the next generation of AI assistants? Try out Claude 4 and GPT-5 on iWeaver.ai today – unlock higher efficiency, creative breakthroughs, and intelligent automation in your projects. Embrace the Claude + GPT ecosystem and take your productivity to new heights!

