
Am 5. Februar erlebte die KI-Branche eine historische „Kollision“, als Anthropic und OpenAI ihre Flaggschiffmodelle vorstellten –Claude Opus 4.6 Und GPT-5.3 Codex—direkt nacheinander.
Angesichts solch gleichzeitiger, hochkarätiger Veröffentlichungen erfordert die Bewertung des Gewinners, den Hype zu ignorieren und sich auf objektive technische Kriterien zu konzentrieren. Meine Analyse gliedert sich in der Regel in drei Ebenen: die wichtigsten technischen Neuerungen, die Ergebnisse der Benchmarks hinsichtlich ihrer Leistungsfähigkeit und die Unterschiede in der Umsetzung in realen Anwendungsszenarien. Im Folgenden werde ich dieses Rahmenwerk nutzen, um die technischen Merkmale und die empirische Leistung der beiden Modelle zu analysieren.
Analyse der Durchbrüche in Claude Opus 4.6
Basierend auf meinem vorherige Forschung und die neuesten technische Dokumentation, die Evolution von Claude Opus 4.6 Im Mittelpunkt stehen mehrere revolutionäre architektonische Neuerungen:
- Adaptives Denken: Diese Funktion ermöglicht es dem Modell, Rechenressourcen dynamisch an die Schwierigkeit der Aufgabe anzupassen. In meinen Tests reagierte das Modell nahezu verzögerungsfrei auf einfache Anfragen, während es bei komplexen Architekturentwürfen in einen Modus für tiefergehende Analysen wechselt und sich mehr Zeit nimmt, um logische Korrektheit zu gewährleisten.
- Kontext und Komprimierung von 1 Million Token API: Das Zeitfenster mit einer Million Token ist zwar enorm, die eigentliche Innovation liegt aber in der Komprimierungs-APIUm den bei längeren Gesprächen üblichen Leistungsabfall zu bekämpfen, komprimiert diese API den Dialogverlauf intelligent, indem sie nur die wichtigsten logischen Knoten beibehält. Dies reduziert die Inferenzkosten für Langzeitprojekte erheblich.
- Datenresidenzkontrollen: Diese Version ermöglicht es Unternehmenskunden, die Datenabfrage auf Server in den USA zu beschränken. Ich sehe dies als strategischen Schritt, um den strengen Compliance-Anforderungen regulierter Branchen wie dem Finanz- und Gesundheitswesen gerecht zu werden.
- 128K Ausgabelänge: Die maximale Ausgabemenge pro Durchlauf wurde auf 128.000 Token erweitert, wodurch das Modell in der Lage ist, massive Codeblöcke oder ganze technische Dokumente auf einmal zu generieren, ohne dabei an Kohärenz einzubüßen.
Entschlüsselung der agentischen Stärken von GPT-5.3-Codex
OpenAI GPT-5.3-Codex Der Fokus liegt stark auf Ausführungsgeschwindigkeit und Interaktion auf Systemebene. Laut den offiziellen Spezifikationen gehören zu den wichtigsten Merkmalen:
- Erhöhte Effizienz der Schlussfolgerungen: Das Modell arbeitet 25% schneller als sein Vorgänger, GPT-5.2 Codex. In meinen Vergleichstests zeigte GPT-5.3 Codex einen deutlich höheren Durchsatz bei identischen Skriptgenerierungsaufgaben.
- Lenkung in der Kurvenmitte: Dies ermöglicht es Benutzern, neue Anweisungen zu erteilen, während das Modell eine langlaufende Aufgabe ausführt. Wenn das Modell beispielsweise ein automatisiertes Skript im Terminal ausführt, kann ich eingreifen und dessen Ablauf in Echtzeit korrigieren, ohne den Prozess neu starten zu müssen.
- Betriebliche Leistungsfähigkeit auf Systemebene: Als „agentisches Programmiermodell“ positioniert, geht es über das Schreiben von Code hinaus. Es wurde optimiert, um Tools auf Betriebssystemebene zu nutzen, Bereitstellungen zu verwalten und Testumgebungen autonom zu überwachen.
- Selbstgesteuerte Entwicklung: OpenAI gab bekannt, dass GPT-5.3 Codex während der eigenen Trainings- und Debugging-Phasen verwendet wurde. Dies deutet darauf hin, dass das Modell einen Reifegrad erreicht hat, der es ihm ermöglicht, seine eigene Weiterentwicklung zu unterstützen.
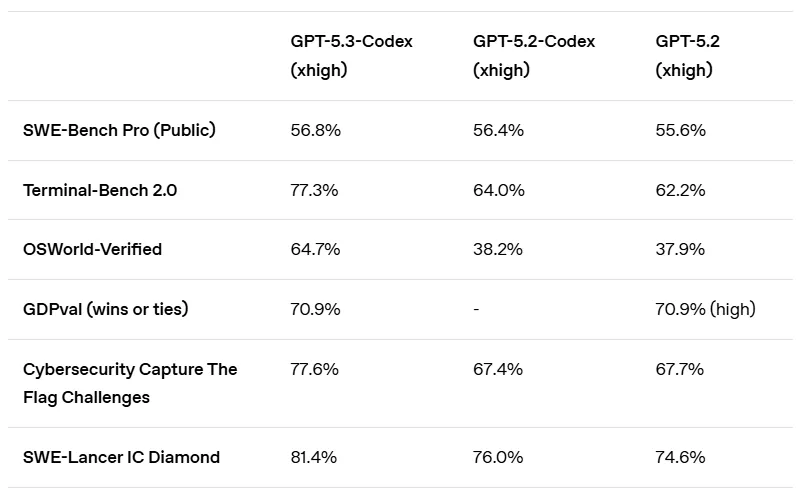
Vergleichs-Benchmarks: Claude Opus 4.6 vs. GPT-5.3-Codex
Um die Leistung objektiv zu messen, habe ich mehrere branchenübliche Benchmarks ausgewählt. Hier eine kurze Erläuterung dessen, was diese Kennzahlen bedeuten:
- Terminal-Bench 2.0: Bewertet die Fähigkeit der KI, komplexe Befehle auszuführen und Aufgaben innerhalb einer CLI (Befehlszeilenschnittstelle) zu verwalten.
- SWE-bench Pro: Misst die Erfolgsquote der KI bei der Lösung realer Softwareentwicklungsprobleme, wie z. B. tatsächliche Bugfixes auf GitHub.
- BIP-Wert-AA: Bewertet die Kompetenz des Modells in anspruchsvollen fachlichen Wissensbereichen, wie z. B. Finanzanalyse und juristischer Recherche.
- OSWorld: Testet die Fähigkeit der KI, eine grafische Benutzeroberfläche (GUI) zu bedienen, um alltägliche Büroaufgaben zu erledigen.
- Die letzte Prüfung der Menschheit: Ein anspruchsvoller, interdisziplinärer Denktest, der die Grenzen des Expertenwissens erweitern soll.
| Metrisch | Claude Opus 4.6 | GPT-5.3 Codex | Wer gewinnt? |
| Terminalbank 2.0 | 65.40% | 77.30% | GPT-5.3 Codex |
| SWE-bench Pro | Nicht offengelegt | 57.00% | GPT-5.3 Codex |
| OSWorld | 46.20% | 64.70% | GPT-5.3 Codex |
| GDPval-AA (Elo) | +144 gegenüber dem Basiswert | Ausgangswert | Claude Opus 4.6 |
| Die letzte Prüfung der Menschheit | Höchstpunktzahl | Nicht offengelegt | Claude Opus 4.6 |
| Kontextfenster | 1.000.000 Token | ~200.000 Token | Claude Opus 4.6 |
| Geschwindigkeitsverbesserung | Ausgangswert | 0.25 | GPT-5.3 Codex |
Analyse realweltlicher Szenarien: Welches Modell ist das richtige?
Basierend auf den oben genannten technischen Parametern und Daten empfehle ich für unterschiedliche berufliche Anforderungen Folgendes:
Wähle Claude Opus 4.6, wenn:
- Sie sind Softwarearchitekt: Es ist die optimale Wahl für die Refaktorisierung von Legacy-Projekten mit Hunderttausenden von Codezeilen.
- Sie arbeiten in Bereichen mit hohen Compliance-Anforderungen: Es eignet sich besser für den Finanz- oder Rechtsbereich, wo logische Präzision und die Einhaltung gesetzlicher Vorschriften unerlässlich sind.
- Sie dulden keinerlei „Halluzinationen“: In den jüngsten „Needle In A Haystack“-Tests erreichte die Langzeitkontext-Recall-Rate 76% und übertraf damit die Konkurrenz deutlich.
Wählen Sie den GPT-5.3-Codex, wenn:
- Sie sind ein Full-Stack-Entwickler: Es ist optimiert für maximale Entwicklungsgeschwindigkeit und Aufgaben, die eine häufige Interaktion mit Terminals, Datenbanken und Cloud-Plattformen erfordern.
- Sie bevorzugen die „Human-in-the-Loop“-Programmierung: Die Lenkung in der Kurvenmitte ist ideal für Entwickler, die den Logikablauf der KI durch einen kontinuierlichen Dialog anpassen möchten.
- Sie sind spezialisiert auf Cybersicherheit: Als erstes Modell mit der Klassifizierung „High-Level Cybersecurity Capability“ verfügt es über einen entscheidenden Vorteil bei der Erkennung und Abwehr von Schwachstellen.
Meine Schlussfolgerung hinsichtlich dieser gleichzeitigen Veröffentlichung ist, dass sich beide Unternehmen in Richtung „Langzeitaufgabenausführung“ und „agentenbasierte Entwicklung“ orientiert haben, wenn auch mit unterschiedlichen Schwerpunkten. Claude Opus 4.6 Es zeichnet sich durch extrem lange Kontexte, Sitzungsverwaltung (Kompaktierung) und Unternehmenskonformität aus. Umgekehrt GPT-5.3-Codex dominiert bei Benchmarks für Softwareentwicklung, Ausführungsgeschwindigkeit und langfristiger Werkzeugnutzung.
Für die Teamauswahl empfehle ich eine einfache Regel: Führen Sie einen A/B-Test mit Ihren internen Repositories durch. Erfassen Sie Erfolgsquote, Anzahl der Revisionen, Kosten und Lieferzeit, anstatt sich ausschließlich auf Benchmarks von Drittanbietern zu verlassen.
Für Einzelnutzer kann ein Abonnement beider Dienste extrem teuer sein. In diesem Fall empfehle ich die Verwendung eines Aggregators wie beispielsweise [Name des Aggregators einfügen]. iWeaverEs ermöglicht Ihnen den Zugriff auf beide Modelle unter einem einzigen Abonnement, sodass Sie nahtlos zwischen Claude und GPT wechseln können, bis Sie das für Ihre spezifische Aufgabe perfekt geeignete Modell gefunden haben.


