
Ich bewerte GLM-5 in erster Linie als IngenieurmodellNicht als allgemeines Chat-Modell, das sich nur „gut anhören“ muss. Mein Ansatz ist unkompliziert: Zuerst nutze ich vielzitierte öffentliche Benchmarks, um zu bestätigen, wo GLM-5 im Spitzenfeld liegt, dann validiere ich diese Signale mit einem wiederholbarer Arbeitsablauf um zu überprüfen, ob GLM-5 tatsächlich stabiler und praktischer für reale Ingenieuraufgaben ist. Basierend auf diesem Prozess komme ich zu dem Schluss, dass der Fortschritt von GLM-5 nicht nur die Skalierbarkeit betrifft, sondern auch die... Langzeitkontexteffizienz, Agentenschulung, Und Ausgangsstabilität in Ingenieursqualität Gleichzeitig. Diese Kombination trägt dazu bei, zu erklären, warum es sowohl in kombinierten Ranglisten als auch in realen agentenbasierten Evaluierungen nahezu so gut abschneidet wie führende geschlossene Modelle.
Ich verwende zwei Kennzahlen, um die Position von GLM-5 zu bestimmen.
Um mich nicht nur auf subjektive Eindrücke zu stützen, verankere ich meine Bewertung von GLM-5 in zwei sich ergänzenden Bewertungsansätzen der künstlichen Analyse:
- Künstliche Intelligenz-Index (Gesamtleistungswert): GLM-5-Werte 50, womit es in die Spitzengruppe fällt. Höhere Punktzahlen erzielt beispielsweise Claude Opus 4.6 (Adaptives Denken) bei 53 und GPT-5.2 (xhigh) bei 51, während Claude Opus 4.5 ebenfalls in der 50 Bereich. Dieser Index fasst mehrere Bewertungen zu einem einzigen Wert zusammen, der die Gesamtstärke in den Bereichen logisches Denken, Codierung und verwandte Fähigkeiten widerspiegelt.
- GDPval-AA (Agentenbewertung von Wissensarbeit in der realen Welt): GLM-5 hat ein Elo-Wertung von 1412Einfach ausgedrückt ist Elo ein relative Stärke im direkten VergleichEin höherer Elo-Wert bedeutet eine höhere Gesamterfolgsquote bei denselben Aufgaben. GDPval-AA ist so konzipiert, dass es reale Arbeitsprozesse simuliert (z. B. Informationsbeschaffung, -analyse und Ergebniserstellung) und ermöglicht es Modellen, in einer Agentenumgebung mit Zugriff auf entsprechende Werkzeuge zu arbeiten.
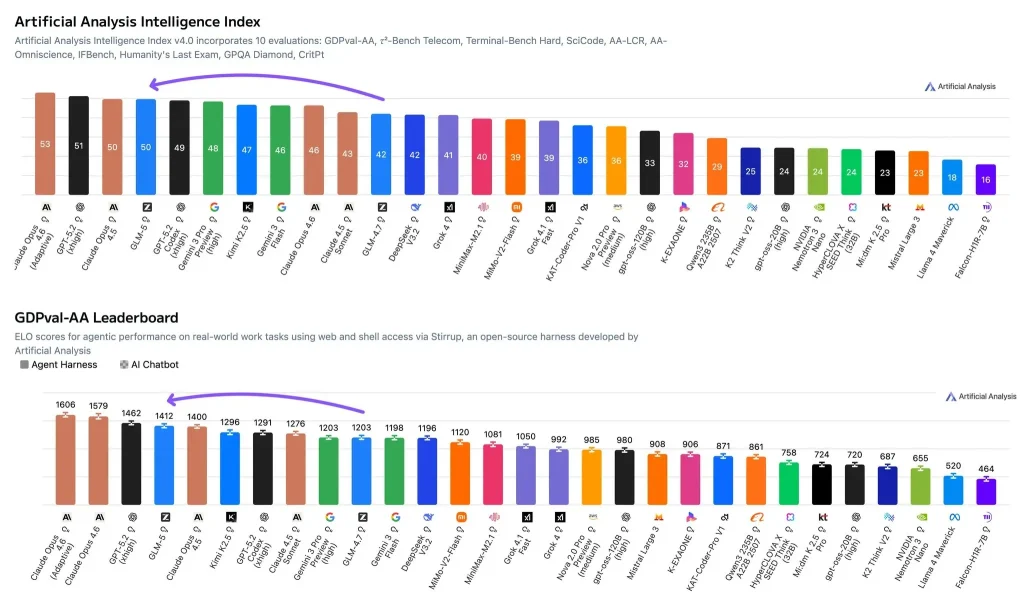
Zusammengenommen deuten diese beiden Kennzahlen auf eine klare Hypothese hin: Der Vorteil von GLM-5 dürfte nicht auf isolierten „Testset-Tricks“ beruhen. Vielmehr dürfte er sich in der Qualität der Ausführung und der Stabilität bei komplexen, mehrstufigen Aufgaben widerspiegeln.
Wie ich GLM-5 teste: Drei Arbeitsabläufe im Bereich Hochfrequenztechnik
Meine praktischen Tests ähneln eher einer technischen Abnahmeprüfung als einer reinen „Präsentation“. Ich konzentriere mich weniger darauf, ob das Modell längere Erklärungen liefern kann, sondern vielmehr darauf, ob es unter gegebenen Einschränkungen korrekte und nutzbare Ergebnisse liefert. Ich teste hauptsächlich drei Workflow-Typen:
- Aufgaben im Bereich der Softwareentwicklung mit Langzeitkontext: Ich stelle einen längeren Codeabschnitt sowie Dokumentationsvorgaben zur Verfügung und verlange die Lokalisierung von dateiübergreifenden Problemen und einen Lösungsvorschlag mit minimalen Änderungen.
- Inkrementelle Codeänderungen: Ich benötige Änderungen, die auf eine bestimmte Funktion oder ein bestimmtes Modul beschränkt sind, wobei der Rest der Struktur intakt bleiben soll, und ich bitte um einen Patch im Diff-Stil sowie um eine Risikobewertung für Regressionen.
- Werkzeugzentrierte Aufgabenketten: Ich strukturiere Aufgaben als Abrufen → Synthetisieren → Erstellen eines Liefergegenstands und prüfe, ob das Modell fehlende Eingaben klar anfordern und einen zuverlässigen Wiederholungspfad vorschlagen kann, wenn etwas fehlschlägt.
Ich nutze diese Arbeitsabläufe, weil sich Verbesserungen des Intelligenzindex und des BIP-Werts (AA) am deutlichsten zeigen sollten in lange Ketten, Werkzeugeinsatz und technische Ergebnisse anstatt in kurzen, einstufigen Aufforderungen.
Die wichtigsten Neuerungen von GLM-5: Eine strukturelle Verbesserung durch drei verstärkende Änderungen
DSA Sparse Attention Makes Long Context Economically Sustainable
In öffentlichen Materialien und der PapierGLM-5 betont die Übernahme von DSA (DeepSeek Sparse Attention)Vereinfacht ausgedrückt: Bei sehr langen Eingaben muss das Modell nicht mehr für jedes Token gleich viel Rechenleistung aufwenden. Stattdessen konzentriert es sich auf Tokens, die wahrscheinlich wichtiger und relevanter sind, wodurch die Kosten für Training und Inferenz reduziert werden, während gleichzeitig die Qualität des Langzeitkontexts erhalten bleibt.
In meinen Tests stimmt die praktische Konsequenz mit diesem Designziel überein: Mit zunehmendem Kontext, Die Latenz steigt tendenziell gleichmäßiger an., Und Die Ausgangskohärenz bleibt tendenziell stabiler.Dies ist im Entwicklungsumfeld von Bedeutung, da die Erkundung des Quellcodes, die Anhäufung von Anforderungen und die langfristige Ausführung den Kontext im Laufe der Zeit naturgemäß erweitern.
Asynchrone RL-Infrastruktur („Slime“) eignet sich besser für Interaktionen mit langem Zeithorizont
GLM-5 beschreibt öffentlich ein asynchrones Reinforcement-Learning-Setup, das die Trajektoriengenerierung (Rollout) vom Training entkoppelt, um Durchsatz und Effizienz zu verbessern. Praktisch bedeutet dies, dass das Modell aus großen Mengen an Interaktionsdaten effektiver lernen kann. wie man Aufgaben von Anfang bis Ende erledigt, anstatt nur zu lernen, Antworten zu produzieren, die für sich genommen plausibel erscheinen.
In praktischen Arbeitsabläufen sehe ich dies am deutlichsten bei der Fehlerbehandlung: Anstatt unproduktiven Text in einer Schleife zu wiederholen, kehrt GLM-5 häufiger zu den Einschränkungen zurück und schlägt Folgendes vor: neue ausführbare Schritteund es wird genauer angegeben, welche Eingaben fehlen.
Die Trainingsziele verlagern sich hin zu agentenbasierter Technik, nicht zu punktuellen Fertigkeitsverbesserungen.
GLM-5 positioniert sich explizit als ein Übergang von „promptgesteuerter Codierung“ hin zu AgententechnikIch interpretiere dies als ein Trainingsziel, das über das Schreiben von Code oder das Lösen isolierter Denkprobleme hinausgeht: Das Modell muss über längere Zeiträume planen, ausführen und reflektieren können, um Ergebnisse zu erzielen, die in technischen Arbeitsabläufen verwendbar sind.
Diese Herangehensweise hilft zu erklären, warum GLM-5 bei GDPval-AA (Aufgaben von Wissensarbeitern) stark abschneiden und gleichzeitig beim Gesamtindex der Intelligenz wettbewerbsfähige Werte erzielen kann.
Warum das GLM-5 immer noch „knapp hinter“ geschlossenen Flaggschiffen rangiert: Der Abstand ist kleiner, aber nicht null.
GLM-5 befindet sich bereits in derselben Spitzengruppe.
A 50 Der Intelligenzindex deutet darauf hin, dass die Gesamtbewertung keine wesentlichen Schwächen aufweist – andernfalls wäre es schwierig, ein Ergebnis auf diesem Niveau zu halten. Es liegt im selben Bereich wie Claude Opus 4.5 und etwas unter Claude Opus 4.6 (Adaptives Denken) und GPT-5.2 (extrem hoch).
GLM-5 ist bei realen Wissensarbeiten nah an Flaggschiffprodukten dran. Agent Aufgaben
Ein Elo-Wert von 1412 Die Ergebnisse von GDPval-AA deuten auf hohe relative Erfolgsquoten bei wissensbasierten Aufgaben mit Werkzeugeinsatz hin. Für Implementierungsentscheidungen ist dies oft aussagekräftiger als eine statische Genauigkeit anhand eines eng gefassten Benchmarks, da viele Produktionsszenarien die Datenabfrage, -analyse, -dokumentation und Werkzeugkoordination umfassen.
Verbleibende Unterschiede zeigen sich in extremen Schwierigkeiten und im Reifegrad der Politik.
Geschlossene Flaggschiffmodelle weisen oft Vorteile hinsichtlich der ausgereiften Richtlinien auf: konsistentere Selbstprüfung, zuverlässigere Ablehnungsgrenzen und weniger Fehler in Sonderfällen. GLM-5 kann sich diesem Niveau annähern, benötigt aber für eine Teilmenge komplexer Aufgaben möglicherweise noch klarere Beschränkungen oder stärkere Systemvorkehrungen, um konsistente Ergebnisse zu erzielen.
Vorteile, die ich in der Praxis bestätigen kann: GLM-5 verhält sich eher wie ein technischer Copilot als wie ein Chatbot.
Zuverlässigere inkrementelle Bearbeitungen, weniger unnötige Überarbeitungen
Wenn ich lokale Änderungen benötige, die die umgebende Struktur aber erhalten sollen, erzeugt GLM-5 häufiger gezielte Ersetzungen oder Diff-ähnliche Bearbeitungen, anstatt ganze Module neu zu schreiben. Dadurch wird der Prüfaufwand reduziert und das Risiko von Regressionen lässt sich leichter beherrschen.
Bessere Konsistenz der Nebenbedingungen über längere Aufgabenketten hinweg
Wenn ich eine Aufgabe auf mehrere Durchgänge aufteile und strenge Einschränkungen aus früheren Schritten durchsetze, ist es wahrscheinlicher, dass GLM-5 diese Einschränkungen konsistent hält, wenn der Kontext wächst, wodurch widersprüchliche Annahmen reduziert werden.
Besser ausführbare Toolchain-Ausgaben und verbesserte Wiederherstellung nach Fehlern
In den Workflows „Abrufen → Synthetisieren → Bereitstellen“ konzentriere ich mich darauf, ob das Modell ausführbare Schritte und eine klare Checkliste für fehlende Eingaben generieren kann. GLM-5 treibt den Workflow häufiger voran, als auf der Erklärungsebene zu verharren.
Zu kennende Einschränkungen: Was kann die Produktionsübernahme blockieren?
Die Kosten für Bereitstellung und Systeme sind immer noch hoch
GLM-5 ist ein MoE-Modell der Spitzenklasse. Selbst wenn nur ein Teil des Modells pro Token aktiviert wird, erfordert das Self-Hosting noch erhebliche Anstrengungen in den Bereichen Speicherplanung, Parallelverarbeitungsplanung, KV-Cache-Strategie, Quantisierung und Kompatibilität mit Inferenzmaschinen.
Es wird nicht automatisch in jedem spezialisierten Marktsegment gewinnen.
Der Intelligenzindex und GDPval-AA gewichten allgemeine Denkprozesse und Wissensarbeitsaufgaben stärker. Ist Ihr Anwendungsbereich hochspezialisiert – beispielsweise strenge Compliance-Workflows, spezielle formale mathematische Beweise oder extrem detaillierte Stilvorgaben –, sollten Sie dennoch gezielte A/B-Tests durchführen, bevor Sie eine endgültige Entscheidung treffen.
Ein solides Modell ersetzt kein solides System-Engineering.
Bei agentenbasierten Implementierungen ist der häufigste Fehler nicht „Das Modell kann nicht antworten“, sondern „Die Ausführungskette wird nicht kontrolliert“. Werkzeugberechtigungen, Sicherheitsisolation, Beobachtbarkeit, Wiederholungslogik und Nachweisprüfung bleiben notwendig, um die Modellfähigkeit in eine stabile Produktionsleistung umzusetzen.
Wann ich GLM-5 priorisieren würde
Wenn mein Ziel darin besteht, dass ein Modell einen sinnvollen Teil eines technischen Arbeitsablaufs abdeckt (und nicht nur einmalige Ergebnisse liefert), ist GLM-5 ein erstklassiger Kandidat, insbesondere für:
- Langfristige Entwicklungsaufgaben: Dateiübergreifendes Debugging, Refactoring, Lokalisierung komplexer Probleme
- Werkzeugzentrierte Arbeitsabläufe: Datenabruf, Skripterstellung, Datensynthese, Dokumentenerstellung
- Anforderungen an die offenen Gewichtsklassen: Lokale Bereitstellung, Anpassung und engere Kosten-/Kontrollgrenzen
Wenn Ihre Arbeitslast hauptsächlich aus kurzen Frage-Antwort-Runden besteht, Sie extrem kostensensibel sind oder unter sehr strengen Compliance-Vorgaben arbeiten und keine systemweiten Schutzmechanismen wünschen, würde ich mit leichteren Modellen oder geschlossenen Flaggschiffen als Basis beginnen und GLM-5 nur dann hinzufügen, wenn es einen klaren Nutzen bringt.


