As question answering systems become more advanced, developers are exploring new techniques to boost their performance. One promising approach is the RAG (Retrieval-Augmented Generation) model, which combines information retrieval and generative language capabilities. By fine-tuning the embedding used for retrieval of domain-specific data, researchers have found a way to significantly improve RAG models’ answer accuracy. This article dives into the details of this technique.
Introduction to RAG
To better understand why tuning embeddings is so effective for RAG models, we first need to cover some background on RAG itself.
What is RAG?
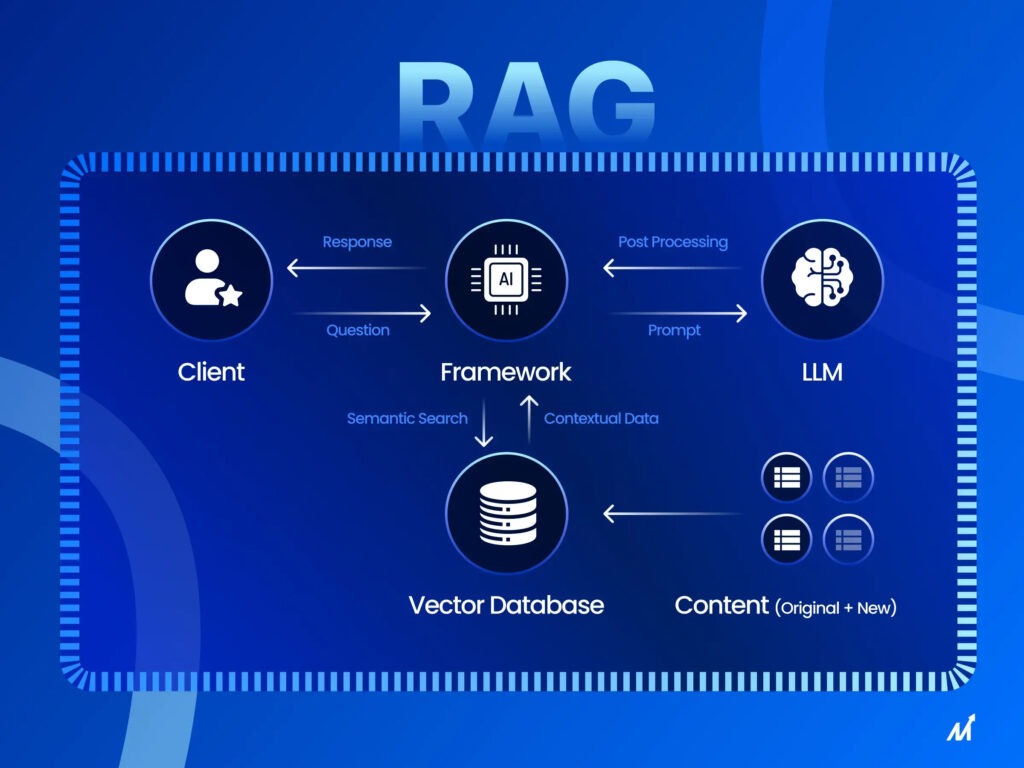
RAG stands for Retrieval-Augmented Generation. It’s a method that combines information retrieval with generative models. A RAG model first retrieves relevant information, then generates an answer based on that information. This boosts the model’s ability to answer complex questions. It has two parts: a retriever and a generator. The retriever pulls relevant snippets from a large document corpus based on the question. The generator then uses those snippets to generate a coherent answer. This approach works better for open-domain question answering because it can dynamically fetch the latest information.
Pros and Limitations of RAG Models
Compared to traditional text retrieval and generative models, RAG models have some advantages:
- Can provide more accurate and useful search results
- Can handle complex queries and long texts
- Can generate personalized search results based on user intent
However, RAG models also have some limitations:
- Training and inference are computationally expensive
- High requirements for training data and model capacity
- Difficulty handling queries and texts from specialized domains
The Role of Embeddings in RAG
With the basics of RAG covered, let’s dive into how embeddings play a crucial role and can be optimized.

Recall Comparison of Different Embedding Models on Domain Data
This experiment used 30,000+ knowledge snippets and 600 standard user questions for recall testing. We mainly compared the recall performance of m3e-base, bge-base-zh, and bce-embedding-base_v1 models on Chinese and English input data.
Fine-tuning the Embedding Model on Domain Data
- Data Collection: Collect sufficient domain-related data, including documents, Q&A pairs, etc. This data should cover key knowledge points and common questions in the domain.
- Preprocessing: Clean and preprocess the data to remove noise and redundancy, ensuring data quality.
- Fine-tuning: Fine-tune a pre-trained embedded model (e.g., BERT) on the domain data. Continuing training on domain data helps the model better adapt to the semantics and language usage in that domain.
- Evaluation & Optimization: Evaluate the fine-tuned Embedding model’s performance in RAG, and adjust training parameters and datasets as needed to further optimize performance.
Through fine-tuning, the Embedding model can better understand domain-specific semantics, thereby improving the retrieval and generation capabilities of the RAG model and boosting answer rates and quality.
Taking the m3e model as an example:
Download: https://huggingface.co/moka-ai/m3e-base
Fine-tuning reference: https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
After fine-tuning on domain data and re-testing recall, we saw a direct 33% increase in recall rate – a very promising result.
Conclusion
Fine-tuning the Embedding model is an effective way to improve RAG answer rates. By fine-tuning on domain data, the Embedding model can better understand domain-specific semantics, thereby boosting the overall performance of the RAG model. Although RAG models have significant advantages in open-domain QA, their performance in specific domains still needs further optimization. Future research could explore more fine-tuning methods and data quality improvements to further enhance RAG models’ answer accuracy and usability across domains.