
Cosa ha effettivamente rilasciato Alibaba con Qwen 3.5: chiarimento sulla gamma delle versioni
A mio avviso, il primo passo per comprendere Alibaba Qwen 3.5 è separare chiaramente il modello a peso aperto dal ospitato nel cloud API offerta:
- Qwen3.5-397B-A17B: Il modello open-weight. Alibaba fornisce le specifiche principali di Hugging Face, come 397B parametri totali, 17B attivati per token, E 60 strati.
- Qwen3.5-Plus: La versione API ospitata su Alibaba Cloud Model Studio. Alibaba indica che corrisponde al modello 397B-A17B e aggiunge funzionalità di produzione come una finestra di contesto predefinita da 1M token, strumenti integrati, E invocazione dello strumento adattivo.
Questa distinzione si ripete ripetutamente in Reddit discussioni. Molte persone confondono Più, il modello open-weight e le “estensioni di strumenti/contesto”, che aumentano la confusione durante la valutazione.
Cosa vedo come aggiornamenti principali in Qwen 3.5
Raggruppo gli aggiornamenti in due categorie: cambiamenti fondamentali a livello di modello E ottimizzazioni ingegneristiche per l'efficienza. Messaggistica pubblica evidenzia anche costo inferiore, maggiore produttivitàe un focus su IA agentica.
MoE estremamente sparso
MoE (Mixture of Experts) può essere inteso come un'architettura modello con molte sottoreti "esperte". Durante l'inferenza, un meccanismo di routing attiva solo un piccolo sottoinsieme di esperti, invece di eseguire tutti i parametri ogni volta. I principali vantaggi sono:
- Elevato conteggio totale dei parametri: maggiore capacità del modello (più modelli il modello può rappresentare).
- Piccolo conteggio dei parametri attivati: il calcolo dell'inferenza è più vicino a un modello più piccolo, il che può migliorare la produttività e ridurre i costi.
Per Qwen3.5-397B-A17B, i numeri elencati pubblicamente sono 397B parametri totali E 17B attivatoReuters riporta anche le affermazioni di Alibaba su costi di utilizzo inferiori e maggiore produttività rispetto alla generazione precedente, incluse affermazioni come "circa 60% più economico" e una migliore capacità di gestire carichi di lavoro più pesanti.
Quando valuto il MoE nella pratica, considero i vantaggi in due modi: (1) con lo stesso budget è possibile utilizzare un modello a capacità più elevata e (2) con lo stesso obiettivo di throughput è possibile ridurre l'utilizzo di risorse di calcolo. Tuttavia, questi vantaggi dipendono da un routing efficace, dalla parallelizzazione e da un training stabile. In caso contrario, i sistemi MoE possono presentare variazioni di qualità o instabilità del servizio.
Previsione congiunta multi-token nativa
I modelli autoregressivi tradizionali prevedono un token successivo per passaggioL'obiettivo di previsione congiunta multi-token è quello di produrre previsioni per molteplici posizioni future in un unico passaggio in avanti, addestrando esplicitamente il modello per mantenere coerenti tali previsioni.
Ecco l'impatto pratico sulla velocità di inferenza in termini semplici:
- Se il modello riesce a "guardare avanti" in modo affidabile e a prevedere più token contemporaneamente, e una politica di accettazione mantiene solo output ad alta confidenza, può ridurre il numero di passaggi di decodifica.
- Un minor numero di passaggi di decodifica solitamente aumenta la produttività, soprattutto per output lunghi o carichi di lavoro di lungo contesto.
Alcuni schede modello di terze parti e i riassunti degli ecosistemi trattano anche previsione multi-token come fattore importante alla base dei guadagni di produttività di Qwen 3.5.
Quando valuto questa tecnica, mi concentro su due aspetti: se la strategia di accettazione è stabile e come si comporta in caso di campionamento a bassa temperatura rispetto ad alta temperatura. Nella mia esperienza, lunghi carichi di lavoro di preriempimento e un'elevata concorrenza tendono a evidenziare l'instabilità prima.
Multimodalità nativa
Blog ufficiale Qwen di Alibaba posizioni Qwen 3.5 come “agenti multimodali nativi”, sottolineandolo come un modello di linguaggio visivo nativo progettato per la comprensione di immagini/video e flussi di lavoro degli agenti.
Riassumo il valore della multimodalità nativa come segue:
- La vista e il linguaggio vengono addestrati nello stesso spazio di parametri, il che può facilitare il contributo dei segnali visivi al ragionamento, all'uso degli strumenti e alle successive decisioni d'azione.
- È più in linea con le attività degli "agenti visivi". Reuters menziona anche funzionalità relative all'esecuzione di attività su applicazioni mobili e desktop.
Come interpreto il profilo delle capacità di Qwen 3.5: punti di forza e limiti
Sconsiglio di basarsi su uno o due risultati della classifica. Un approccio più utile è quello di suddividere le competenze in categorie che corrispondono alle attività aziendali.
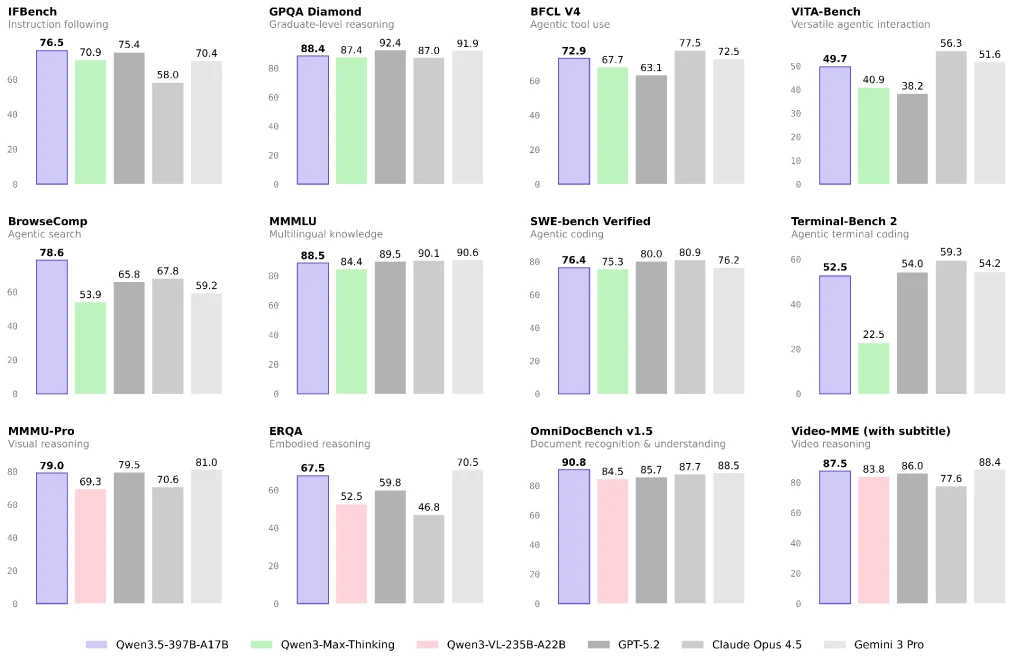
Linguaggio e ragionamento generale: vicino al livello superiore del modello chiuso, ma il mix di attività è importante
Le segnalazioni ufficiali e di terze parti suggeriscono che Qwen 3.5 offre ottime prestazioni nei benchmark multilinguaggio/ragionamento e sottolinea l'elevata capacità per costo unitario.
Se il tuo carico di lavoro è principalmente basato su domande e risposte di tipo knowledge, generazione di contenuti o analisi generale, Qwen 3.5 può essere un'ottima opzione in termini di rapporto qualità-prezzo. Consiglio comunque di eseguire un piccolo test A/B sul tuo mix di attività di produzione reale, invece di basarti solo sui benchmark.
Visione, documenti e video: un'area di interesse chiara per Qwen 3.5
Qwen3.5-397B-A17B è classificato su Hugging Face come modello con capacità di visione e il blog di Alibaba lo inquadra nei casi d'uso degli agenti multimodali.
Se la tua candidatura include quanto segue, ritengo che valga la pena dare priorità alla valutazione di Qwen 3.5:
- Comprensione del layout di documenti complessi e pipeline OCR-ragionamento
- Ragionamento visivo, grafici e tabelle
- Input video lungo per riepiloghi strutturati o estrazione di informazioni (a seconda che si utilizzi Qwen3.5-Plus e le sue capacità contestuali)
Agenti e utilizzo degli strumenti: separo gli “agenti di ricerca” dagli “agenti di strumenti generali”
Le “prestazioni degli agenti” variano notevolmente sia nella valutazione che nelle distribuzioni reali:
- Agenti di ricerca dipendono fortemente dalla strategia di recupero, dalle politiche di ripiegamento/compressione del contesto e dall'orchestrazione degli strumenti. Le discussioni della community evidenziano inoltre che strategie diverse possono produrre notevoli differenze nei punteggi.
- Agenti di strumenti generali dipendono maggiormente dai protocolli degli strumenti, dal ripristino degli errori, dalla stabilità a lungo termine e dai limiti delle autorizzazioni.
Reuters sottolinea i miglioramenti di Qwen 3.5 nell'esecuzione di attività su app mobili e desktop, il che in genere implica investimenti significativi in "agenti visivi + strumenti".
Costi e accesso: come sceglierei tra le opzioni
Se vuoi il percorso più veloce verso la produzione, inizierei con Qwen3.5-Plus
La mia ragione è semplice: Più viene fornito con impostazioni predefinite orientate alla produzione come una finestra di contesto da 1M token, strumenti integrati, E invocazione dello strumento adattivo.
Alibaba Cloud Model Studio fornisce anche prezzi dei token a livelli (i prezzi variano in base al contesto).
Se hai bisogno di controllo della conformità e proprietà prevedibile, i pesi aperti potrebbero essere più adatti, ma con costi di progettazione più elevati
Quando scelgo i pesi aperti, divido il costo in tre parti:
- Calcolo dell'inferenza e memoria (MoE può essere sensibile alla parallelizzazione e al supporto del framework)
- Strumenti e allineamento (recupero/esplorazione, esecuzione del codice, isolamento dei permessi)
- Garanzia di qualità (set di valutazione, test di regressione, monitoraggio e ripristino)
Il mio flusso di lavoro di convalida consigliato per una distribuzione reale
- Definisci la proporzione di tre tipi di attività: testo Q&A / documento e visione / strumenti e ricerca
- Correggere i vincoli di input/output: lunghezza del contesto, tolleranza dello strumento e se sono necessarie citazioni
- Utilizzare un unico quadro di valutazione su due percorsi:
- Percorso A: Qwen3.5-Plus (ottenere rapidamente una linea di base)
- Percorso B: Peso aperto 397B-A17B (misurare i costi e la stabilità dell'auto-hosting)
- Concentrarsi sui casi di errore: guasti degli strumenti in lunghe catene, errori di comprensione dei documenti e perdita di informazioni causata dalle strategie di ricerca
Sulla base delle informazioni pubbliche, vedo la direzione Qwen 3.5 di Alibaba come un passaggio da un "modello di chat" verso multimodalità + strumenti + esecuzione cross-device per flussi di lavoro agentici, durante l'utilizzo MoE sparso E previsione multi-token per ridurre i costi di inferenza e aumentare la produttività.
Se la tua attività prevede la comprensione dei documenti, il ragionamento visivo, la ricerca o flussi di lavoro inter-applicazione, penso che Qwen 3.5 dovrebbe essere nella tua prima rosa di valutazione. Se le tue esigenze principali sono la matematica a livello competitivo o il ragionamento estremo, ti consiglio un confronto più rigoroso, attività per attività, con altri modelli di punta prima di decidere una strategia di modello primario/di backup.
FAQ: le domande che ricevo più spesso durante la valutazione
D1: Qual è la differenza tra Qwen 3.5 e modelli come “Qwen 3 Max-Thinking”?
Interpreto le differenze in due dimensioni:
- Posizionamento: Qwen 3.5 pone maggiore enfasi sulla multimodalità nativa e sui flussi di lavoro agentici.
- Forma del prodotto: Plus è un'offerta "migliorata" ospitata che spesso include impostazioni predefinite per contesto, strumenti e policy. Questo è anche il motivo per cui alcuni utenti della community ritengono che le relazioni tra le versioni non siano chiare.
D2: Perché dovrei preoccuparmi del "MoE estremamente sparso"?
Perché influisce direttamente sul costo per richiesta e sul limite di throughput. Per Q&A ad alta concorrenza e analisi di contesto prolungate, questa architettura ha maggiori probabilità di generare un traffico maggiore entro un budget fisso. I parametri e i dettagli strutturali sono chiaramente indicati nella scheda del modello.
D3: La previsione congiunta multi-token danneggerà la qualità della generazione?
L'obiettivo è ridurre i passaggi di decodifica e migliorare la produttività, ma l'impatto sulla qualità dipende dalle politiche di addestramento e inferenza. Il mio consiglio è di testare separatamente le attività di output di lunga durata e quelle di campionamento ad alta casualità, evitando di trarre conclusioni da un singolo benchmark.


