
O que a Alibaba realmente lançou com o Qwen 3.5: esclarecendo a lista de versões.
Na minha opinião, o primeiro passo para compreender Alibaba Qwen 3.5 é separar claramente o modelo de peso aberto do hospedado na nuvem API oferta:
- Qwen3.5-397B-A17BO modelo de peso aberto. A Alibaba fornece as especificações principais do Hugging Face, como: 397 bilhões de parâmetros totais, 17 bilhões ativados por token, e 60 camadas.
- Qwen3.5-PlusA versão da API está hospedada no Alibaba Cloud Model Studio. A Alibaba indica que ela corresponde ao modelo 397B-A17B e adiciona recursos de produção como uma janela de contexto padrão de 1 milhão de tokens, ferramentas integradas, e invocação de ferramenta adaptativa.
Essa distinção surge repetidamente em Reddit discussões. Muitas pessoas confundem Mais, o modelo de peso aberto e as “extensões de ferramentas/contexto”, o que aumenta a confusão durante a avaliação.
O que eu considero as principais melhorias no Qwen 3.5
Eu divido as melhorias em duas categorias: mudanças fundamentais no nível do modelo e otimizações de engenharia para eficiência. Mensagens públicas também destaca custo mais baixo, maior capacidade de processamentoe um foco em IA agente.
MoE extremamente esparso
MoE (Misto de Especialistas) Pode ser entendido como uma arquitetura de modelo com muitas sub-redes "especialistas". Durante a inferência, um mecanismo de roteamento ativa apenas um pequeno subconjunto de especialistas, em vez de executar todos os parâmetros a cada vez. Os principais benefícios são:
- Contagem total de parâmetros elevada: maior capacidade do modelo (mais padrões o modelo pode representar).
- Contagem de parâmetros ativados pequenaA computação de inferência está mais próxima de um modelo menor, o que pode melhorar a produtividade e reduzir custos.
Para Qwen3.5-397B-A17B, os números divulgados publicamente são 397 bilhões de parâmetros totais e 17B ativado(Cara de Abraço) A Reuters também relata as alegações do Alibaba de Custo de utilização mais baixo e maior capacidade de processamento. Em comparação com a geração anterior, isso inclui afirmações como "cerca de 60% mais barato" e capacidade aprimorada para lidar com cargas de trabalho mais pesadas.
Ao avaliar o MoE na prática, considero os benefícios de duas maneiras: (1) com o mesmo orçamento, é possível usar um modelo de maior capacidade e (2) com a mesma meta de throughput, é possível reduzir o uso de poder computacional. No entanto, esses ganhos dependem de roteamento robusto, paralelização e treinamento estável. Caso contrário, os sistemas MoE podem apresentar variações de qualidade ou instabilidade de serviço.
Previsão conjunta nativa de múltiplos tokens
Os modelos autorregressivos tradicionais preveem um token seguinte por passoO objetivo de previsão conjunta de múltiplos tokens é produzir previsões para múltiplas posições futuras em uma única passagem direta, enquanto o modelo é explicitamente treinado para manter essas previsões consistentes.
Eis o impacto prático na velocidade de inferência em termos simples:
- Se o modelo conseguir "prever" e predizer vários tokens simultaneamente de forma confiável, e uma política de aceitação mantiver apenas as saídas de alta confiança, ele poderá reduzir o número de etapas de decodificação.
- Menos etapas de decodificação normalmente aumentam a taxa de transferência, especialmente para saídas longas ou cargas de trabalho com contexto extenso.
Alguns cartões de modelo de terceiros e os resumos do ecossistema também tratam de previsão de múltiplos tokens como um fator importante por trás dos ganhos de desempenho do Qwen 3.5.
Ao avaliar essa técnica, foco em dois aspectos: se a estratégia de aceitação é estável e como ela se comporta em condições de amostragem de baixa e alta temperatura. Na minha experiência, longas cargas de trabalho de pré-preenchimento e alta concorrência tendem a expor a instabilidade mais cedo.
Multimodalidade Nativa
Blog oficial do Qwen da Alibaba posições Qwen 3.5 como “Agentes Multimodais Nativos”, enfatizando-o como um modelo nativo de visão-linguagem Projetado para compreensão de imagens/vídeos e fluxos de trabalho de agentes.
Resumo o valor da multimodalidade nativa da seguinte forma:
- A visão e a linguagem são treinadas no mesmo espaço de parâmetros, o que pode facilitar a contribuição dos sinais visuais para o raciocínio, o uso de ferramentas e as decisões de ação subsequentes.
- Está mais alinhado com tarefas de "agente visual". A Reuters também menciona recursos relacionados à execução de tarefas em aplicativos para dispositivos móveis e computadores.
Como interpreto o perfil de capacidades do Qwen 3.5: pontos fortes e limitações
Não recomendo confiar em um ou dois resultados de rankings. Uma abordagem mais útil é dividir as competências em categorias que correspondam às suas tarefas de negócio.
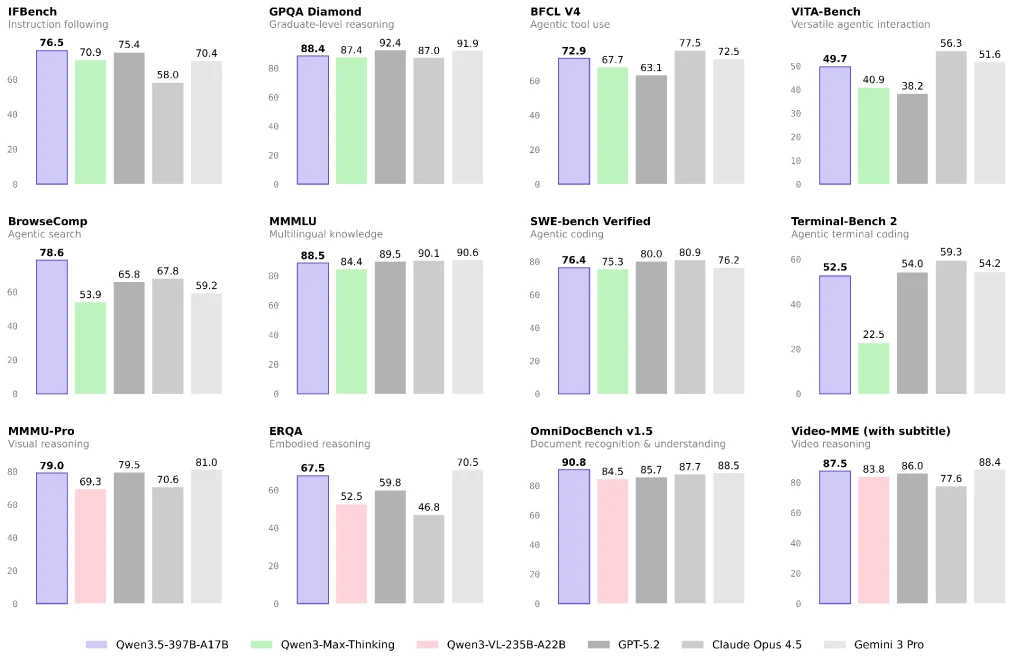
Linguagem e Raciocínio Geral: Próximos ao Nível Superior dos Modelos Fechados, mas a Combinação de Tarefas Importa
Relatórios oficiais e de terceiros sugerem que o Qwen 3.5 apresenta um desempenho sólido em vários benchmarks de linguagem/raciocínio e enfatiza a alta capacidade por unidade de custo.
Se sua carga de trabalho consiste principalmente em perguntas e respostas sobre conhecimento, geração de conteúdo ou análises em geral, o Qwen 3.5 pode ser uma opção com excelente custo-benefício. Ainda assim, recomendo realizar um pequeno teste A/B com suas tarefas reais de produção, em vez de tirar conclusões baseadas apenas em benchmarks.
Visão, Documentos e Vídeo: Uma Área de Foco Clara para o Qwen 3.5
O modelo Qwen3.5-397B-A17B é categorizado no Hugging Face como um modelo com capacidade de visão computacional, e o blog da Alibaba o descreve para casos de uso de agentes multimodais.
Se sua aplicação incluir o seguinte, acredito que o Qwen 3.5 mereça ser priorizado para avaliação:
- Compreensão de layouts de documentos complexos e fluxos de trabalho de OCR para raciocínio.
- Raciocínio visual, gráficos e tabelas
- Entrada de vídeo longo para sumarização estruturada ou extração de informações (dependendo se você usar Qwen3.5-Plus e suas capacidades contextuais)
Agentes e uso de ferramentas: Separando “agentes de busca” de “agentes de ferramentas gerais”
O "desempenho do agente" varia bastante tanto nas avaliações quanto nas implementações reais:
- Agentes de busca Dependem muito da estratégia de recuperação, das políticas de dobramento/compressão de contexto e da orquestração de ferramentas. Discussões na comunidade também apontam que diferentes estratégias podem produzir grandes diferenças de pontuação.
- Agentes de ferramentas gerais dependem mais dos protocolos das ferramentas, da recuperação de erros, da estabilidade a longo prazo e dos limites de permissão.
A Reuters destaca as melhorias do Qwen 3.5 na execução de tarefas em aplicativos para dispositivos móveis e desktops, o que normalmente implica em investimentos significativos em "agentes visuais e ferramentas".
Custo e Acesso: Como eu escolheria entre as opções
Se você quer o caminho mais rápido para a produção, eu começaria com o Qwen3.5-Plus.
Meu motivo é simples: Mais vem com configurações padrão voltadas para produção, como: uma janela de contexto de 1 milhão de tokens, ferramentas integradas, e invocação de ferramenta adaptativa.
Estúdio de Modelos da Alibaba Cloud Também oferece preços escalonados para os tokens (os preços variam de acordo com o contexto).
Se você precisa de controle de conformidade e previsibilidade de propriedade, os pesos livres podem ser mais adequados, mas com um custo de engenharia mais elevado.
Ao escolher pesos livres, divido o custo em três partes:
- Computação e memória de inferência (o MoE pode ser sensível à paralelização e ao suporte da estrutura).
- Ferramentas e alinhamento (recuperação/navegação, execução de código, isolamento de permissões)
- Garantia de qualidade (conjuntos de avaliação, testes de regressão, monitoramento e recuperação)
Meu fluxo de trabalho de validação recomendado para implantação real.
- Defina a proporção de três tipos de tarefas: perguntas e respostas por texto / documentos e visualização / ferramentas e pesquisa
- Corrigir restrições de entrada/saída: comprimento do contexto, permissão de ferramentas e se as citações são obrigatórias.
- Utilize uma única estrutura de avaliação para duas vias:
- Rota A: Qwen3.5-Plus (obter uma linha de base rapidamente)
- Rota B: Peso aberto 397B-A17B (medir o custo e a estabilidade da hospedagem própria)
- Foco em casos de falha: falhas de ferramentas em longas cadeias, erros de interpretação de documentos e perda de informações causada por estratégias de busca.
Com base em informações públicas, vejo a direção do Qwen 3.5 da Alibaba como uma transição de um "modelo de bate-papo" para... multimodalidade + ferramentas + execução em vários dispositivos para fluxos de trabalho agentes, enquanto usa MoE esparso e previsão de múltiplos tokens Para reduzir o custo de inferência e aumentar a produtividade.
Se sua empresa utiliza ferramentas como compreensão de documentos, raciocínio visual, busca ou fluxos de trabalho entre aplicativos, acredito que o Qwen 3.5 deva estar entre as suas principais opções de avaliação. Por outro lado, se suas necessidades principais envolvem matemática de nível competitivo ou raciocínio complexo, sugiro uma comparação mais rigorosa, tarefa por tarefa, com outros modelos de ponta antes de definir uma estratégia de modelo principal/de backup.
Perguntas frequentes: As perguntas que mais recebo durante a avaliação.
P1: Qual a diferença entre o Qwen 3.5 e modelos como o “Qwen 3 Max-Thinking”?
Interpreto as diferenças em duas dimensões:
- PosicionamentoO Qwen 3.5 dá mais ênfase à multimodalidade nativa e aos fluxos de trabalho com agentes.
- Formulário do produtoO Plus é uma oferta hospedada "aprimorada" que geralmente inclui configurações padrão para contexto, ferramentas e políticas. É por isso que alguns usuários da comunidade acham que as relações entre as versões não são claras.
Q2: Por que eu deveria me importar com "MoE extremamente esparso"?
Porque afeta diretamente o custo por requisição e o limite de throughput. Para processos de perguntas e respostas com alta concorrência e análises de contexto extenso, essa arquitetura tem maior probabilidade de gerar um tráfego mais elevado dentro de um orçamento fixo. Os parâmetros e detalhes estruturais estão claramente descritos no cartão do modelo.
Q3: A previsão conjunta de múltiplos tokens prejudicará a qualidade da geração?
O objetivo é reduzir as etapas de decodificação e melhorar o desempenho, mas o impacto na qualidade depende das políticas de treinamento e inferência. Minha recomendação é testar tarefas de saída de formato longo e tarefas de amostragem com alta aleatoriedade separadamente, evitando tirar conclusões a partir de um único benchmark.

