我主要从以下方面评估 GLM-5: 工程模型,并非将其视为一个只需“听起来正确”的通用聊天模型。我的方法很简单:首先,我使用广泛引用的公开基准来确认 GLM-5 在顶级模型中的位置,然后,我通过以下方式验证这些信号: 可重复的工作流程 为了检验 GLM-5 是否真的更稳定、更适用于实际工程任务。基于此过程,我的结论是 GLM-5 的进步不仅体现在规模上,还体现在其他方面。 长上下文效率, 代理人培训, 和 工程级输出稳定性 同时,这种组合有助于解释为什么它在综合排行榜和真实世界的智能体评估中都表现出色,接近领先的封闭式模型。
我使用两个指标来确定 GLM-5 的位置
为了避免仅依赖主观印象,我将对 GLM-5 的评估建立在两个互补的人工分析评估路径之上:
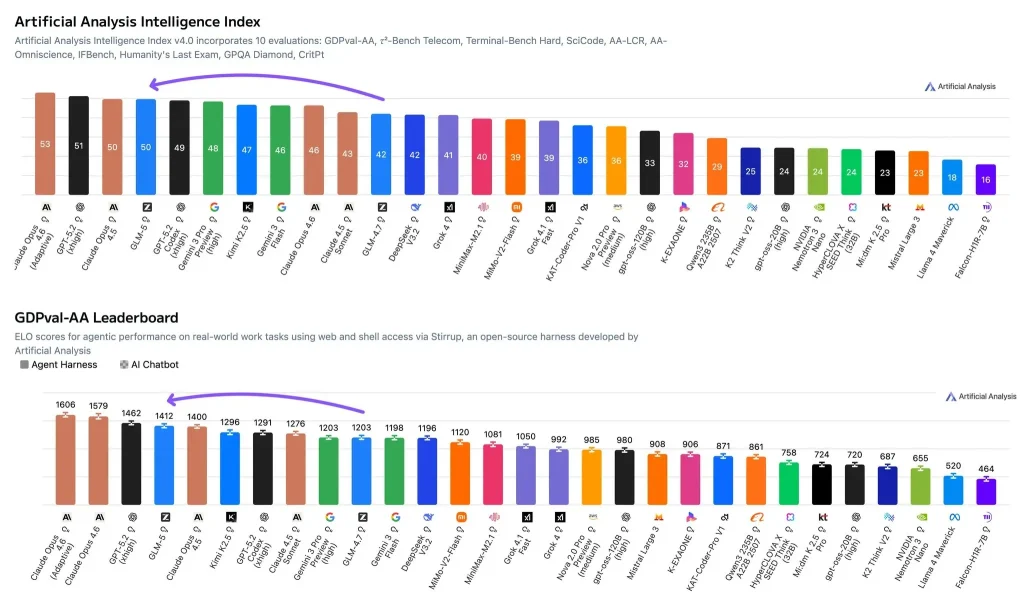
- 人工智能分析指数 (综合能力评分): GLM-5 得分 50这使其跻身顶尖行列。更高的分数包括 Claude Opus 4.6(自适应推理)。 53 以及 GPT-5.2 (xhigh) 51而克劳德作品4.5也在其中。 50 范围。该指数将多项评估结果汇总成一个单一分数,反映推理、编码和相关能力的整体实力。
- GDPval-AA (现实世界知识工作主体性评估): GLM-5 具有 Elo 等级分为 1412 分简单来说,Elo 是一种 正面相对实力得分更高的 Elo 值意味着在同一任务集中更高的总体胜率。GDPval-AA 的设计旨在模拟真实工作(例如,检索信息、分析信息和生成成果),并且允许模型在具有工具访问权限的代理框架中运行。
综合来看,这两个指标指向一个明确的假设: GLM-5的优势不太可能来自孤立的“测试集技巧”,而更有可能来自其在复杂、多步骤任务中的完成质量和稳定性。
我如何测试 GLM-5:三种高频工程工作流程
我的实践测试更像是工程验收检查,而不是“快速展示”。我不太关注模型能否生成更长的解释,而更关注它能否在约束条件下提供正确、可用的结果。我主要测试三种工作流程类型:
- 长上下文软件工程任务: 我提供了一段更长的代码片段以及文档要求,并要求进行跨文件问题定位,以及提出一个最小改动的修复方案。
- 代码增量修改: 我需要对特定功能或模块进行更改,保持其余结构不变,并要求提供 diff 样式的补丁以及回归风险说明。
- 以工具为中心的任务链: 我将任务结构化为检索→综合→生成交付物,并检查模型是否可以清晰地请求缺失的输入,并在出现故障时提出可靠的重试路径。
我使用这些工作流程是因为智能指数和GDPval-AA的改进应该最明显地体现在以下方面: 长链、工具使用和工程交付成果 而不是简短的、单轮提示。
GLM-5 的核心突破:三大强化变革带来的结构性升级
DSA稀疏注意力机制使长上下文在经济上可持续
在公共材料中和 纸GLM-5强调采用 DSA(DeepSeek稀疏注意力)简单来说:当输入文本变得很长时,模型无需对每个词元都投入相同的注意力计算资源。相反,它会将更多计算资源分配给那些可能更重要、更相关的词元,从而在力求保持长上下文质量的同时,降低训练和推理成本。
在我的测试中,实际应用与该设计目标相符:随着上下文的扩展, 延迟往往会更平缓地增加。, 和 输出一致性往往保持较为稳定。这在工程环境中很重要,因为代码库探索、需求积累和长期执行自然会随着时间的推移而扩展上下文。
异步强化学习基础设施(“slime”)更适合长周期交互
GLM-5 公开描述了一种异步强化学习设置,该设置将轨迹生成(展开)与训练解耦,以提高吞吐量和效率。一种实际的解释是,该模型可以更有效地从大量交互轨迹中学习。 如何完成端到端的任务而不是仅仅学习如何给出单独看似乎合理的答案。
在实际工作流程中,我在故障处理方面最清楚地看到了这一点:GLM-5 不会在无意义的文本上循环,而是更常返回到约束条件并提出建议。 新的可执行步骤而且它更明确地指出了缺少哪些输入。
培训目标从单一技能提升转向智能工程
GLM-5明确地将自身定位为从“提示驱动编码”向其他方向转变 智能体工程我认为这是一种超越编写代码或解决孤立的推理问题的训练目标:该模型需要进行更长期的规划、执行和反思,从而产生可在工程工作流程中使用的结果。
这种框架有助于解释为什么 GLM-5 在 GDPval-AA(知识工作代理任务)上表现出色,同时在综合智能指数上也具有竞争力。
GLM-5为何仍“略逊于”已关闭的旗舰:差距虽小,但并非为零
GLM-5 已经处于同一顶级评分区间。
一个 50 根据智能指数来看,综合评估结果显示该模型没有明显的弱点——否则很难保持如此高的分数。它的得分与 Claude Opus 4.5 处于同一水平,略低于 Claude Opus 4.6(自适应推理)和 GPT-5.2(xhigh)。
GLM-5 在真正的知识工作方面已接近旗舰级产品 代理人 任务
一个 Elo 等级 1412 基于 GDPval-AA 的测试结果表明,在工具驱动的知识工作任务中,相对胜率较高。对于部署决策而言,这通常比在狭窄基准测试中的静态准确率更具预测性,因为许多生产场景都涉及检索、分析、编写和工具协调等环节。
剩余差异体现在极端困难和政策成熟度方面
封闭式旗舰系统在策略成熟度方面通常具有优势:更一致的自我检查、更可靠的拒绝边界以及更少的极端情况错误。GLM-5 可以接近它们的水平,但对于某些复杂任务,它可能仍然需要更清晰的约束或更强大的系统级防护措施才能持续稳定地执行任务。
我在实践中证实了以下优势:GLM-5 更像是工程副驾驶,而不是聊天机器人。
更可靠的增量编辑,更少的不必要重写
当我在保持整体结构不变的情况下需要进行局部修改时,GLM-5 通常会生成针对性的替换或差异式编辑,而不是重写整个模块。这减少了代码审查的工作量,也更容易管理回归风险。
在更长的任务链中实现更好的约束一致性
当我将一项任务拆分成多个回合,并从早期步骤中强制执行严格的约束时,GLM-5 更有可能随着上下文的增长保持这些约束的一致性,从而减少相互矛盾的假设。
更多可执行的工具链输出和更好的故障恢复能力
在“检索→综合→交付”的工作流程中,我关注模型是否能够生成可执行的步骤以及清晰的“缺失输入”清单。GLM-5 更倾向于推动工作流程向前发展,而不是停留在解释层。
需要提前了解的限制因素:哪些因素会阻碍生产环境中的应用
部署和系统成本仍然很高。
GLM-5 是一个旗舰级的 MoE 模型。即使每个令牌只激活模型的一部分,自托管仍然需要在内存规划、并发调度、键值缓存策略、量化和推理引擎兼容性等方面进行大量工作。
它不会自动赢得所有专业领域的胜利
智能指数和 GDPval-AA 更侧重于通用推理和知识型工作任务。如果您的领域高度专业化——例如,严格的合规流程、小众的正式数学证明或极其精细的风格控制——您仍然应该在最终确定方案之前进行有针对性的 A/B 测试。
强大的模型并不能取代强大的系统工程。
在智能体部署中,最常见的故障并非“模型无法响应”,而是“执行链不受控制”。工具权限、安全隔离、可观测性、重试逻辑和证据验证仍然是把模型能力转化为稳定的生产性能所必需的。
我何时会优先考虑 GLM-5
如果我的目标是让模型在工程工作流程中发挥有意义的作用(而不仅仅是生成一次性答案),那么 GLM-5 是顶级候选模型,尤其适用于:
- 长上下文工程任务: 跨文件调试、重构、复杂问题定位
- 以工具为中心的工作流程: 检索、脚本编写、数据综合、文档交付
- 公开组重量级参赛要求: 本地部署、定制化以及更严格的成本/控制限制
如果您的工作负载主要以简短的问答为主,对成本/QPS 非常敏感,或者您在非常严格的合规性限制下运行,并且不愿采用系统级的防护措施,我建议您从较轻的型号或封闭的旗舰产品开始作为基准,只有在 GLM-5 能够带来明显回报的情况下才添加它。