
2026年3月4日,谷歌正式发布了Gemini 3系列的最新成员——Gemini 3.1 手电筒该模型专为高并发开发者工作负载和企业级部署而设计,旨在实现最高速度和成本效益。本报告基于对官方技术文档和第三方评估数据的分析,概述了该模型的核心性能、成本和实际应用指标。
性能和核心基准测试结果
Gemini 3.1 Flash-Lite 在多个主流 AI 基准测试中展现出了显著的技术竞争力。根据以下数据: Arena.ai 在排行榜上,该模型获得了 Elo 评分。 1432在 GPQA钻石级 该测试旨在衡量专家级推理能力,其准确率达到了 86.9%得分 76.8% 在 MMMU Pro 多模态理解能力测试。
数据显示,Gemini 3.1 Flash-Lite 的整体性能不仅超越了同级别其他型号,而且也优于上一代更大尺寸的型号。 双子座 2.5 闪光灯 在多项指标上均有所提升。这种性能飞跃使开发人员能够在保持低资源消耗的同时,获得更高的逻辑处理能力。
竞争格局:跨世代和同侪比较
在2026年小型闪光灯市场,Gemini 3.1 Flash-Lite的主要竞争对手是 GPT-5 mini 和 克劳德 4.5 俳句与前代产品直接比较, 双子座 2.5 闪光灯进一步说明了其技术演变:
| 公制 | Gemini 3.1 手电筒 | 双子座 2.5 闪光灯 | GPT-5 mini | 克劳德 4.5 俳句 |
| 输出速度 | 约 363-384 个令牌/秒 | 每秒约 150-200 个代币 | 约 71 个代币/秒 | 约 108 个代币/秒 |
| 首次代币到达时间 (TTFT) | 最快 | 基线 | 慢点 | 中等的 |
| 单价(/百万) | $1.50 | $0.60 | $2.00 | $5.00 |
| SimpleQA准确率 | 43.30% | 28.50% | 9.50% | 5.50% |
| 上下文窗口 | 100万个代币 | 100万个代币 | 40万代币 | 20万个代币 |
指标显示,虽然 Gemini 3.1 Flash-Lite 的价格高于 2.5 Flash,但其输出速度提高了约 45%,并且首次代币时间 (TTFT) 已从之前的基准值降低至 40%。
成本效益逻辑:价格与代币复杂度比率
虽然社区讨论已经注意到 Gemini 3 Flash 系列的价格上涨,但仅仅关注代币的单价并不能提供完整的信息。选择型号的核心指标是价格与代币复杂度的比率。
例如,在其他行业模型中,虽然 Sonnet 5 的单价可能更低,但对于复杂任务,它可能需要比 Opus 4.6 多得多的代币才能达到相同的结果,从而导致实际总成本更高。Gemini 3.1 Flash-Lite 的优势在于其信息密度和单代币执行效率。对于开发者而言,选择模型不应仅仅考虑基准测试和代币价格,还应关注该模型是否能为特定工作流程带来切实的改进。
社区反馈和实际视觉表现
在实际应用中,已有多个用户完成了该模型的大规模部署。在用于检测人类情感的视觉基准测试中, 涉及 14个大型模型根据对准确率、响应速度和令牌消耗的综合评估,Gemini 3 Flash 排名第一。这一结果验证了其在处理复杂多模态输入方面的稳定性。
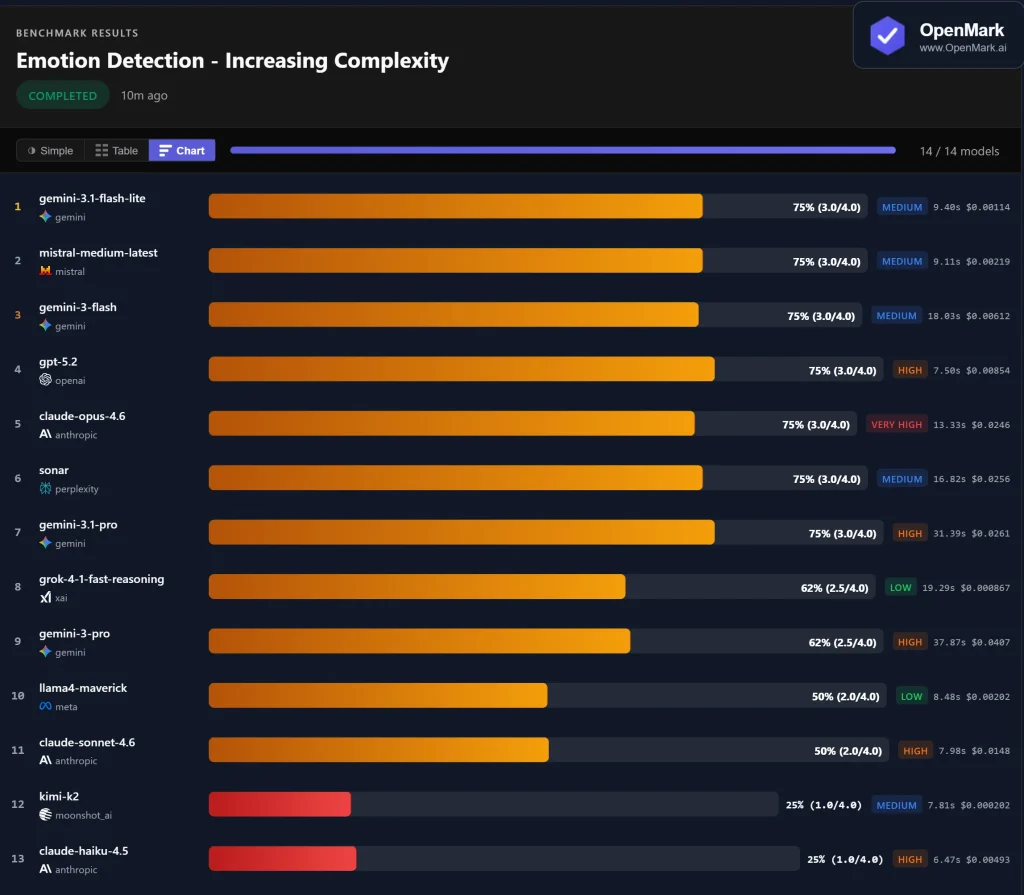
Latitude、Cartwheel 和 Whering 等早期采用者报告称,该模型在长上下文处理和指令执行方面保持稳定。在电子商务领域,它被用于基于实时数据生成动态仪表盘;而在 SaaS 行业,它为能够执行多步骤任务的智能代理提供支持。
尽管 Gemini 3.1 Flash-Lite 具有诸多优势,但社区也指出了一些挑战。例如,其输出较为冗长,在特定情况下可能导致输出令牌数量超出预期,从而增加成本。此外,预览版在 API 使用高峰期会出现响应波动,这需要在大规模商业推广过程中进行技术优化。


