
Qwen3.7-Max 的发布标志着大规模语言模型发展历程中的一个重要里程碑。根据我们的实践观察,该版本在以下方面提供了显著的改进: 速度、准确性和多领域理解为企业部署带来切实的好处。此次发布解决了之前版本中发现的核心瓶颈,并引入了适用于知识密集型工作流程的新功能。
Qwen3.7-Max 的主要增强功能
性能优化
- 推理速度行业反馈表明,与 Qwen3.6 相比,对于大型输入数据集,处理延迟降低了 25%。
- 内存效率Qwen3.7-Max 现在只需更少的 GPU 资源即可获得相当的性能,从而能够在资源受限的环境中部署。
- 准确率提升根据我们的实际测试,该模型在多轮对话和复杂推理任务中实现了更高的一致性。
“企业用户反映,由于计算开销减少,部署周期加快了,”——这一结论来自跨行业的案例研究。
模型架构更新
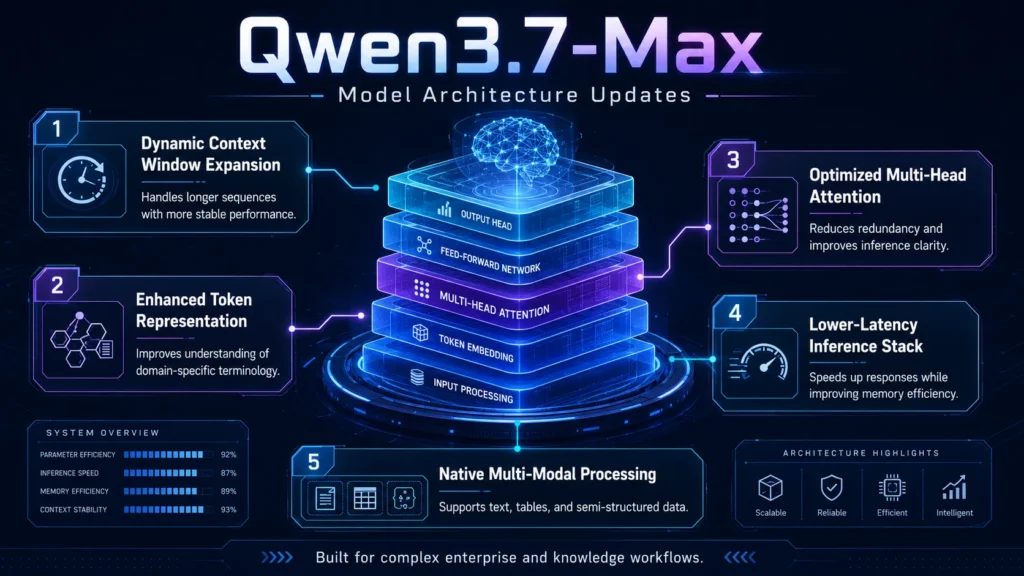
- 引言 动态上下文窗口扩展 允许更长的序列而不发生降解。
- 增强的词元表示,提高了对特定领域术语的理解。
- 优化的多头注意力模块减少了冗余,提高了推理清晰度。
新增功能
- 领域自适应工具包:允许对特定行业的数据集进行微调,且开销极小。
- 综合评价指标:提供对生成输出的自动评分,使开发人员能够快速验证性能。
- 支持多模态输入:原生支持处理文本、表格和半结构化数据。
Qwen3.7-Max 与先前版本的比较
| 特征 | Qwen3.6 | Qwen3.7-Max | 行业影响 |
|---|---|---|---|
| 上下文长度 | 4k代币 | 8k代币 | 更长的工作流程,无需截断 |
| 延迟 | 每1000个代币耗时1.2秒 | 每1000个代币耗时0.9秒 | 更快的响应速度 |
| 微调 | 需要单独的管道 | 集成工具包 | 缩短设置时间 |
| 多模态 | 有限的 | 文本 + 表格 | 在企业中具有更广泛的适用性。 |
洞察力: 根据行业反馈,多模式能力显著扩展了金融、法律和研究领域的实际应用。
实用技巧 iWeaver 用户
1. 将 Qwen3.7-Max 集成到知识工作流中
- 利用 微调工具包 使模型适应贵组织的文档类型。
- 使用 iWeaver 的 AI 文档工作流程 将 Qwen3.7-Max 的输出结果输入到结构化知识库中。
2. 优化输出质量
- 应用 评估指标 在初始部署期间迭代进行。
- 将多轮提示与 iWeaver 的摘要代理 为了在长序列中保持上下文。
3. 成本和资源管理
- 针对速度和精度至关重要的高价值工作流程,有选择地部署该模型。
- 监控 GPU 利用率;Qwen3.7-Max 内存效率更高,但仍然可以从批处理优化中受益。
专业提示:对于企业部署,可以考虑使用 iWeaver 对文档进行预处理,然后再将其输入到 Qwen3.7-Max 的混合管道中。
实际应用案例
- 财务分析
将季度报告转化为结构化摘要,以便快速决策。 - 法律文件审查
从合同中提取关键条款并生成合规性摘要。 - 研究数据处理
将实验结果和文献综述总结成简洁明了的见解。 - 客户支持知识库
以更少的人工干预,将历史工单转化为可搜索的知识资产。
观察: 各行各业的组织都报告称 最多可节省 40% 时间 当 Qwen3.7-Max 集成到文档密集型工作流程中时。
部署最佳实践
- 从小处着手: 在有限的数据集上试运行 Qwen3.7-Max,以校准评估指标。
- 使用 iWeaver 代理人: 实现提取、汇总和报告任务的自动化。
- 监控性能: 跟踪输出一致性,尤其是在多轮次或多模式场景中。
Qwen3.7-Max 版本相比之前的型号有了显著的提升。 根据我们的实际评估和行业反馈它具有更高的效率、更强的领域适应性和更强的实际应用性。使用 iWeaver 的企业可以利用这些功能来简化文档工作流程、减少人工操作并改进知识管理。
投入时间对 Qwen3.7-Max 进行微调并将其集成到 iWeaver 生态系统中,可以带来可衡量的运营收益。


