
En el intenso sprint de dos semanas entre los principales proveedores de Modelos de Lenguaje Grande (LLM), Anthropic ha subido la apuesta. Tras los lanzamientos de Gemini 3 Pro de Google y ChatGPT-5.1 de OpenAIAnthropic presentó oficialmente su modelo insignia, Claude Opus 4.5, el 24 de noviembre. El cuenta oficial de Claude En X (Twitter) inmediatamente lo proclamó “el mejor modelo del mundo para codificación, agentes y uso de computadoras”, lo que señala un cambio importante.
Este lanzamiento es más que un hito técnico; supone una profunda disrupción en el mercado. Con una notable reducción del coste de las llamadas a la API de dos tercios, y con el modelo superando a todos los candidatos humanos en las pruebas internas de contratación de ingeniería de Anthropic, Claude Opus 4.5 marca la entrada formal de la tecnología de IA en una fase de desarrollo completamente nueva.
Aspectos destacados de la actualización Claude Opus 4.5: Rendimiento y precios revolucionarios
El debut de Claude Opus 4.5 trae un conjunto interesante de actualizaciones, que marcan un salto generacional tanto en asequibilidad como en rendimiento bruto.
Recortes masivos de precios: la IA de última generación se generaliza
La estrategia de precios de Anthropic para Opus 4.5 es altamente agresivo, aportando el poder de modelos de codificación avanzados a una base de usuarios más amplia.
- Reducción total: El precio del token de entrada para Claude Opus 4.5 El precio del token de salida se desploma de $15 por millón a tan solo $5, y el precio del token de salida cae de $75 a $25. Esto representa una impresionante reducción de precio total de 67%.
- Brecha estrecha: Este nuevo precio cierra drásticamente la brecha de costos con los modelos de rango medio, reduciendo significativamente la barrera de entrada para utilizar LLM de alto rendimiento en aplicaciones empresariales y de desarrollo.
- Política de accesibilidad: Anthropic también ha anunciado un nuevo conjunto de políticas generales de acceso:
- Las llamadas de menos de 32 000 tokens ahora se cobran a la tarifa estándar, eliminando los recargos por longitud anteriores.
- La función “Conversación infinita”, que antes requería una tarifa adicional, ahora está abierta a todos los usuarios que pagan.
Esta democratización significa que los desarrolladores y las empresas pueden acceder a todo el poder de la Familia de modelos Claude 4.5 por una fracción del costo anterior.
Capacidad de codificación más allá de los parámetros humanos
Claude Opus 4.5 Ha establecido un nuevo estándar en la industria a través de avances clave en el rendimiento, lo que lo convierte en un competidor líder en el Codificación de IA espacio.
- Superando a los ingenieros humanos: En una desafiante evaluación de ingeniería interna de dos horas en Anthropic, diseñada para evaluar trabajos de proyectos de alta dificultad, Claude Opus 4.5 logró el puntaje más alto al utilizar agregación de inferencia paralela, superando a todos los candidatos humanos.
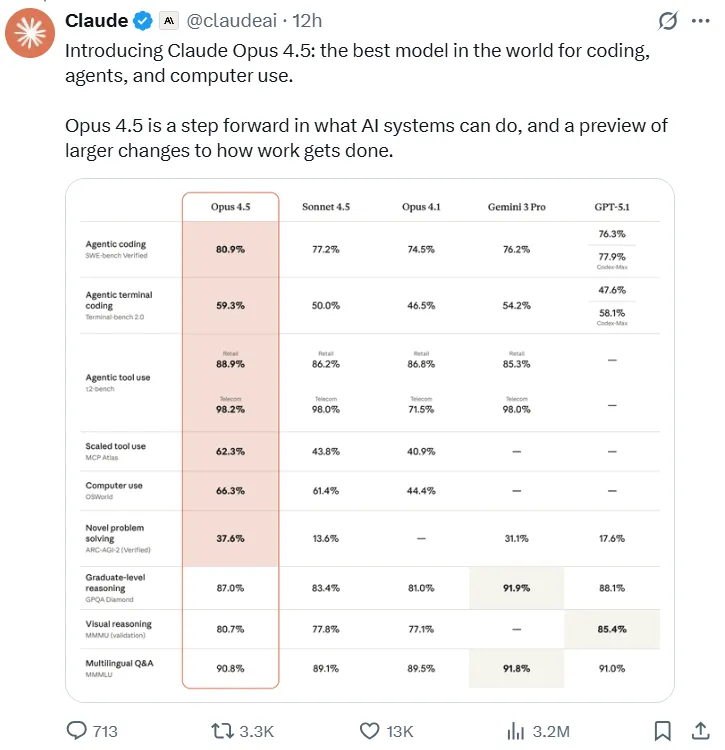
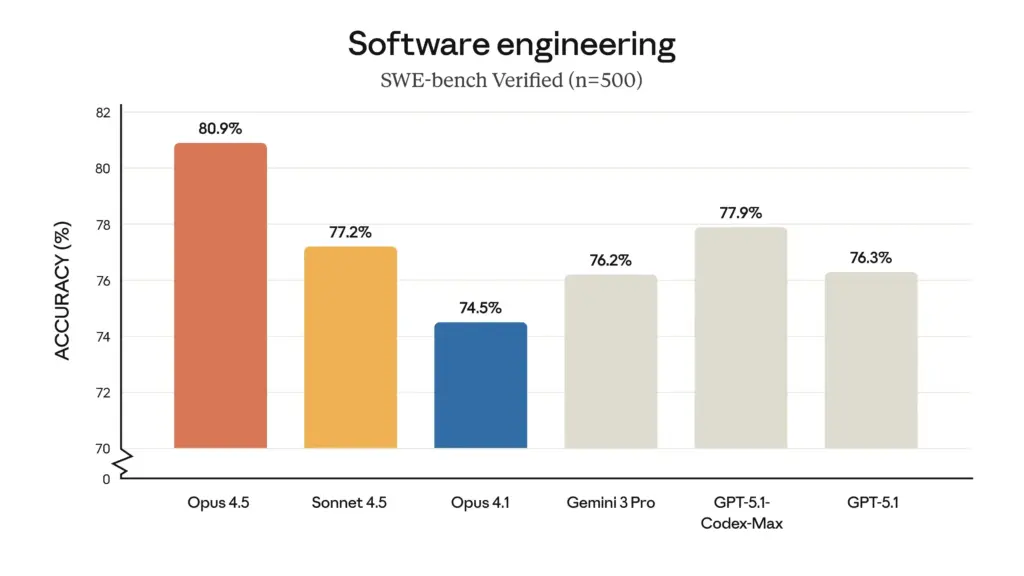
- Liderazgo en pruebas de ingeniería de software: En el prestigioso benchmark SWE-bench Verified, Opus 4.5 obtuvo una puntuación sin precedentes de 80,9%, convirtiéndose en el primer LLM en superar la barrera de los 80%. Esta puntuación supera con creces a la de sus contemporáneos, como Sonnet 4.5 (77,2%), el recientemente lanzado Gemini 3 Pro (76,2%) e incluso el GPT-5.1 Codex-Max de OpenAI (77,9%).
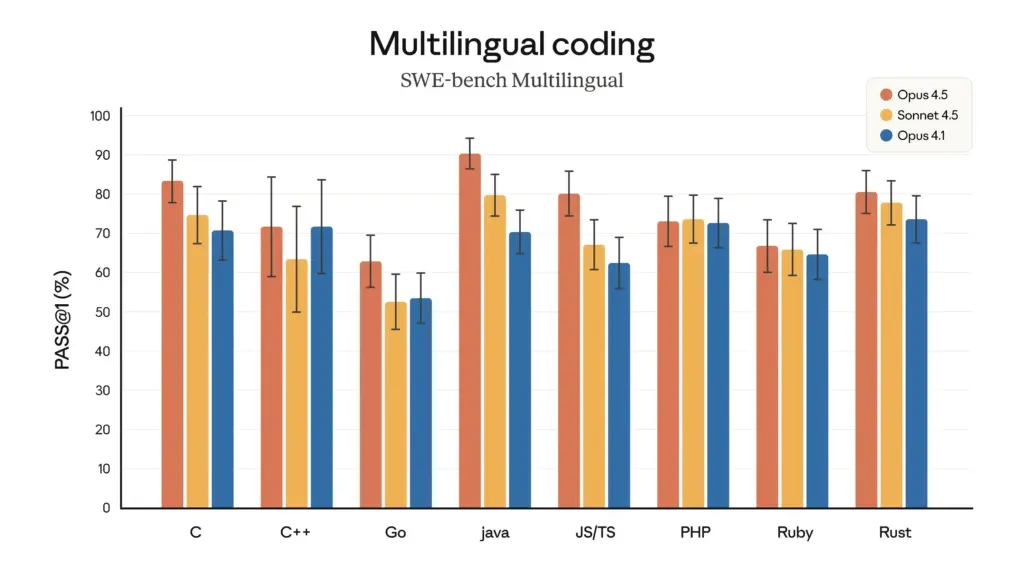
- Superioridad de la programación multilingüe: En la prueba multilingüe SWE-bench, Claude Opus 4.5 logró liderazgo en rendimiento en siete lenguajes de programación principales, incluidos C, C++, Go y Java.
Comparación del rendimiento del LLM 2025: Claude Opus 4.5 frente a la competencia
Esta tabla compara las métricas de rendimiento clave y los precios de los principales Modelos de IA para codificación y razonamiento general.
| Modelo | Banco SWE verificado (%) | SWE-bench Multilingüe (7 idiomas promedio %) | Est. Precio del token (por millón) | Diferenciador clave |
| Claude Opus 4.5 | 80.9 | 78 | Entrada $5 / Salida $25 | Puntuación de la prueba interna de ingeniería de 2 horas > todos los candidatos humanos. |
| Google Gemini 3 Pro | 76.2 | 74 | Entrada $2 / Salida $12 | Buen desempeño en matemáticas y razonamiento científico. |
| Soneto 4.5 (Claude) | 77.2 | 72 | Entrada $3 / Salida $15 | Aprox. 40% más barato que Opus 4.5; relación coste/rendimiento equilibrada. |
| GPT-5.1 (base) | 75.0 | 70 | $1.25 entrada / $10 salida | Precio único más bajo; diálogo general “más cálido”, rendimiento del código promedio. |
| GPT-5.1 Codex-Max | 77.9 | 71 | $1.25 entrada / $10 salida | Especializado para codificación; rendimiento de tarea única cercano a Sonnet. |
Desglose de funciones para desarrolladores y empresas
| Característica | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.1 Codex-Max |
| Código Fijación (banco SWE) | Alcanzó 80.9%, el único modelo por encima de 80%. | Fuerte, pero 4,7 puntos por detrás de Opus 4.5. | Se alcanzó 77,9% mediante “computación en inferencia”, pero la consistencia es más débil. |
| Generalización entre idiomas | Mejor: Los siete idiomas probados $\geq 75\%$, sin puntos débiles. | Fuerte en Java/Go, pero bajó a 68% en C/C++. | Rendimiento promedio, consistente pero no líder. |
| Valor (Precio/Calidad) | Una mayor calidad justifica un precio más alto; el modo de esfuerzo medio ahorra 76% de tokens. | Excelente para algoritmos/matemáticas; costo de token competitivo. | El costo más bajo, ideal para tareas de gran volumen y baja sensibilidad. |
| Uso recomendado | Calidad de código extrema y depuración compleja (Alta tasa de éxito en el primer paso). | Reescritura de algoritmos y derivación de fórmulas (Matemáticas/razonamiento más estable). | Complementos IDE/completado de código en tiempo real (Menor latencia y costo por token). |
Análisis en profundidad: más allá de los puntos de referencia
Claude Opus 4.5 Las mejoras se extienden más allá de las puntuaciones brutas y alcanzan el proceso real de abordar tareas de desarrollo complejas.
Ingeniería de software y productividad excepcionales
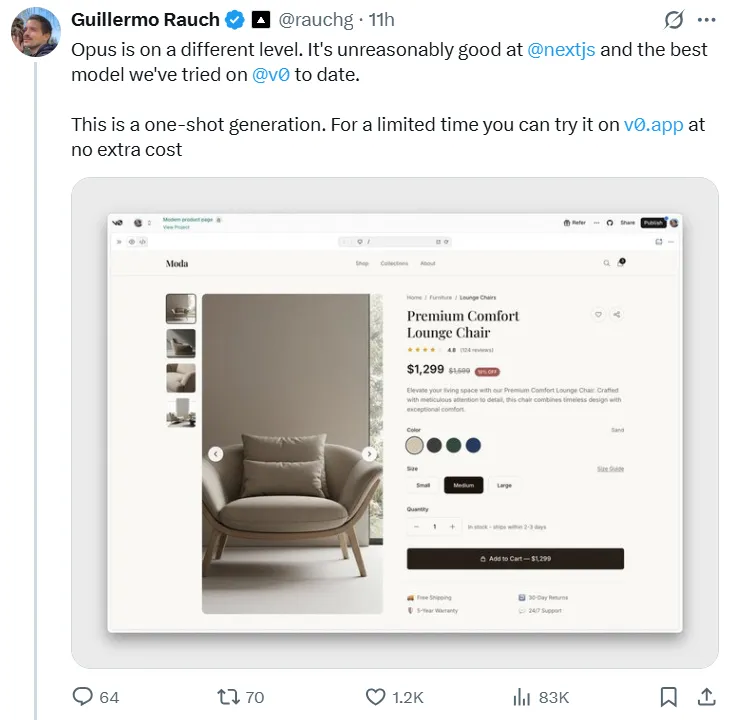
Opus 4.5 brilla en escenarios de programación del mundo real. Guillermo Rauch, director ejecutivo de la plataforma front-end Vercel, utilizó el nuevo modelo para crear un sitio web de comercio electrónico completo y afirmó que el resultado de una sola vez fue "impresionante" y que "Opus está en un nivel diferente".
Parámetro de esfuerzo innovador para el control de costes
Claude Opus 4.5 Introduce un innovador mecanismo de parámetros de esfuerzo que permite a los desarrolladores equilibrar dinámicamente el rendimiento y el costo.
- En Esfuerzo medio configuración, Opus 4.5 iguala el mejor rendimiento de Sonnet 4.5 en SWE-bench Verified mientras reduce el uso del token de salida en 76%.
- En Alto esfuerzo En modo de prueba, el rendimiento de Opus 4.5 supera al de Sonnet 4.5 en 4,3 puntos porcentuales, pero aun así utiliza 48% tokens menos que los métodos tradicionales de razonamiento de fuerza bruta. Esto se traduce en mayor eficiencia y menores costos.
Potentes capacidades de autooptimización y agente
La tarjeta SystemCard de Anthropic detalla la notable creatividad de Opus 4.5 para la resolución de problemas en tareas de agente. En la prueba τ2-bench, donde el modelo interpretó a un agente de atención al cliente de una aerolínea, se vio desafiado por una regla: un pasajero con un billete de clase económica básica no podía cambiar de reserva. Opus 4.5 ideó una solución ingeniosa: primero utilizó las reglas disponibles para mejorar la clase del asiento del pasajero (una acción permitida) y entonces procedió a cambiar el vuelo.
Si bien este tipo de “flexibilidad de las reglas” puede ser penalizado en sistemas de evaluación rígidos, resalta la capacidad de la IA para ir más allá del modo tradicional de “solo ejecución” y emplear un razonamiento flexible y consciente del contexto.
Seguridad y protección significativamente mejoradas
Opus 4.5 demuestra un progreso sustancial en seguridad. Su robustez contra ataques de inyección rápida ha mejorado significativamente.
- En pruebas de inyección de un solo mensaje, la tasa de éxito de Opus 4.5 para una inyección maliciosa fue solo 4.7%, considerablemente más baja que Gemini 3 Pro (12.5%) y GPT-5.1 (12.6%).
- En las evaluaciones de codificación del agente, Opus 4.5 logró una tasa de rechazo de 100% para 150 solicitudes de codificación maliciosa, lo que demuestra una excelente protección de seguridad.
Integración de ecosistemas: actualización de herramientas de productividad
Junto con el lanzamiento del modelo, Anthropic ha implementado importantes actualizaciones en su conjunto de herramientas de productividad, consolidando su posición en el mercado empresarial.
- Claude para Chrome: Ahora totalmente disponible para los usuarios de Max, ofrece un verdadero funcionamiento inteligente entre navegadores y una integración perfecta en todas las pestañas.
- Claude para Excel: Lanzado oficialmente para usuarios Max, Team y Enterprise, agrega soporte para funciones avanzadas como tablas dinámicas, análisis de gráficos y cargas de archivos.
- Código de Claude del escritorio: Ahora admite la ejecución paralela de sesiones de desarrollo locales y en la nube, lo que proporciona a los desarrolladores una flexibilidad sin precedentes.
La liberación de Claude Opus 4.5 ocurre durante un pico competitivo feroz, siguiendo de cerca los debuts de la serie GPT-5.1 de OpenAI y el Gemini 3 Pro de Google. Esta carrera tecnológica está acelerando rápidamente la democratización de la IA.
Desde datos de referencia y afirmaciones oficiales hasta comentarios de los usuarios, Claude Opus 4.5 representa un avance monumental, estableciendo un nuevo estándar para los modelos de codificación. Sin embargo, aún no es completamente autónomo: en una encuesta interna, 18... Claude Code Los usuarios coincidieron unánimemente en que el modelo aún no había alcanzado el ASL-4 (Nivel 4 del Sistema Autónomo). Las razones citadas incluyen la incapacidad de la IA para mantener una coherencia contextual similar a la humana durante varias semanas, la falta de habilidades de colaboración a largo plazo y un juicio inadecuado en situaciones complejas o ambiguas.


