
Lo que Alibaba realmente lanzó con Qwen 3.5: Aclaración de la gama de versiones
En mi opinión, el primer paso para comprender Alibaba Qwen 3.5 es separar claramente la modelo de peso abierto desde alojado en la nube API ofrenda:
- Qwen3.5-397B-A17BEl modelo de peso abierto. Alibaba proporciona especificaciones básicas sobre Hugging Face, como 397B parámetros totales, 17B activados por token, y 60 capas.
- Qwen3.5-PlusLa versión de la API alojada en Alibaba Cloud Model Studio. Alibaba indica que corresponde al modelo 397B-A17B y añade funciones de producción como una ventana de contexto de token 1M predeterminada, herramientas integradas, y invocación de herramienta adaptativa.
Esta distinción aparece repetidamente en Reddit discusiones. Mucha gente confunde Más, el modelo de peso abierto y las “extensiones de herramientas/contexto”, lo que aumenta la confusión durante la evaluación.
Lo que considero como las principales mejoras en Qwen 3.5
Agrupo las actualizaciones en dos categorías: cambios fundamentales a nivel de modelo y Optimizaciones de ingeniería para la eficiencia. Mensajería pública También destaca menor costo, mayor rendimiento, y un enfoque en IA agente.
MoE extremadamente escaso
Ministerio de Educación (Mezcla de expertos) Puede entenderse como una arquitectura de modelo con múltiples subredes de expertos. Durante la inferencia, un mecanismo de enrutamiento activa solo un pequeño subconjunto de expertos, en lugar de ejecutar todos los parámetros cada vez. Las principales ventajas son:
- Gran recuento total de parámetros:mayor capacidad del modelo (más patrones puede representar el modelo).
- Pequeño recuento de parámetros activados:El cálculo de inferencia se acerca más a un modelo más pequeño, lo que puede mejorar el rendimiento y reducir los costos.
Para Qwen3.5-397B-A17B, los números listados públicamente son 397B parámetros totales y 17B activado. (Cara abrazada) Reuters también informa sobre las afirmaciones de Alibaba de Menor costo de uso y mayor rendimiento en comparación con la generación anterior, incluidas declaraciones como "aproximadamente 60% más barato" y una capacidad mejorada para manejar cargas de trabajo más pesadas.
Al evaluar MoE en la práctica, considero los beneficios de dos maneras: (1) con el mismo presupuesto, se puede usar un modelo de mayor capacidad, y (2) con el mismo objetivo de rendimiento, se puede reducir el consumo de cómputo. Sin embargo, estas ganancias dependen de un enrutamiento sólido, la paralelización y un entrenamiento estable. De lo contrario, los sistemas MoE pueden presentar variabilidad en la calidad o inestabilidad del servicio.
Predicción conjunta multitoken nativa
Los modelos autorregresivos tradicionales predicen un token siguiente por paso. El objetivo de predicción conjunta de múltiples tokens es producir predicciones para múltiples posiciones futuras en una sola pasada hacia adelante, mientras se entrena explícitamente el modelo para mantener esas predicciones consistentes.
He aquí el impacto práctico en la velocidad de inferencia en términos sencillos:
- Si el modelo puede “mirar hacia adelante” de manera confiable y predecir múltiples tokens a la vez, y una política de aceptación solo mantiene resultados de alta confianza, puede reducir la cantidad de pasos de decodificación.
- Menos pasos de decodificación generalmente aumentan el rendimiento, especialmente para salidas largas o cargas de trabajo de contexto largo.
Alguno tarjetas de modelos de terceros y los resúmenes de ecosistemas también tratan predicción de múltiples tokens como un factor importante detrás de las ganancias de rendimiento de Qwen 3.5.
Al evaluar esta técnica, me centro en dos aspectos: la estabilidad de la estrategia de aceptación y su comportamiento en muestreos a baja y alta temperatura. En mi experiencia, las cargas de trabajo de prellenado prolongadas y la alta concurrencia tienden a exponer la inestabilidad con mayor antelación.
Multimodalidad nativa
Blog oficial de Qwen de Alibaba posiciones Qwen 3.5 como “Agentes Multimodales Nativos”, enfatizándolo como un modelo de visión-lenguaje nativo Diseñado para la comprensión de imágenes/videos y flujos de trabajo de agentes.
Resumo el valor de la multimodalidad nativa de la siguiente manera:
- La visión y el lenguaje se entrenan en el mismo espacio de parámetros, lo que puede facilitar que las señales visuales contribuyan al razonamiento, el uso de herramientas y las decisiones de acción posteriores.
- Se adapta mejor a las tareas de "agente visual". Reuters también menciona capacidades relacionadas con la ejecución de tareas en aplicaciones móviles y de escritorio.
Cómo interpreto el perfil de capacidades de Qwen 3.5: fortalezas y límites
No recomiendo basarse en uno o dos resultados de la clasificación. Un enfoque más útil es dividir las capacidades en categorías que se ajusten a las tareas de su empresa.
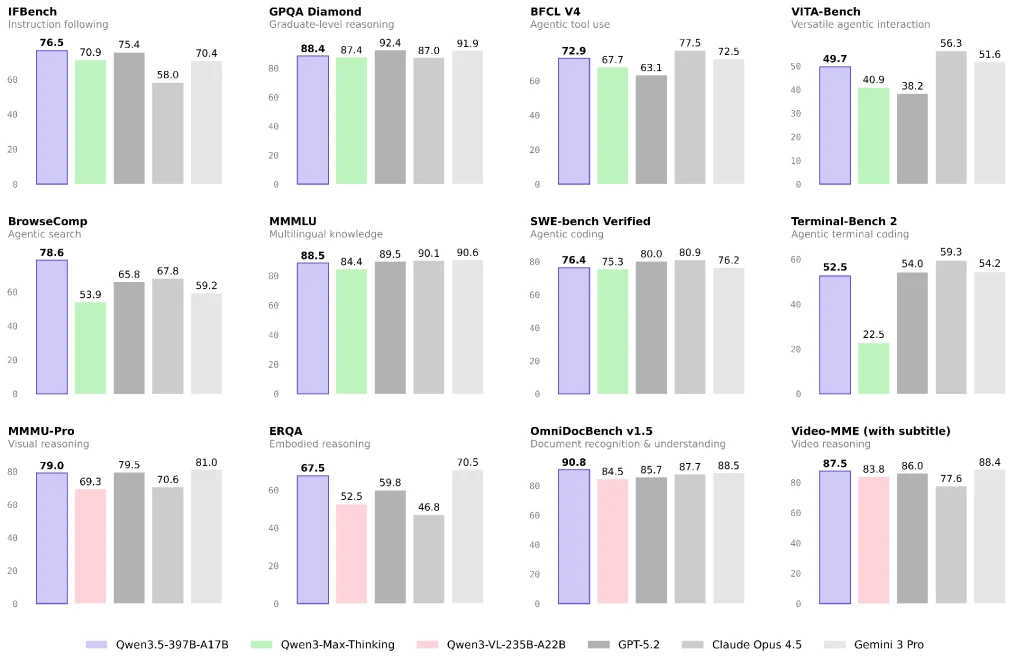
Lenguaje y razonamiento general: cerca del nivel superior del modelo cerrado, pero la combinación de tareas importa
Los informes oficiales y de terceros sugieren que Qwen 3.5 tiene un excelente desempeño en múltiples puntos de referencia de lenguaje y razonamiento y enfatiza una alta capacidad por costo unitario.
Si su carga de trabajo se centra principalmente en preguntas y respuestas sobre conocimientos, generación de contenido o análisis general, Qwen 3.5 puede ser una opción con una excelente relación calidad-precio. Aun así, recomiendo realizar una pequeña prueba A/B con su combinación de tareas de producción real en lugar de extraer conclusiones únicamente de las pruebas de rendimiento.
Visión, documentos y vídeo: un enfoque claro para Qwen 3.5
Qwen3.5-397B-A17B está categorizado en Hugging Face como un modelo con capacidad de visión, y el blog de Alibaba lo enmarca para casos de uso de agentes multimodales.
Si su aplicación incluye lo siguiente, creo que vale la pena priorizar Qwen 3.5 para su evaluación:
- Comprensión del diseño de documentos complejos y canales de OCR a razonamiento
- Razonamiento visual, gráficos y tablas
- Entrada de video largo para resumen estructurado o extracción de información (dependiendo de si utiliza Qwen3.5-Plus y sus capacidades de contexto)
Agentes y uso de herramientas: Separo los “agentes de búsqueda” de los “agentes de herramientas generales”
El “rendimiento del agente” varía ampliamente tanto en la evaluación como en las implementaciones reales:
- Agentes de búsqueda Dependen en gran medida de la estrategia de recuperación, las políticas de plegado/compresión de contexto y la orquestación de herramientas. Las discusiones de la comunidad también señalan que diferentes estrategias pueden producir grandes diferencias de puntuación.
- Agentes de herramientas generales dependen más de los protocolos de herramientas, la recuperación de errores, la estabilidad a largo plazo y los límites de permisos.
Reuters destaca las mejoras de Qwen 3.5 para ejecutar tareas en aplicaciones móviles y de escritorio, lo que generalmente implica una inversión significativa en “agentes visuales + herramientas”.
Costo y acceso: ¿Cómo elegiría entre las opciones?
Si desea la ruta más rápida hacia la producción, comenzaría con Qwen3.5-Plus
Mi razón es sencilla: Más Viene con valores predeterminados orientados a la producción, como una ventana de contexto de 1 millón de tokens, herramientas integradas, y invocación de herramienta adaptativa.
Estudio de modelos de Alibaba Cloud También ofrece precios de tokens escalonados (los precios varían según el rango de contexto).
Si necesita control de cumplimiento y propiedad predecible, los pesos abiertos pueden ser una mejor opción, pero con un mayor costo de ingeniería.
Al elegir pesas abiertas, divido el costo en tres partes:
- Cálculo de inferencia y memoria (MoE puede ser sensible a la paralelización y al soporte del marco)
- Herramientas y alineación (recuperación/exploración, ejecución de código, aislamiento de permisos)
- Garantía de calidad (conjuntos de evaluación, pruebas de regresión, seguimiento y recuperación)
Mi flujo de trabajo de validación recomendado para una implementación real
- Define la proporción de tres tipos de tareas: texto de preguntas y respuestas / documento y visión / herramientas y búsqueda
- Corrija las restricciones de entrada/salida: longitud del contexto, asignación de herramientas y si se requieren citas
- Utilice un marco de evaluación en dos rutas:
- Ruta A: Qwen3.5-Plus (obtenga una línea base rápidamente)
- Ruta B: Peso abierto 397B-A17B (medir el costo y la estabilidad del autohospedaje)
- Centrarse en casos de fallo: fallos de herramientas en cadenas largas, errores de comprensión de documentos y pérdida de información causada por estrategias de búsqueda.
Según la información pública, considero que la dirección de Qwen 3.5 de Alibaba es pasar de un "modelo de chat" a multimodalidad + herramientas + ejecución multidispositivo para flujos de trabajo de agentes, mientras se utiliza MoE escaso y predicción de múltiples tokens para reducir el costo de inferencia y aumentar el rendimiento.
Si su negocio implica comprensión de documentos, razonamiento visual, búsqueda o flujos de trabajo entre aplicaciones, creo que Qwen 3.5 debería estar en su primera opción de evaluación. Si sus necesidades principales son matemáticas de alto nivel o razonamiento extremo, le sugiero una comparación más rigurosa, tarea por tarea, con otros modelos de gama alta antes de decidirse por una estrategia de modelo principal/de respaldo.
Preguntas frecuentes: Preguntas que recibo con más frecuencia durante la evaluación
P1: ¿Cuál es la diferencia entre Qwen 3.5 y modelos como “Qwen 3 Max-Thinking”?
Interpreto las diferencias en dos dimensiones:
- Posicionamiento:Qwen 3.5 pone más énfasis en la multimodalidad nativa y los flujos de trabajo agentes.
- Forma del producto: Plus es una oferta alojada "mejorada" que suele incluir configuraciones predeterminadas para el contexto, las herramientas y las políticas. Por esta razón, algunos usuarios de la comunidad consideran que la relación entre versiones no es clara.
P2: ¿Por qué debería importarme el “MoE extremadamente disperso”?
Porque afecta directamente el coste por solicitud y el límite de rendimiento. Para preguntas y respuestas de alta concurrencia y análisis de contexto extenso, esta arquitectura tiene más probabilidades de generar mayor tráfico con un presupuesto fijo. Los parámetros y detalles estructurales se detallan claramente en la tarjeta del modelo.
P3: ¿La predicción conjunta de múltiples tokens afectará la calidad de la generación?
El objetivo es reducir los pasos de decodificación y mejorar el rendimiento, pero el impacto en la calidad depende de las políticas de entrenamiento e inferencia. Recomiendo probar las tareas de salida de formato largo y las tareas de muestreo de alta aleatoriedad por separado, y evitar extraer conclusiones de un único punto de referencia.

