
What Alibaba Actually Released with Qwen 3.5: Clarifying the Version Lineup
In my view, the first step to understanding Alibaba Qwen 3.5 is to clearly separate the open-weight model from the cloud-hosted API offering:
- Qwen3.5-397B-A17B: The open-weight model. Alibaba provides core specs on Hugging Face, such as 397B total parameters, 17B activated per token, and 60 layers.
- Qwen3.5-Plus: The API version hosted on Alibaba Cloud Model Studio. Alibaba indicates it corresponds to the 397B-A17B model and adds production features like a default 1M-token context window, built-in tools, and adaptive tool invocation.
This distinction comes up repeatedly in Reddit discussions. Many people mix up Plus, the open-weight model, and “tooling/context extensions,” which increases confusion during evaluation.
What I See as the Core Upgrades in Qwen 3.5
I group the upgrades into two categories: fundamental model-level changes and engineering optimizations for efficiency. Public messaging also highlights lower cost, higher throughput, and a focus on agentic AI.
Extreme Sparse MoE
MoE (Mixture of Experts) can be understood as a model architecture with many “expert” sub-networks. During inference, a routing mechanism activates only a small subset of experts, instead of running all parameters every time. The main benefits are:
- Large total parameter count: higher model capacity (more patterns the model can represent).
- Small activated parameter count: inference compute is closer to a smaller model, which can improve throughput and reduce cost.
For Qwen3.5-397B-A17B, the numbers publicly listed are 397B total parameters and 17B activated. (Hugging Face) Reuters also reports Alibaba’s claims of lower usage cost and higher throughput versus the previous generation, including statements like “about 60% cheaper” and improved ability to handle heavier workloads.
When I evaluate MoE in practice, I think of the benefits in two ways: (1) with the same budget you can use a higher-capacity model, and (2) with the same throughput target you can reduce compute usage. However, these gains depend on strong routing, parallelization, and stable training. Otherwise, MoE systems can show quality variance or service instability.
Native Multi-Token Joint Prediction
Traditional autoregressive models predict one next token per step. The goal of multi-token joint prediction is to produce predictions for multiple future positions in a single forward pass, while explicitly training the model to keep those predictions consistent.
Here is the practical impact on inference speed in plain terms:
- If the model can reliably “look ahead” and predict multiple tokens at once, and an acceptance policy only keeps high-confidence outputs, it can reduce the number of decoding steps.
- Fewer decoding steps typically increases throughput, especially for long outputs or long-context workloads.
Some third-party model cards and ecosystem summaries also treat multi-token prediction as an important factor behind Qwen 3.5’s throughput gains.
When I assess this technique, I focus on two things: whether the acceptance strategy is stable, and how it behaves under low-temperature versus high-temperature sampling. In my experience, long prefill workloads and high concurrency tend to expose instability earlier.
Native Multimodality
Alibaba’s official Qwen blog positions Qwen 3.5 as “Native Multimodal Agents,” emphasizing it as a native vision-language model designed for image/video understanding and agent workflows.
I summarize the value of native multimodality as follows:
- Vision and language are trained in the same parameter space, which can make it easier for visual signals to contribute to reasoning, tool use, and subsequent action decisions.
- It is better aligned with “visual agent” tasks. Reuters also mentions capabilities related to executing tasks across mobile and desktop applications.
How I Interpret Qwen 3.5’s Capability Profile: Strengths and Limits
I do not recommend relying on one or two leaderboard results. A more useful approach is to break capabilities into categories that match your business tasks.
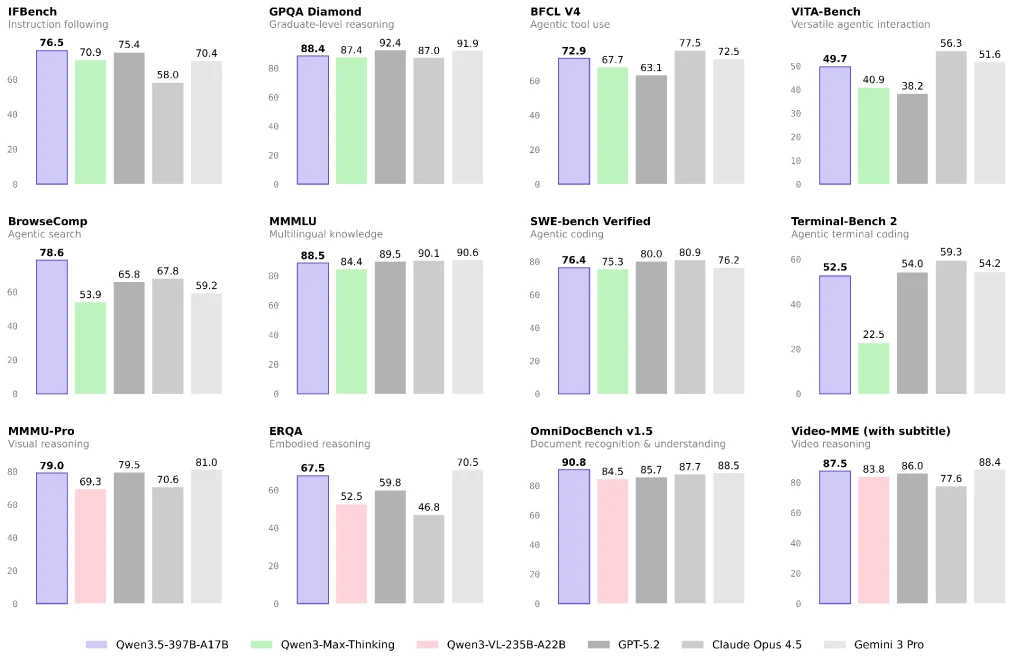
Language and General Reasoning: Near the Closed-Model Top Tier, But Task Mix Matters
Official and third-party reporting suggests Qwen 3.5 performs strongly on multiple language/reasoning benchmarks and emphasizes high capability per unit cost.
If your workload is mainly knowledge Q&A, content generation, or general analysis, Qwen 3.5 can be a strong cost-performance option. I still recommend running a small A/B test on your real production task mix instead of concluding from benchmarks alone.
Vision, Documents, and Video: A Clear Focus Area for Qwen 3.5
Qwen3.5-397B-A17B is categorized on Hugging Face as a model with vision capability, and Alibaba’s blog frames it for multimodal agent use cases.
If your application includes the following, I believe Qwen 3.5 is worth prioritizing for evaluation:
- Complex document layout understanding and OCR-to-reasoning pipelines
- Visual reasoning, charts, and tables
- Long-video input for structured summarization or information extraction (depending on whether you use Qwen3.5-Plus and its context capabilities)
Agents and Tool Use: I Separate “Search Agents” from “General Tool Agents”
“Agent performance” varies widely in both evaluation and real deployments:
- Search agents depend heavily on retrieval strategy, context folding/compression policies, and tool orchestration. Community discussions also point out that different strategies can produce large score differences.
- General tool agents depend more on tool protocols, error recovery, long-horizon stability, and permission boundaries.
Reuters notes Qwen 3.5 improvements for executing tasks across mobile and desktop apps, which typically implies meaningful investment in “visual agents + tooling.”
Cost and Access: How I Would Choose Between Options
If You Want the Fastest Path to Production, I Would Start with Qwen3.5-Plus
My reason is straightforward: Plus comes with production-oriented defaults such as a 1M-token context window, built-in tools, and adaptive tool invocation.
Alibaba Cloud Model Studio also provides tiered token pricing (prices vary by context range).
If You Need Compliance Control and Predictable Ownership, Open Weights May Fit Better, But With Higher Engineering Cost
When choosing open weights, I split the cost into three parts:
- Inference compute and memory (MoE can be sensitive to parallelization and framework support)
- Tooling and alignment (retrieval/browsing, code execution, permission isolation)
- Quality assurance (evaluation sets, regression testing, monitoring, and recovery)
My Recommended Validation Workflow for Real Deployment
- Define the proportion of three task types: text Q&A / document & vision / tools & search
- Fix input/output constraints: context length, tool allowance, and whether citations are required
- Use one evaluation framework across two routes:
- Route A: Qwen3.5-Plus (get a baseline quickly)
- Route B: Open-weight 397B-A17B (measure self-hosting cost and stability)
- Focus on failure cases: tool failures in long chains, document understanding errors, and information loss caused by search strategies
Based on public information, I see Alibaba’s Qwen 3.5 direction as moving from a “chat model” toward multimodality + tools + cross-device execution for agentic workflows, while using sparse MoE and multi-token prediction to reduce inference cost and increase throughput.
If your business involves document understanding, visual reasoning, search, or cross-application workflows, I think Qwen 3.5 should be in your first evaluation shortlist. If your core needs are competition-level math or extreme reasoning, I suggest a stricter task-by-task comparison against other top models before deciding on a primary/backup model strategy.
FAQ: Questions I Get Most Often During Evaluation
Q1: What’s the difference between Qwen 3.5 and models like “Qwen 3 Max-Thinking”?
I interpret the differences in two dimensions:
- Positioning: Qwen 3.5 puts more emphasis on native multimodality and agentic workflows.
- Product form: Plus is a hosted “enhanced” offering that often includes default settings for context, tools, and policies. This is also why some community users feel the version relationships are unclear.
Q2: Why should I care about “extreme sparse MoE”?
Because it directly affects cost per request and your throughput ceiling. For high-concurrency Q&A and long-context analysis, this architecture is more likely to deliver higher traffic within a fixed budget. The parameters and structural details are clearly stated in the model card.
Q3: Will multi-token joint prediction hurt generation quality?
The goal is to reduce decoding steps and improve throughput, but quality impact depends on training and inference policies. My recommendation is to test long-form output tasks and high-randomness sampling tasks separately, and avoid drawing conclusions from a single benchmark.

