
Was Alibaba mit Qwen 3.5 tatsächlich veröffentlicht hat: Eine Klarstellung der Versionsübersicht
Meiner Ansicht nach ist der erste Schritt zum Verständnis Alibaba Qwen 3.5 ist es, die Offenes Gewichtsmodell von Cloud-gehostet API Angebot:
- Qwen3.5-397B-A17BDas Modell mit offener Gewichtsverteilung. Alibaba stellt Kernspezifikationen für Hugging Face bereit, wie zum Beispiel: 397B Gesamtparameter, 17B pro Token aktiviert, Und 60 Schichten.
- Qwen3.5-PlusDie API-Version wird auf Alibaba Cloud Model Studio gehostet. Alibaba gibt an, dass sie dem Modell 397B-A17B entspricht und Produktionsfunktionen wie die folgenden hinzufügt: ein standardmäßiges 1M-Token-Kontextfenster, integrierte Werkzeuge, Und adaptive Werkzeugaufruf.
Diese Unterscheidung taucht immer wieder auf in Reddit Diskussionen. Viele Leute verwechseln Plus, das Open-Weight-Modell und „Tooling-/Context-Erweiterungen“, was die Verwirrung bei der Evaluierung erhöht.
Was ich als die wichtigsten Verbesserungen in Qwen 3.5 sehe.
Ich teile die Upgrades in zwei Kategorien ein: fundamentale Änderungen auf Modellebene Und Technische Optimierungen zur Effizienzsteigerung. Öffentliche Mitteilungen hebt auch hervor niedrigere Kosten, höherer Durchsatzund ein Fokus auf agentenbasierte KI.
Extrem spärliches MoE
MoE (Expertenteam) kann als Modellarchitektur mit vielen „Experten“-Teilnetzwerken verstanden werden. Während der Inferenz aktiviert ein Routing-Mechanismus nur eine kleine Teilmenge der Experten, anstatt jedes Mal alle Parameter zu berechnen. Die Hauptvorteile sind:
- Große Gesamtzahl an Parametern: höhere Modellkapazität (mehr Muster kann das Modell darstellen).
- Anzahl kleiner aktivierter ParameterDie Inferenzberechnung erfolgt näher an einem kleineren Modell, was den Durchsatz verbessern und die Kosten senken kann.
Für Qwen3.5-397B-A17BDie öffentlich aufgeführten Zahlen sind 397B Gesamtparameter Und 17B aktiviertReuters berichtet außerdem über Alibabas Behauptungen. niedrigere Nutzungskosten und höherer Durchsatz im Vergleich zur vorherigen Generation, einschließlich Aussagen wie „etwa 60% günstiger“ und verbesserte Fähigkeit, höhere Arbeitslasten zu bewältigen.
Bei der praktischen Bewertung von MoE-Systemen sehe ich zwei Vorteile: (1) Mit demselben Budget lässt sich ein leistungsfähigeres Modell einsetzen, und (2) bei gleichem Durchsatzziel kann der Rechenaufwand reduziert werden. Diese Vorteile hängen jedoch von einem effizienten Routing, einer effektiven Parallelisierung und einem stabilen Training ab. Andernfalls können MoE-Systeme Qualitätsschwankungen oder Serviceinstabilitäten aufweisen.
Native Multi-Token Joint Prediction
Traditionelle autoregressive Modelle sagen Folgendes voraus: Ein nächster Token pro SchrittDas Ziel von Mehr-Token-Gemeinschaftsvorhersage ist es, Vorhersagen zu erstellen für mehrere zukünftige Positionen in einem einzigen Vorwärtsdurchlauf, wobei das Modell explizit darauf trainiert wird, diese Vorhersagen konsistent zu halten.
Hier die praktischen Auswirkungen auf die Inferenzgeschwindigkeit in einfachen Worten:
- Wenn das Modell zuverlässig „vorausschauen“ und mehrere Token gleichzeitig vorhersagen kann und eine Akzeptanzrichtlinie nur Ausgaben mit hoher Konfidenz beibehält, kann dies die Anzahl der Dekodierungsschritte reduzieren.
- Weniger Dekodierungsschritte erhöhen in der Regel den Durchsatz, insbesondere bei langen Ausgaben oder Workloads mit langem Kontext.
Manche Modellkarten von Drittanbietern und Ökosystemzusammenfassungen behandeln auch Multi-Token-Vorhersage als ein wichtiger Faktor für die Durchsatzsteigerungen von Qwen 3.5.
Bei der Bewertung dieser Technik konzentriere ich mich auf zwei Aspekte: die Stabilität der Akzeptanzstrategie und ihr Verhalten bei niedrigen bzw. hohen Temperaturen. Erfahrungsgemäß decken lange Vorbelegungs-Workloads und hohe Parallelität Instabilitäten frühzeitig auf.
Native Multimodalität
Alibabas offizieller Qwen-Blog Positionen Qwen 3.5 als „native multimodale Agenten“, wobei dies als ein natives Bild-Sprach-Modell Entwickelt für die Bild-/Videoanalyse und Agenten-Workflows.
Den Wert der nativen Multimodalität fasse ich wie folgt zusammen:
- Sehen und Sprache werden im gleichen Parameterraum trainiert, was es einfacher macht, visuelle Signale in das Denkvermögen, den Werkzeuggebrauch und die darauf folgenden Handlungsentscheidungen einzubringen.
- Es ist besser auf die Aufgaben von „visuellen Agenten“ abgestimmt. Reuters erwähnt außerdem Funktionen im Zusammenhang mit der Ausführung von Aufgaben in mobilen und Desktop-Anwendungen.
Meine Interpretation des Leistungsprofils von Qwen 3.5: Stärken und Grenzen
Ich rate davon ab, sich auf ein oder zwei Ranglistenergebnisse zu verlassen. Sinnvoller ist es, die Fähigkeiten in Kategorien einzuteilen, die Ihren Geschäftsaufgaben entsprechen.
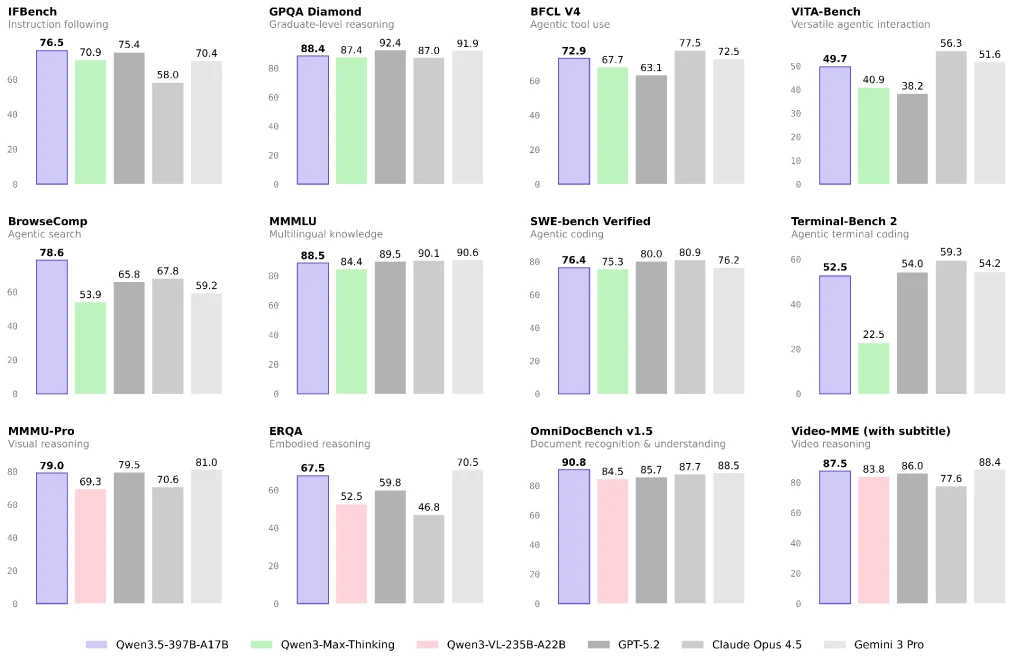
Sprachverständnis und allgemeines Denkvermögen: Nahezu Spitzenklasse im geschlossenen Modell, aber die Aufgabenmischung ist wichtig
Offizielle und unabhängige Berichte legen nahe, dass Qwen 3.5 bei verschiedenen Sprach-/Logik-Benchmarks sehr gut abschneidet und ein hohes Leistungsvermögen pro Kosteneinheit bietet.
Wenn Ihre Arbeitslast hauptsächlich aus Wissensfragen und -antworten, Content-Erstellung oder allgemeinen Analysen besteht, kann Qwen 3.5 eine gute Option mit einem guten Preis-Leistungs-Verhältnis sein. Ich empfehle dennoch, einen kleinen A/B-Test mit Ihrem realen Produktionsaufgabenmix durchzuführen, anstatt sich allein auf Benchmarks zu verlassen.
Bild, Dokumente und Video: Ein klarer Schwerpunkt für Qwen 3.5
Qwen3.5-397B-A17B wird auf Hugging Face als Modell mit Bildverarbeitungsfunktion kategorisiert, und im Blog von Alibaba wird es für multimodale Agenten-Anwendungsfälle beschrieben.
Wenn Ihre Bewerbung Folgendes beinhaltet, halte ich Qwen 3.5 für eine prioritäre Evaluierung:
- Verständnis komplexer Dokumentlayouts und OCR-zu-Schlussfolgerungs-Pipelines
- Visuelles Denken, Diagramme und Tabellen
- Eingabe von langen Videos zur strukturierten Zusammenfassung oder Informationsgewinnung (je nachdem, ob Sie verwenden) Qwen3.5-Plus und seine Kontextfähigkeiten)
Agenten und Werkzeugnutzung: Ich trenne „Suchagenten“ von „Allgemeinen Werkzeugagenten“.
Die „Agentenleistung“ variiert sowohl in der Evaluierung als auch im realen Einsatz erheblich:
- Suchagenten Sie hängen stark von der Abrufstrategie, den Richtlinien zur Kontextfaltung/Komprimierung und der Werkzeugkoordination ab. Diskussionen in der Fachgemeinschaft weisen zudem darauf hin, dass unterschiedliche Strategien zu großen Unterschieden in den Ergebnissen führen können.
- Allgemeine Werkzeugagenten stärker von Werkzeugprotokollen, Fehlerbehebung, Langzeitstabilität und Berechtigungsgrenzen abhängig sein.
Reuters hebt die Verbesserungen von Qwen 3.5 bei der Ausführung von Aufgaben in mobilen und Desktop-Apps hervor, was typischerweise auf erhebliche Investitionen in „visuelle Agenten + Werkzeuge“ hindeutet.
Kosten und Verfügbarkeit: Wie ich zwischen den Optionen wählen würde
Wenn Sie den schnellsten Weg zur Produktion wünschen, würde ich mit Qwen 3.5-Plus beginnen.
Meine Begründung ist einfach: Plus beinhaltet produktionsorientierte Standardeinstellungen wie z. B. ein Kontextfenster mit 1 Million Token, integrierte Werkzeuge, Und adaptive Werkzeugaufruf.
Alibaba Cloud Model Studio bietet außerdem eine gestaffelte Token-Preisgestaltung (die Preise variieren je nach Kontextbereich).
Wenn Sie auf Konformitätskontrolle und vorhersehbare Eigentumsverhältnisse Wert legen, sind offene Gewichte möglicherweise besser geeignet, verursachen aber höhere Entwicklungskosten.
Bei der Auswahl der offenen Gewichte habe ich die Kosten in drei Teile aufgeteilt:
- Inferenzberechnung und Speicherbedarf (MoE kann empfindlich auf Parallelisierung und Framework-Unterstützung reagieren)
- Tools und Ausrichtung (Abruf/Durchsuchen, Codeausführung, Berechtigungsisolierung)
- Qualitätssicherung (Evaluierungsdatensätze, Regressionstests, Überwachung und Wiederherstellung)
Mein empfohlener Validierungs-Workflow für den realen Einsatz
- Bestimmen Sie den Anteil der drei Aufgabentypen: Text-Fragen und -Antworten / Dokument und Vision / Werkzeuge und Suche
- Beheben Sie die Einschränkungen für Eingabe/Ausgabe: Kontextlänge, Werkzeugnutzung und ob Zitate erforderlich sind.
- Verwenden Sie einen einheitlichen Bewertungsrahmen für beide Routen:
- Route A: Qwen3.5-Plus (schnell einen Ausgangswert ermitteln)
- Route B: Offene Gewichtsklasse 397B-A17B (Selbsthosting-Kosten und Stabilität messen)
- Fokus auf Fehlerfälle: Werkzeugausfälle in langen Ketten, Fehler beim Verständnis von Dokumenten und Informationsverluste durch Suchstrategien
Auf Grundlage öffentlich zugänglicher Informationen sehe ich die Ausrichtung von Alibabas Qwen 3.5 darin, sich von einem „Chat-Modell“ hin zu einem … zu entwickeln. Multimodalität + Werkzeuge + geräteübergreifende Ausführung für agentenbasierte Arbeitsabläufe, während der Verwendung spärliches MoE Und Multi-Token-Vorhersage um die Inferenzkosten zu senken und den Durchsatz zu erhöhen.
Wenn Ihr Unternehmen Dokumentenanalyse, visuelles Denken, Suchfunktionen oder anwendungsübergreifende Workflows benötigt, sollte Qwen 3.5 meiner Meinung nach in die engere Auswahl kommen. Falls Ihre Kernanforderungen mathematische Berechnungen auf Wettbewerbsniveau oder extrem komplexes logisches Denken umfassen, empfehle ich einen detaillierteren Vergleich mit anderen führenden Modellen für jede einzelne Aufgabe, bevor Sie sich für ein primäres oder alternatives Modell entscheiden.
Häufig gestellte Fragen (FAQ): Die am häufigsten gestellten Fragen während der Bewertung
Frage 1: Worin besteht der Unterschied zwischen Qwen 3.5 und Modellen wie „Qwen 3 Max-Thinking“?
Ich interpretiere die Unterschiede in zwei Dimensionen:
- PositionierungQwen 3.5 legt mehr Wert auf native Multimodalität und agentenbasierte Arbeitsabläufe.
- ProduktformPlus ist ein gehostetes, „erweitertes“ Angebot, das häufig Standardeinstellungen für Kontext, Tools und Richtlinien enthält. Aus diesem Grund empfinden manche Community-Nutzer die Versionsbeziehungen als unklar.
Frage 2: Warum sollte mich „extrem spärliches MoE“ interessieren?
Da dies die Kosten pro Anfrage und Ihren maximalen Durchsatz direkt beeinflusst, ist diese Architektur für hochkonzentrierte Frage-Antwort-Systeme und Langzeitanalysen geeignet, um innerhalb eines festen Budgets ein höheres Datenaufkommen zu bewältigen. Die Parameter und strukturellen Details sind in der Modellkarte klar beschrieben.
Frage 3: Wird die gemeinsame Vorhersage mehrerer Token die Generierungsqualität beeinträchtigen?
Ziel ist es, die Anzahl der Dekodierungsschritte zu reduzieren und den Durchsatz zu verbessern. Die Auswirkungen auf die Qualität hängen jedoch von den Trainings- und Inferenzstrategien ab. Ich empfehle, Aufgaben mit langer Ausgabe und Aufgaben mit hoher Zufallsstichprobe separat zu testen und keine Schlussfolgerungen aus einem einzelnen Benchmark zu ziehen.

