Evalúo el GLM-5 principalmente como un modelo de ingeniería, no como un modelo de chat general que solo necesita "sonar bien". Mi enfoque es sencillo: primero utilizo puntos de referencia públicos ampliamente referenciados para confirmar dónde se ubica GLM-5 en el nivel superior, luego valido esas señales con un flujo de trabajo repetible Para comprobar si el GLM-5 es realmente más estable y práctico para tareas de ingeniería reales. Con base en ese proceso, mi conclusión es que el progreso del GLM-5 no solo se trata de escala, sino que también avanza. eficiencia de contexto largo, entrenamiento de agentes, y estabilidad de salida de grado de ingeniería Al mismo tiempo. Esta combinación ayuda a explicar por qué su rendimiento es similar al de los modelos cerrados líderes, tanto en tablas de clasificación compuestas como en evaluaciones de agentes reales.
Utilizo dos métricas para establecer la posición de GLM-5
Para evitar basar mi evaluación de GLM-5 únicamente en impresiones subjetivas, baso mi evaluación de GLM-5 en dos vías complementarias de evaluación de Análisis Artificial:
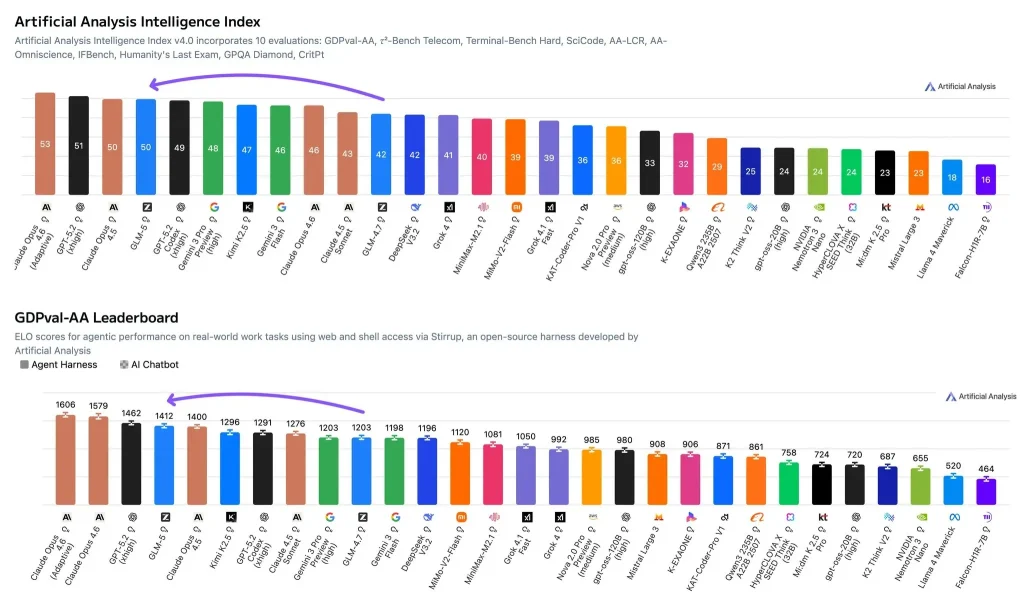
- Índice de Inteligencia de Análisis Artificial (puntuación de capacidad compuesta): Puntuaciones del GLM-5 50, lo que lo coloca en el nivel superior. Las puntuaciones más altas incluyen Claude Opus 4.6 (Razonamiento Adaptativo) en 53 y GPT-5.2 (xhigh) en 51, mientras que Claude Opus 4.5 también está en el 50 rango. Este índice agrega múltiples evaluaciones en una sola puntuación que refleja la fortaleza general en razonamiento, codificación y capacidades relacionadas.
- PIBval-AA (evaluación agencial del trabajo de conocimiento en el mundo real): GLM-5 tiene un Calificación Elo de 1412En términos sencillos, Elo es un puntuación de fuerza relativa cara a caraUn Elo más alto implica una mayor tasa de éxito general en el mismo conjunto de tareas. GDPval-AA está diseñado para asemejarse al trabajo real (por ejemplo, recuperar información, analizarla y producir resultados) y permite que los modelos operen en un arnés de agente con acceso a herramientas.
En conjunto, estas dos métricas apuntan a una hipótesis clara: Es poco probable que la ventaja del GLM-5 provenga de trucos aislados en el conjunto de pruebas. Es más probable que provenga de la calidad y estabilidad en la finalización de tareas complejas de varios pasos.
Cómo pruebo el GLM-5: Tres flujos de trabajo de ingeniería de alta frecuencia
Mis pruebas prácticas se asemejan más a una verificación de aceptación de ingeniería que a una simple presentación. Me centro menos en si el modelo puede generar explicaciones más extensas y más en si puede ofrecer resultados correctos y utilizables bajo ciertas restricciones. Principalmente pruebo tres tipos de flujo de trabajo:
- Tareas de ingeniería de software de contexto largo: Proporciono un segmento de código más largo más restricciones de documentación, y solicito la localización de problemas entre archivos y una propuesta de solución con cambios mínimos.
- Ediciones de código incrementales: Exijo cambios limitados a una función o módulo específico, manteniendo intacta el resto de la estructura, y solicito un parche estilo diff más riesgos de regresión.
- Cadenas de tareas centradas en herramientas: Estructuro las tareas como recuperar → sintetizar → producir un resultado, y verifico si el modelo puede solicitar entradas faltantes con claridad y proponer una ruta de reintento confiable cuando algo falla.
Utilizo estos flujos de trabajo porque las mejoras en el Índice de Inteligencia y GDPval-AA deberían aparecer más claramente en Cadenas largas, uso de herramientas y resultados de ingeniería en lugar de indicaciones breves de un solo turno.
Los avances fundamentales del GLM-5: una mejora estructural a partir de tres cambios de refuerzo
La escasa atención de DSA hace que el contexto largo sea económicamente sostenible
En materiales públicos y el papel, GLM-5 enfatiza la adopción DSA (Atención dispersa de DeepSeek)En pocas palabras: cuando las entradas se vuelven muy largas, el modelo no necesita dedicar la misma atención computacional a cada token. En cambio, asigna más computación a los tokens que probablemente sean más importantes y relevantes, lo que reduce el costo de entrenamiento e inferencia, a la vez que busca preservar la calidad del contexto extenso.
En mis pruebas, la implicación práctica es consistente con ese objetivo de diseño: a medida que el contexto crece, La latencia tiende a aumentar más suavemente, y La coherencia de la producción tiende a permanecer más estableEsto es importante en entornos de ingeniería porque la exploración de la base de código, la acumulación de requisitos y la ejecución a largo plazo expanden naturalmente el contexto con el tiempo.
La infraestructura de aprendizaje automático asincrónico («slime») se adapta mejor a la interacción a largo plazo
GLM-5 describe públicamente una configuración de aprendizaje de refuerzo asincrónico que desacopla la generación de trayectorias (despliegue) del entrenamiento para mejorar el rendimiento y la eficiencia. Una forma práctica de interpretar esto es que el modelo puede aprender con mayor eficacia a partir de grandes volúmenes de rastros de interacción sobre Cómo completar tareas de principio a fin, en lugar de sólo aprender a producir respuestas que parezcan plausibles de forma aislada.
En los flujos de trabajo prácticos, veo esto más claramente en el manejo de errores: en lugar de repetir textos improductivos, GLM-5 vuelve con más frecuencia a las restricciones y propone nuevos pasos ejecutables, y es más explícito sobre qué entradas faltan.
Los objetivos de la capacitación se orientan hacia la ingeniería agente y no hacia la adquisición de habilidades puntuales.
GLM-5 se posiciona explícitamente como alguien que va desde una “codificación basada en indicaciones” hacia ingeniería agencialInterpreto esto como un objetivo de entrenamiento que se extiende más allá de escribir código o resolver problemas de razonamiento aislados: el modelo necesita planificar, ejecutar y reflexionar sobre horizontes más largos, produciendo resultados que se puedan utilizar en flujos de trabajo de ingeniería.
Este marco ayuda a explicar por qué el GLM-5 puede ser sólido en GDPval-AA (tareas de agente de conocimiento-trabajo) y al mismo tiempo obtener un puntaje competitivo en el Índice de Inteligencia compuesto.
Por qué el GLM-5 aún se ubica "justo detrás" de los buques insignia cerrados: la diferencia es menor, pero no nula
GLM-5 ya está en la misma banda de puntuación de primer nivel
A 50 El Índice de Inteligencia sugiere que no existen debilidades importantes en las evaluaciones agregadas; de lo contrario, sería difícil mantener una puntuación a ese nivel. Se sitúa en la misma banda que Claude Opus 4.5, y ligeramente por debajo de Claude Opus 4.6 (Razonamiento Adaptativo) y GPT-5.2 (excelente).
GLM-5 se acerca a los buques insignia en el trabajo del conocimiento real Agente Tareas
Un Elo de 1412 En GDPval-AA, se observan altas tasas de éxito relativas en tareas de trabajo del conocimiento basadas en herramientas. Para las decisiones de implementación, esto suele ser más predictivo que la precisión estática en un parámetro de referencia estrecho, ya que muchos escenarios de producción implican recuperación, análisis, escritura y coordinación de herramientas.
Las diferencias restantes se manifiestan en la extrema dificultad y la madurez de las políticas
Los buques insignia cerrados suelen conservar ventajas en cuanto a la madurez de las políticas: una autocomprobación más consistente, límites de rechazo más fiables y menos errores en casos extremos. El GLM-5 puede aproximarse a su nivel, pero para un subconjunto de tareas complejas aún podría requerir restricciones más claras o medidas de seguridad más sólidas a nivel de sistema para lograr una entrega consistente.
Ventajas que confirmo en la práctica: GLM-5 se comporta más como un copiloto de ingeniería que como un chatbot
Ediciones incrementales más confiables, menos reescrituras innecesarias
Cuando necesito cambios localizados que preserven la estructura circundante, GLM-5 suele generar reemplazos específicos o ediciones de tipo diff en lugar de reescribir módulos completos. Esto reduce la sobrecarga de revisión y facilita la gestión de los riesgos de regresión.
Mejor consistencia de restricciones en cadenas de tareas más largas
Cuando divido una tarea en varios turnos y hago cumplir restricciones estrictas de los pasos anteriores, es más probable que GLM-5 mantenga esas restricciones consistentes a medida que crece el contexto, lo que reduce las suposiciones contradictorias.
Resultados de la cadena de herramientas más ejecutables y mejor recuperación tras fallos
En los flujos de trabajo de recuperación → síntesis → entrega, me centro en si el modelo puede generar pasos ejecutables y una lista clara de "entradas faltantes". GLM-5 suele impulsar el flujo de trabajo en lugar de centrarse en la explicación.
Limitaciones que se deben conocer de antemano: ¿Qué puede bloquear la adopción en producción?
Los costos de implementación y de sistemas siguen siendo altos
GLM-5 es un modelo MoE de escala insignia. Incluso si solo se activa una parte del modelo por token, el autoalojamiento requiere un trabajo considerable en la planificación de memoria, la programación de concurrencia, la estrategia de caché KV, la cuantificación y la compatibilidad con el motor de inferencia.
No ganará automáticamente todas las verticales especializadas
El Índice de Inteligencia y GDPval-AA se inclinan por tareas de razonamiento general y de trabajo del conocimiento. Si su dominio es altamente especializado (por ejemplo, flujos de trabajo de cumplimiento estricto, pruebas matemáticas formales de nicho o un control de estilo extremadamente preciso), debería realizar pruebas A/B específicas antes de comprometerse.
Un modelo sólido no reemplaza una ingeniería de sistemas sólida
En las implementaciones de agentes, el fallo más común no es que el modelo no pueda responder, sino que la cadena de ejecución no esté controlada. Los permisos de las herramientas, el aislamiento de seguridad, la observabilidad, la lógica de reintento y la verificación de evidencias siguen siendo necesarios para que la capacidad del modelo se traduzca en un rendimiento de producción estable.
Cuándo priorizaría GLM-5
Si mi objetivo es que un modelo sea una parte significativa de un flujo de trabajo de ingeniería (no solo produzca respuestas únicas), GLM-5 es un candidato de primer nivel, especialmente para:
- Tareas de ingeniería de contexto largo: Depuración entre archivos, refactorización y localización de problemas complejos
- Flujos de trabajo centrados en herramientas: Recuperación, creación de scripts, síntesis de datos, entrega de documentos
- Requisitos de pesos abiertos: Implementación local, personalización y límites de control y costos más estrictos
Si su carga de trabajo está dominada por preguntas y respuestas breves, es extremadamente sensible a los costos/QPS o si opera bajo límites de cumplimiento muy estrictos sin apetito por barreras a nivel de sistema, comenzaría con modelos más livianos o buques insignia cerrados como base y agregaría GLM-5 solo si ofrece un retorno claro.