
2026年3月4日、GoogleはGemini 3シリーズの最新版を正式に発表しました。ジェミニ 3.1 フラッシュライトこのモデルは、高同時実行性を必要とする開発者ワークロードとエンタープライズ規模の導入向けに特別に設計されており、最高の速度と費用対効果を実現するように最適化されています。本レポートでは、公式技術文書とサードパーティの評価データの分析に基づき、このモデルのコアパフォーマンス、コスト、そして実際のアプリケーションメトリクスを概説します。
パフォーマンスとコアベンチマーク結果
Gemini 3.1 Flash-Liteは、いくつかの主要なAIベンチマークにおいて、優れた技術的競争力を示しました。 アリーナ.ai リーダーボードでは、モデルはEloレーティングを達成しました 1432。 GPQAダイヤモンド 専門家レベルの推論力を測定するテストでは、 86.9%、得点しながら 76.8% の中で MMMUプロ マルチモーダル理解をテストします。
データによれば、Gemini 3.1 Flash-Liteの総合的な性能は、同クラスの他のモデルを凌駕するだけでなく、前世代のより大きなモデルよりも優れている。 ジェミニ2.5フラッシュ 複数の指標にわたって。このパフォーマンスの飛躍的な向上により、開発者はリソース消費を抑えながら、より高い論理処理能力を実現できます。
競争環境:世代間比較と同業他社との比較
2026年の小型モデル市場では、ジェミニ3.1フラッシュライトは主に GPT-5ミニ そして クロード 4.5 俳句前作との直接比較では、 ジェミニ2.5フラッシュは、その技術的進化をさらに示しています。
| メトリック | ジェミニ 3.1 フラッシュライト | ジェミニ2.5フラッシュ | GPT-5ミニ | クロード 4.5 俳句 |
| 出力速度 | ~363-384 トークン/秒 | 約150~200トークン/秒 | 約71トークン/秒 | 約108トークン/秒 |
| 最初のトークン発行までの時間(TTFT) | 最速 | ベースライン | もっとゆっくり | 中くらい |
| 出力価格(/1M) | $1.50 | $0.60 | $2.00 | $5.00 |
| SimpleQAの精度 | 43.30% | 28.50% | 9.50% | 5.50% |
| コンテキストウィンドウ | 100万トークン | 100万トークン | 40万トークン | 20万トークン |
メトリクスによれば、Gemini 3.1 Flash-Lite は 2.5 Flash よりも高価ですが、出力速度は約 45% 増加し、Time to First Token (TTFT) は以前のベースラインの 40% に短縮されています。
費用対効果の論理:価格とトークンの複雑さの比率
コミュニティの議論ではGemini 3 Flashシリーズの価格上昇が指摘されていますが、トークン単価のみに焦点を当てると、文脈が不明確になります。モデル選択の核となる指標は、価格とトークンの複雑さの比率です。
例えば、他の業界モデルでは、Sonnet 5は単価が低いかもしれませんが、複雑なタスクで同じ結果を得るためにはOpus 4.6よりも大幅に多くのトークンが必要になり、結果として実際の総コストが高くなる可能性があります。Gemini 3.1 Flash-Liteの優位性は、トークンあたりの情報密度と実行効率にあります。開発者にとって、モデルの選択はベンチマークやトークン価格だけでなく、そのモデルが特定のワークフローに具体的なアップグレードをもたらすかどうかにも焦点を当てるべきです。
コミュニティからのフィードバックと現実世界のビジュアルパフォーマンス
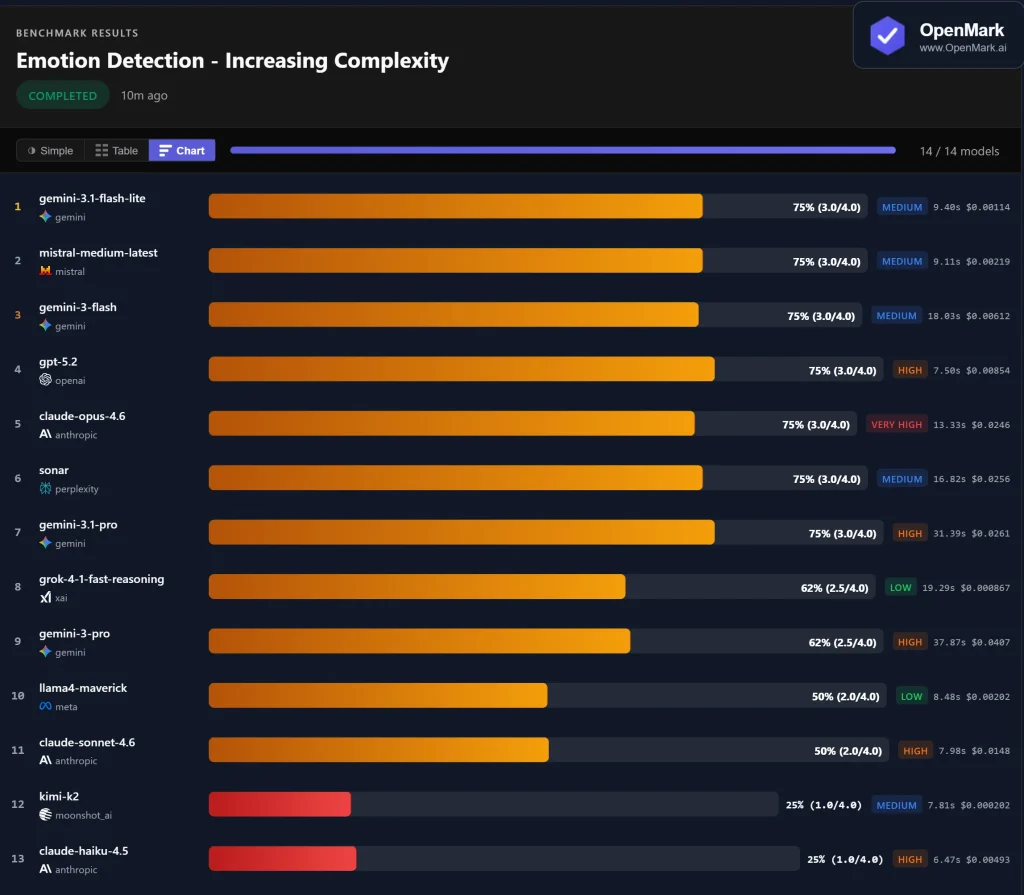
実用化においては、すでに複数のユーザーがこのモデルの大規模展開を完了しています。人間の感情検出の視覚ベンチマークテストでは、 関与する 14個の大型モデルGemini 3 Flashは、精度、応答速度、トークン消費量の総合評価において1位を獲得しました。この結果は、複雑なマルチモーダル入力処理における安定性を実証しています。
Latitude、Cartwheel、Wheringなどの早期導入企業は、このモデルが長期コンテキスト処理と指示追従において安定していると報告しています。eコマース分野では、リアルタイムデータに基づく動的なダッシュボードの生成に利用されており、SaaS業界では、複数ステップのタスクを実行できるインテリジェントエージェントの基盤として活用されています。
優れた点がある一方で、コミュニティからはいくつかの課題も指摘されています。Gemini 3.1 Flash-Lite は冗長性が高く、特定のシナリオでは想定よりも多くのトークンが生成され、コスト増加につながる可能性があります。さらに、プレビュー版では API 使用率のピーク時にレスポンスが変動する問題が発生しており、大規模な商用展開においては技術的な最適化が必要となる要因となります。

