
2026년 3월 4일, 구글은 제미니 3 시리즈의 최신 제품을 공식 발표했습니다.제미니 3.1 플래시라이트이 모델은 특히 높은 동시성을 요구하는 개발자 워크로드와 엔터프라이즈 규모 배포에 최적화되어 있으며, 최대 속도와 비용 효율성을 제공합니다. 공식 기술 문서 및 제3자 평가 데이터 분석을 기반으로 작성된 이 보고서는 모델의 핵심 성능, 비용 및 실제 애플리케이션 지표를 설명합니다.
성과 및 핵심 벤치마크 결과
Gemini 3.1 Flash-Lite는 여러 주요 AI 벤치마크에서 상당한 기술적 경쟁력을 입증했습니다. 데이터에 따르면 아레나.에이 리더보드에서 해당 모델은 Elo 레이팅을 달성했습니다. 1432.에서 GPQA 다이아몬드 전문가 수준의 추론 능력을 측정하는 이 테스트는 다음과 같은 정확도를 달성했습니다. 86.9%득점하는 동안 76.8% 에서 MMMU 프로 다중 모드 이해도 테스트.
데이터에 따르면 Gemini 3.1 Flash-Lite의 전반적인 성능은 동급의 다른 모델들을 능가할 뿐만 아니라 이전 세대의 더 큰 모델보다도 뛰어납니다. 제미니 2.5 플래시 다양한 지표에서 이러한 성능 향상이 나타났습니다. 이러한 성능 도약 덕분에 개발자는 낮은 리소스 사용량을 유지하면서 더 높은 논리적 처리 능력을 확보할 수 있습니다.
경쟁 구도: 세대 간 및 동종업체 비교
2026년 소형 모델 시장에서 Gemini 3.1 Flash-Lite는 주로 다음 제품들과 경쟁합니다. GPT-5 미니 그리고 클로드 4.5 하이쿠이전 모델과의 직접적인 비교를 해보면, 제미니 2.5 플래시이는 기술적 진화를 더욱 잘 보여줍니다.
| 미터법 | 제미니 3.1 플래시라이트 | 제미니 2.5 플래시 | GPT-5 미니 | 클로드 4.5 하이쿠 |
| 출력 속도 | ~363-384 토큰/초 | 초당 약 150~200개 토큰 | 초당 약 71개 토큰 | 초당 약 108개 토큰 |
| 첫 토큰 획득 시간(TTFT) | 가장 빠른 | 기준선 | 더 느리게 | 중간 |
| 생산 가격(백만 단위) | $1.50 | $0.60 | $2.00 | $5.00 |
| SimpleQA 정확도 | 43.30% | 28.50% | 9.50% | 5.50% |
| 컨텍스트 창 | 100만 토큰 | 100만 토큰 | 40만 토큰 | 20만 토큰 |
측정 결과에 따르면 Gemini 3.1 Flash-Lite는 2.5 Flash보다 가격이 높지만 출력 속도는 약 45% 증가했으며, 첫 토큰 획득 시간(TTFT)은 이전 기준치인 40%로 감소했습니다.
비용 효율성의 논리: 토큰 복잡성 대비 가격 비율
커뮤니티 논의에서 제미니 3 플래시 시리즈의 가격 인상이 언급되었지만, 토큰 단위 가격에만 초점을 맞추는 것은 전체적인 맥락을 파악하는 데 부족합니다. 모델 선택의 핵심 기준은 가격 대비 토큰 복잡성의 비율입니다.
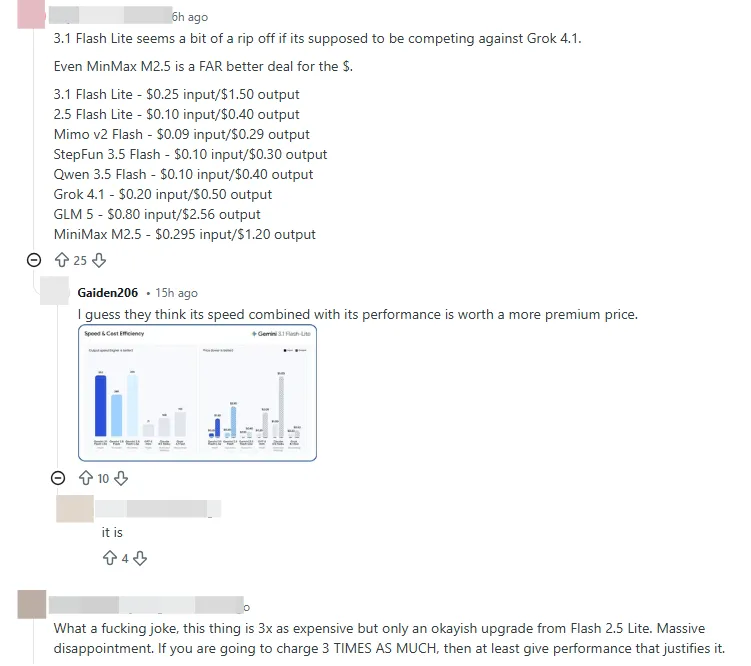
예를 들어, 다른 산업 모델의 경우 Sonnet 5는 단가가 더 낮을 수 있지만, 복잡한 작업에서 동일한 결과를 얻으려면 Opus 4.6보다 훨씬 더 많은 토큰이 필요하여 실제 총비용이 더 높아질 수 있습니다. Gemini 3.1 Flash-Lite의 장점은 토큰당 정보 밀도와 실행 효율성에 있습니다. 개발자는 모델을 선택할 때 벤치마크와 토큰 가격만 고려해서는 안 되며, 해당 모델이 특정 워크플로에 실질적인 개선을 제공하는지 여부에 집중해야 합니다.
커뮤니티 피드백 및 실제 시각적 성능
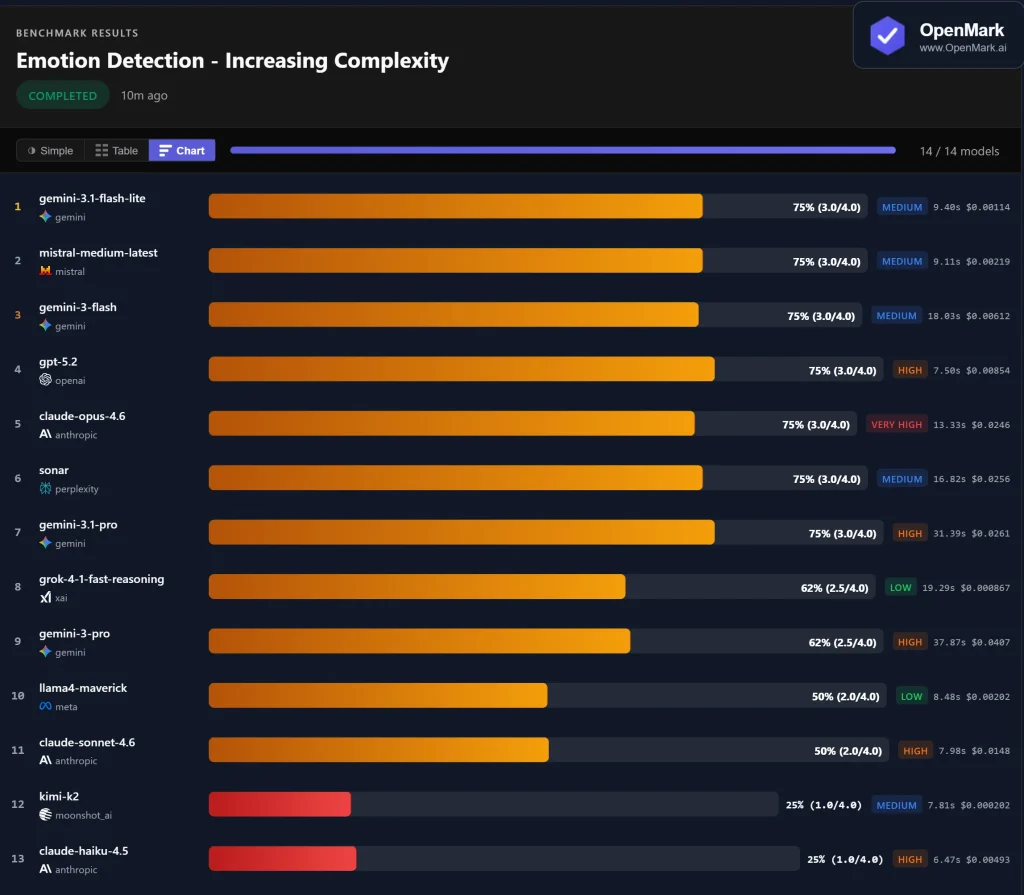
실제 응용 분야에서는 이미 여러 사용자가 대규모 모델 배포를 완료했습니다. 인간 감정 감지를 위한 시각적 벤치마크 테스트에서도 마찬가지입니다. 관련된 대형 모델 14개Gemini 3 Flash는 정확도, 응답 속도 및 토큰 소모량에 대한 종합적인 평가를 바탕으로 1위를 차지했습니다. 이 결과는 복잡한 멀티모달 입력을 처리하는 데 있어 Gemini 3 Flash의 안정성을 입증합니다.
Latitude, Cartwheel, Whering과 같은 초기 도입 기업들은 이 모델이 장시간 컨텍스트 처리 및 명령 추종에서 안정적인 성능을 보인다고 보고했습니다. 전자상거래 분야에서는 실시간 데이터를 기반으로 동적 대시보드를 생성하는 데 사용되고 있으며, SaaS 산업에서는 여러 단계의 작업을 실행할 수 있는 지능형 에이전트를 구동하는 데 활용되고 있습니다.
여러 장점에도 불구하고, 커뮤니티에서는 몇 가지 문제점을 지적했습니다. Gemini 3.1 Flash-Lite는 출력 내용이 장황한 경향이 있어 특정 시나리오에서 예상보다 많은 토큰이 생성되어 비용이 증가할 수 있습니다. 또한, 미리 보기 버전에서는 API 사용량이 최고조에 달할 때 응답 속도 변동이 발생했는데, 이는 대규모 상용 출시 시 기술적 최적화가 필요한 부분입니다.


