
최근 모델 평가에서 계속해서 제기되는 질문 하나가 있습니다. 코딩 에이전트는 단일 응답뿐만 아니라 여러 파일을 편집하고, 반복적인 디버깅을 수행하며, 도구를 사용하는 작업이 포함될 때에도 빠르고 안정적이며 경제적인 성능을 유지할 수 있을까요? MiniMax M2.5는 충분한 구성품을 함께 제공하는 몇 안 되는 제품 중 하나입니다. 엔드투엔드 효율성 및 가격 세부 정보 그 질문을 구체적인 방식으로 검증하기 위해.
내가 M2.5에 주목하는 이유
저는 "최고 벤치마크 점수 하나"에 집중하기보다는 모델이 실제 워크플로우를 완료할 수 있는지에 더 집중합니다.
- 엔드투엔드 배송범위 → 구현 → 검증 → 결과물
- 운영 효율성: 툴 호출 반복 횟수, 토큰 사용량 및 런타임 안정성
- 대리인 경제학가격 책정 모델이 장기 실행 에이전트와 반복 실행을 지원하는지 여부
MiniMax M2.5는 최적화를 목표로 한다는 점에서 흥미롭습니다. 역량, 효율성 및 비용 동일한 릴리스에서 이러한 조합이 이루어진다는 것은 배포 결정을 내리는 엔지니어링 팀에게 중요한 요소입니다.
M2.5는 무엇을 위해 만들어졌는가
~에 근거하여 공식 자료, 미니맥스 M2.5 이 시스템은 세 가지 주요 트랙에 걸쳐 실제 생산성 작업 부하에 맞춰 설계되었습니다.
- 소프트웨어 엔지니어링(에이전트 코딩) 분야SWE-Bench 검증, 멀티 SWE-Bench 인증, 그리고 다양한 하네스 환경에서의 안정적인 성능에 대한 강조로 대표됩니다.
- 대화형 검색 및 도구 사용을 위해BrowseComp, Wide Search, 그리고 전문 웹 소스 내에서의 심층적인 탐색을 반영하도록 설계된 MiniMax의 자체 RISE 벤치마크를 포함합니다.
- 사무 생산성 향상을 위해Word, PowerPoint, Excel에서 결과물 중심의 작업에 초점을 맞추고 있으며, 출력 품질, 에이전트 실행 추적, 토큰 비용을 고려하는 평가 프레임워크(GDPval-MM)를 통해 지원됩니다.
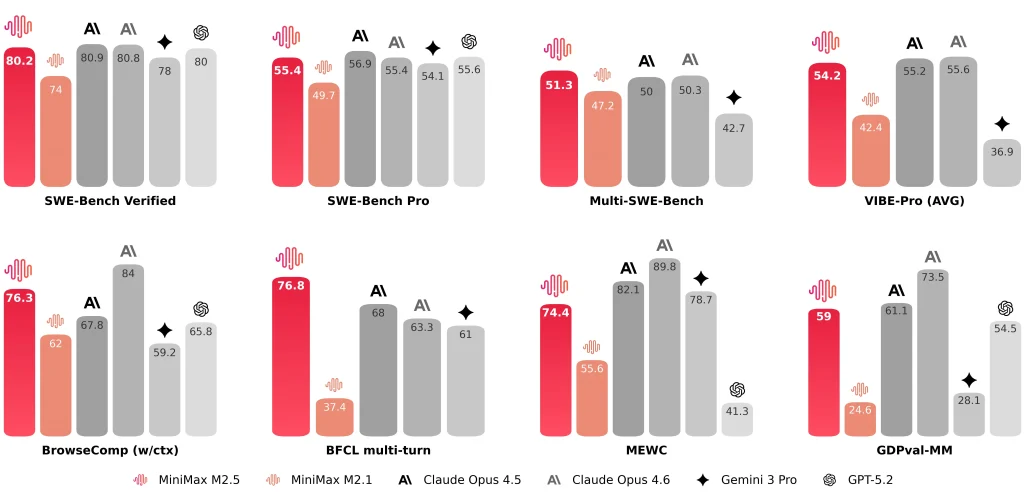
MiniMax는 또한 다음과 같은 대표적인 결과를 공개합니다. SWE-Bench에서 80.2%를 검증했습니다., 멀티 SWE 벤치 51.3%, 그리고 브라우즈컴프 76.3%.
MiniMax M2.5와 M2.1, 그리고 Claude Opus 4.6 비교: 제가 직접 확인해 본 결과입니다
M2.5, M2.1, Claude Opus 4.6 비교 (주요 성능 지표 표)
| 차원 | 엠2.5 | 엠2.1 | 클로드 작품 4.6 |
| SWE-Bench 검증 완료 | 80.20% | 74.0% | 81.42% (인간 활동으로 인한 피해 보고됨) ~78-80% (일반 평균) |
| 소프트웨어 엔지니어링 작업당 평균 소요 시간 | 22.8분 | 31.3분 | 22.9분 |
| SWE 작업당 토큰 수(평균) | 352만 | 372만 | — (장황한 설명 때문에 400만 단어 이상일 가능성이 높음) |
| 검색/도구 반복 vs 이전 세대 | ~20% 더 적은 반복 횟수(보고됨) | 기준선 | — |
| 크로스 하네스 SWE-Bench(드로이드) | 79.7 | 71.3 | 78.9 |
| 크로스 하네스 SWE-Bench(OpenCode) | 76.1 | 72.0 | 75.9 |
| 처리량 옵션 | 초당 약 50개 토큰 (표준) 초당 약 100개 토큰 (라이트닝) | ~57 토큰/초 | 초당 약 67~77개 토큰 |
| 가격 (입력 토큰 100만 개당) | $0.3 (표준 및 라이트닝) | $0.3 | $5.0 |
| 가격 (출력 토큰 100만 개당) | $1.2 (표준) $2.4 (번개) | $1.2 | $25.0 |
| 시간별 직관 (지속적인 출력) | ~$0.3/시간 @ 50 t/s ~$1/시간 @ 100 t/s | ~$0.3/시간 @ 57 t/s | ~$6.50/시간 @ 70 t/s |
참고:
- "—"는 여기에 요약된 자료에 해당 값이 제공되지 않았음을 의미합니다.
- 벤치마크는 하네스, 도구 설정, 프롬프트 및 보고 규칙에 따라 다를 수 있으므로 저는 이를 다음과 같이 취급합니다. 범위 표시기절대적인 순위가 아닙니다.
M2.5 vs M2.1: 더 빠른 엔드투엔드 처리 속도, 더 적은 토큰 사용량, 더 적은 검색 반복 횟수
공식 비교 자료는 엔지니어들이 이해하기 쉬운 방식으로 제시됩니다. 저는 특히 세 가지 지표에 주목합니다.
- 엔드투엔드 런타임평균 SWE 작업 시간이 감소합니다. 31.3분 (M2.1) 에게 22.8분 (M2.5)라고 묘사됨 37% 개선.
- 작업당 토큰: 작업당 토큰 사용량이 감소합니다. 372만 에게 352만.
- 검색/도구 반복 효율성: BrowseComp, Wide Search 및 RISE에서 MiniMax는 더 적은 반복 횟수로 더 나은 결과를 보고하며, 반복 비용은 대략 다음과 같습니다. 20% 하한 M2.1보다.
제게는 이러한 개선 사항들이 단일 벤치마크 점수보다 훨씬 더 중요합니다. 왜냐하면 이러한 개선 사항들이 직접적으로 결과를 결정하기 때문입니다. 에이전트 처리량 그리고 지속 가능한 운영 비용.
M2.5와 Claude Opus 4.6: 유사한 코딩 범위, 평가 맥락이 중요
비교할 때 엠2.5 ~와 함께 클로드 작품 4.6저는 점수를 다음과 같이 취급합니다. 범위 절대적인 순위보다는, 하네스, 도구 구성, 안내 메시지 및 보고 방식이 다를 수 있기 때문입니다.
- 인류학적 메모 Opus 4.6의 SWE 벤치마크 검증 완료 결과는 평균값입니다. 25건의 시험또한 즉각적인 조정을 통해 더 높은 관측값(81.42%)이 나타났다고 언급합니다.
- 미니맥스 보고서 SWE-Bench에서 80.2%를 검증했습니다. ~을 위한 미니맥스 M2.5.
수치상으로는 두 제품 모두 코딩 에이전트 벤치마크에서 비슷한 경쟁력을 보이는 것 같습니다. 하지만 엔지니어링 관점에서 저는 단일 수치보다는 프런트엔드와 백엔드를 포함한 실제 프로젝트 환경, 다양한 프레임워크, 그리고 타사 통합 등에서 안정적인 성능을 보여주는 것을 더 중요하게 생각합니다.
M2.5가 내 작업 흐름을 어떻게 바꾸는지 (실습 후기)
속도 및 워크플로 스타일
통합 후 미니맥스 M2.5 코딩 에이전트 툴체인에 대해 살펴보면 두 가지가 두드러집니다.
- MiniMax M2.5의 속도가 향상되어 단기 작업 반복 처리 속도가 크게 개선되었습니다.실제 작업의 상당수는 "작은 변경 → 실행 → 조정"이라는 반복 과정을 거칩니다. 각 반복 과정에서 대기 시간이 길어지면 컨텍스트 전환 비용이 증가합니다. MiniMax는 "더 빠른 엔드투엔드 처리 속도"와 "토큰 사용량 감소"를 핵심 성과로 명시적으로 강조합니다.
- MiniMax M2.5는 구현 전에 사양서를 작성하는 경향이 있습니다.파일과 모듈이 여러 개인 작업의 경우, 코드를 작성하기 전에 범위 경계, 모듈 간 관계 및 승인 기준을 명시적으로 정의하는 모델을 선호합니다. 이렇게 하면 실행을 감사하고 표준화하기가 더 쉬워지며, M2.5는 이러한 구조에서 뛰어난 성능을 보여줍니다.
이러한 점들을 간과해서는 안 됩니다.
전반적인 성능이 우수하더라도, 저는 여전히 다음과 같은 사항들을 워크플로우 가이드라인이 필요한 제약 조건으로 간주합니다.
- 디버깅 전략이 항상 선제적인 것은 아닙니다.위치 파악이 어려운 버그의 경우, 모델은 자동으로 단위 테스트, 로깅 또는 최소한의 재현 단계로 전환하지 않고 구현을 반복적으로 수정할 수 있습니다. 저는 종종 "로그 추가/테스트 작성/실패 경로 좁히기"와 같이 명시적으로 지시해야 합니다.
- 외부 검색 및 타사 통합은 신뢰할 수 없을 수 있습니다.특정 외부 서비스를 통합할 때 모델이 잘못된 통합 단계를 생성할 수 있습니다. 저는 "검색을 통해 생성된" 코드에 의존하는 대신 공식 문서의 예제를 사용하여 입력값을 제한하는 것을 선호합니다.
- 코드와 문서의 동기화가 항상 기본값으로 설정되는 것은 아닙니다."코드를 업데이트하고 문서/Skill 마크다운도 업데이트해야 하는" 작업의 경우, 코드만 업데이트되는 실수를 방지하기 위해 명확한 체크리스트를 사용합니다.
이러한 제약 조건은 M2.5에만 국한된 것이 아니라, 제가 대부분의 코딩 에이전트 워크플로에 적용하는 가이드라인입니다.
이 단계에서 저는 다음과 같이 생각합니다. 미니맥스 M2.5 ~로서 공학 지향적 에이전트 생산성 모델이 도구는 벤치마크 결과만 제공하는 것이 아니라, 엔드 투 엔드 실행 시간, 토큰 소비량, 반복 효율성 및 가격 구조까지 공개하므로 일관된 지표 세트를 사용하여 실제 배포 비용을 평가할 수 있습니다.
일부 사용자는 코딩 전에 사양서를 작성하는 것이 토큰 비용을 증가시키고 "저비용"이라는 주장을 약화시키는 것은 아닌지 의문을 제기할 수 있습니다. 제 실질적인 결론은 다음과 같습니다.
- 네, Spec을 작성하면 출력 토큰이 몇 개 추가됩니다.
- 실제 워크플로우에서 이러한 비용은 재작업 횟수 감소와 반복적인 수정 횟수 감소로 상쇄되는 경우가 많습니다.특히 여러 파일, 여러 모듈 또는 디버깅 작업이 많은 경우에 유용합니다.
- 일반적으로 사양서가 지나치게 길지 않고 구현 세부 사항을 반복하지 않는 한 오버헤드는 제어 가능합니다.
스펙 토큰 오버헤드를 최소화하기 위한 몇 가지 실용적인 팁을 소개합니다.
- 간단한 작업의 경우: "사양서 없이 코드 차이점과 테스트 단계를 제공해 주세요."라고 명시적으로 요청하세요.
- 중대형 작업용: 사양을 제한합니다 X줄 / X개 글머리 기호 (예: 10~15)에만 초점을 맞추어 구조 및 승인 기준구현 세부 사항이 아닙니다.
- 에이전트 툴체인에서: 사양을 다음과 같이 취급하십시오 진실의 단일 원천요구사항이 변경될 경우, 먼저 관련 사양 섹션을 업데이트한 후 코딩 및 검증을 진행하십시오. 이렇게 하면 맥락을 다시 설명하는 데 드는 반복적인 작업과 숨겨진 토큰 낭비를 줄일 수 있습니다.


