
最近のモデル評価では、1 つの疑問が繰り返し浮かび上がります。 コーディングエージェントは、タスクに単一の回答だけでなく、複数ファイルの編集、繰り返しのデバッグ、ツールの使用が含まれる場合、高速で信頼性が高く、手頃な価格を維持できますか? MiniMax M2.5は、十分な機能を備えた数少ないリリースの1つです。 エンドツーエンドの効率性と価格の詳細 その疑問を具体的に検証する。
M2.5に注目する理由
私は「1つの最高のベンチマークスコア」よりも、モデルが実際のワークフローを完了できるかどうかに重点を置いています。
- エンドツーエンドの配信: スコープ → 実装 → 検証 → 成果物
- 運用効率: ツール呼び出しの反復、トークンの使用、および実行時の安定性
- エージェント 経済: 価格モデルが長時間実行されるエージェントと繰り返しの反復をサポートしているかどうか
MiniMax M2.5は、最適化を目的としているため興味深いです。 能力、効率、コスト これは、デプロイメントの決定を行うエンジニアリング チームにとって重要な組み合わせです。
M2.5の目的
に基づいて 公式資料, ミニマックス M2.5 3 つの主要なトラックにわたる実際の生産性ワークロード向けに位置付けられています。
- ソフトウェアエンジニアリング(エージェントコーディング): SWE-Bench Verified、Multi-SWE-Bench に代表され、さまざまなハーネスにわたる安定したパフォーマンスを重視しています。
- インタラクティブな検索とツールの使用: BrowseComp、Wide Search、およびプロフェッショナル Web ソース内のより深い調査を反映するように設計された MiniMax の社内 RISE ベンチマークが含まれます。
- オフィスの生産性向上: Word、PowerPoint、Excel での成果物指向のタスクに焦点を当てており、出力品質、エージェント実行トレース、トークン コストを考慮した評価フレームワーク (GDPval-MM) によってサポートされています。
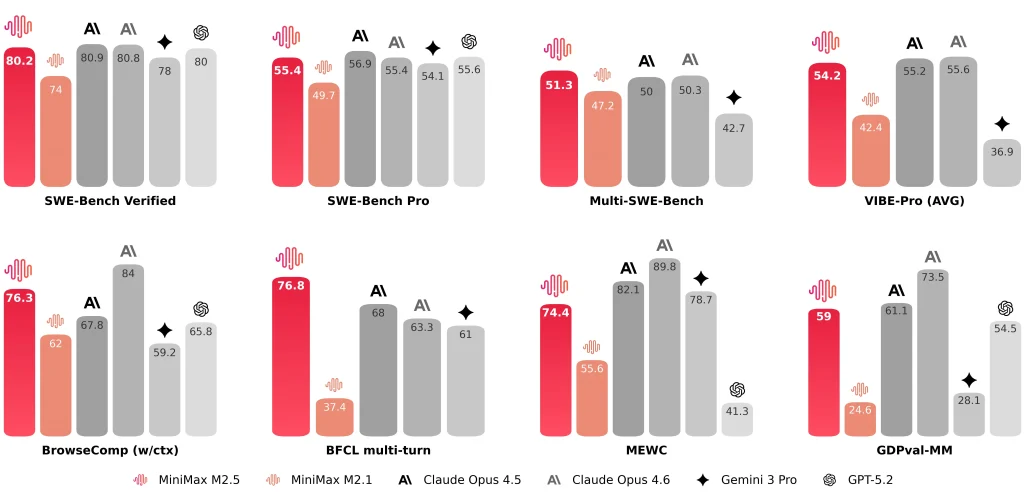
MiniMaxは次のような代表的な結果も公開しています。 SWE-ベンチ検証済み 80.2%, マルチSWEベンチ51.3%、 そして ブラウズコンプ 76.3%.
MiniMax M2.5とM2.1、Claude Opus 4.6の比較
M2.5 vs M2.1 vs Claude Opus 4.6(主要指標表)
| 寸法 | M2.5 | M2.1 | クロード・オプス 4.6 |
| SWE-ベンチ検証済み | 80.20% | 74.0% | 81.42% (アントロピックの報告) ~78-80%(公立平均) |
| SWE タスクあたりの平均エンドツーエンド時間 | 22.8分 | 31.3分 | 22.9分 |
| SWE タスクあたりのトークン数(平均) | 352万 | 372万 | — (冗長性のため 4M を超える可能性があります) |
| 検索/ツールの反復と前世代との比較 | 反復回数が約20%減少(報告) | ベースライン | — |
| クロスハーネスSWEベンチ(ドロイド) | 79.7 | 71.3 | 78.9 |
| クロスハーネス SWE-Bench (OpenCode) | 76.1 | 72.0 | 75.9 |
| スループットオプション | 約50トークン/秒(標準) 約 100 トークン/秒 (Lightning) | 約57トークン/秒 | ~67-77トークン/秒 |
| 価格(100万入力トークンあたり) | $0.3 (標準 & Lightning) | $0.3 | $5.0 |
| 価格(100万出力トークンあたり) | $1.2(標準) $2.4(ライトニング) | $1.2 | $25.0 |
| 時間ごとの直感(連続出力) | 約$0.3/時 @ 50 t/s 約$1/時 @ 100 t/s | 約$0.3/時 @ 57 t/s | 約$6.50/時 @ 70 t/s |
注:
- 「—」は、ここでまとめた資料では値が提供されなかったことを意味します。
- ベンチマークはハーネス、ツールの設定、プロンプト、レポートの慣例によって異なる可能性があるため、 範囲インジケーター絶対的なランキングではありません。
M2.5 vs M2.1: エンドツーエンドの高速化、トークン使用量の削減、検索反復回数の削減
公式の比較はエンジニアリングに分かりやすい形で提示されています。私は特に以下の3つの指標に注目しています。
- エンドツーエンドのランタイム: 平均SWEタスク時間は 31.3分(M2.1) に 22.8分(M2.5)、と表現される 37%の改良.
- タスクごとのトークン: タスクあたりのトークン使用量は、 372万 に 352万.
- 検索/ツールの反復効率: BrowseComp、Wide Search、RISEでは、MiniMaxは反復回数が少なくてもより良い結果を報告しており、反復コストはおよそ 20% ロワー M2.1よりも。
私にとって、これらの改善は単一のベンチマークスコアよりも重要です。なぜなら、それが直接的に決定するからです。 エージェントスループット そして 持続可能な運用コスト.
M2.5 vs Claude Opus 4.6: 類似したコーディング範囲、評価コンテキストが重要
比較すると M2.5 と クロード・オプス 4.6私はスコアを次のように扱います 範囲 ハーネス、ツール構成、プロンプト、レポート規則が異なる可能性があるため、絶対的なランキングではなく、全体的なランキングが重要です。
- 人類学的 指摘する Opus 4.6のSWEベンチ検証 結果は平均以上 25回の試行、プロンプト調整下ではより高い観測値(81.42%)が報告されています。
- MiniMaxレポート SWE-ベンチ検証済み 80.2% のために ミニマックス M2.5.
数値的に見ると、コーディングエージェントのベンチマークでは両者はほぼ同程度の競争力があるように見えます。エンジニアリングの観点から言えば、私は単一の見出しの数字よりも、実際のプロジェクト形態(フロントエンドとバックエンド、異なるスキャフォールド、サードパーティとの統合など)における安定性を重視しています。
M2.5 が私のワークフローをどう変えるのか(ハンズオンノート)
スピードとワークフロースタイル
統合後 ミニマックス M2.5 コーディングエージェントのツールチェーンに組み込むと、2 つの点が際立ちます。
- MiniMax M2.5の速度は、短いタスクの反復を大幅に改善します実際のタスクの多くは、「小さな変更 → 実行 → 調整」というループを辿ります。各ループで長い待機が発生すると、コンテキストスイッチのコストが増大します。MiniMaxは、「エンドツーエンドの高速化」と「トークン使用量の削減」を主要な成果として明確に強調しています。
- MiniMax M2.5は実装前に仕様書を書く傾向がある複数ファイルおよび複数モジュールのタスクの場合、コードを書く前に、スコープ境界、モジュールの関係、受け入れ基準を明示的に把握できるモデルを推奨します。これにより、実行の監査と標準化が容易になり、M2.5はこの構造下で良好なパフォーマンスを発揮します。
これらの点は見逃してはならない
全体的なパフォーマンスが優れていても、次の点については、ワークフローのガードレールを必要とする制約として扱います。
- デバッグ戦略は必ずしも積極的ではない: 特定が難しいバグの場合、モデルはユニットテスト、ログ記録、最小限の再現手順に自動的に切り替えることなく、実装を繰り返し変更することがあります。そのため、「ログを追加する / テストを書く / 失敗パスを絞り込む」などの指示を明示的に行う必要があることがよくあります。
- 外部検索やサードパーティ統合は信頼できない可能性がある: 特定の外部サービスを統合する際に、モデルが誤った統合手順を生成する可能性があります。「取得アセンブル」されたコードに頼るのではなく、公式ドキュメントの例で入力を制約することを好みます。
- コードとドキュメントの同期は一貫してデフォルトではない: タスクに「コードを更新し、ドキュメント/スキル マークダウンも更新する」ことが必要な場合は、明示的なチェックリストを使用して、コードのみが更新される可能性を減らします。
これらの制約は M2.5 に固有のものではなく、ほとんどのコーディング エージェント ワークフローに適用するガードレールです。
この段階で私は ミニマックス M2.5 として エンジニアリング指向のエージェント生産性モデルベンチマーク結果を提供するだけでなく、エンドツーエンドのランタイム、トークン消費量、反復効率、価格体系も公開されるため、一貫した一連の指標を使用して実際の導入コストを評価できます。
コーディング前にスペックを生成するとトークンコストが増加し、「低コスト」という主張が損なわれるのではないかと疑問に思うユーザーもいるかもしれません。私の実践的な結論は次のとおりです。
- はい、Spec を記述すると、いくつかの出力トークンが追加されます。
- 多くの実際のワークフローでは、そのコストはやり直しのループと繰り返しの回数の減少によって相殺されます。特に、複数ファイル、複数モジュール、またはデバッグが多いタスクに適しています。
- 仕様が過度に長くなく、実装の詳細を繰り返さない限り、オーバーヘッドは通常制御可能です。
スペックトークンのオーバーヘッドを最小限に抑えるための実用的なヒントをいくつか紹介します。
- 小さなタスクの場合: 「仕様は不要。コードの差分とテスト手順を提供してください。」と明示的に要求します。
- 中規模/大規模タスク向け: スペックを制約する X行 / X箇条書き (例:10~15)のみに焦点を当てる 構造と受け入れ基準実装の詳細ではありません。
- エージェントツールチェーン: スペックを 真実の唯一の情報源要件が変更された場合は、まず関連する仕様セクションを更新し、その後コーディングと検証に進みます。これにより、説明の重複や、文脈を改めて述べることによる隠れたトークンの無駄を削減できます。

