
1月27日、DeepSeekはOCR 2をオープンソースモデルとしてリリースしました。 技術レポートこれは、AIが視覚データを理解する方法における体系的な変化を表していると私は考えています。DeepSeekは、単にパラメータ数を増やすのではなく、従来の視覚言語モデル(VLM)の限界を超えてパフォーマンスを向上させるために、根本的なアーキテクチャの変更に重点を置きました。
DeepSeek OCR 2は単なるテキスト認識以上のもの
DeepSeek OCR 2は、30億のパラメータを備えた次世代の視覚言語モデルです。Tesseractや基本的な視覚モデルといった従来のツールとは大きく異なります。OCR 2は、以下の2つの目標を重視しています。
- 正しい読み順: 複数列のテキスト、脚注、およびヘッダーと本文の関係の適切な順序を維持します。
- 安定したレイアウト構造: これにより、表、リスト、混合コンテンツが使用可能な構造にフォーマットされます。
データベースエントリ用の PDF スキャンを処理したり、RAG システムのデータをクリーンアップしたり、複雑な財務レポートを解析したりする必要がある場合、OCR 2 は高い精度と論理的な再構築を提供します。
アーキテクチャのイノベーション: DeepSeek OCR 2 がなぜそれほど効率的なのか?
CLIPを言語モデルに置き換える
古い視覚モデルの多くは、画像処理コンポーネントとしてCLIPを使用しています。CLIPは画像とテキストラベルを対応付けるために設計されましたが、密度の高い文書内の異なる部分間の論理的な関係を理解する能力が欠けていました。
ディープシーク 解決: 彼らは クウェン2-0.5B (LLM ベースのアーキテクチャ) をビジョン エンコーダの中核として使用します。
メリット: エンコーダーは言語モデルに基づいているため、視覚トークンは初期段階で基本的な推論能力を備えています。このモデルは、どのピクセルがヘッダーに属し、どのピクセルがテーブル境界に属するかを識別できるため、より正確なデータ処理が可能になります。
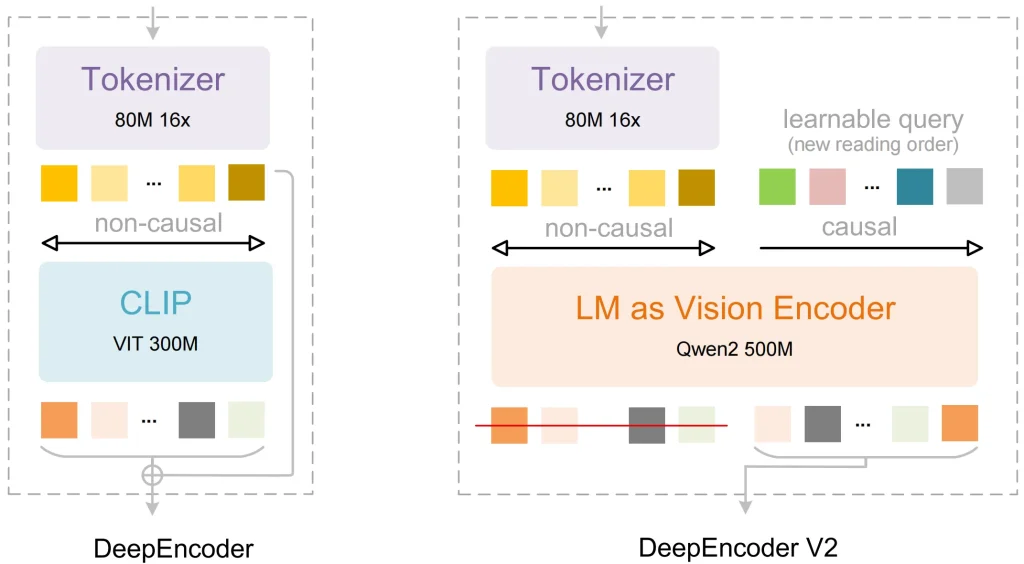
DeepEncoder V2とビジュアル因果フロー
これはOCR 2における最も重要な技術的進歩です。多くのモデルは、画像を左上から右下への固定グリッドで処理します。この固定順序は、モデルが複雑な表や複数列のページを検出すると、しばしばエラーを引き起こします。
ディープシーク 解決: 彼らは付け加えた 視覚的な因果フロー DeepEncoder V2 コンポーネントへ:
- モデルは最初にページ全体のグローバル情報を収集します。
- 学習可能なクエリを使用して、視覚トークンを並べ替えます。
- この論理的に整理されたシーケンスをデコーダーに送信してテキストを生成します。
これにより、モデルはデータの実際の意味に基づいて情報を収集できます。情報はエンコード段階でレイアウトとセマンティクスに基づいて整理されるため、最終的な出力は非常に安定しています。
| メトリック | 従来のOCRモデル | ディープシークOCR2 |
| 読み取り順序エラー | 高い(柱との格闘) | 大幅に低下(編集距離が0.057に低下) |
| トークン圧縮 | 低(ページあたり数千トークン) | 非常に高い(1ページあたり256~1120トークン) |
| 安定性/精度 | 繰り返しや間違いが起きやすい | 97% 精度(10倍圧縮時) |
視覚的符号化を推論へと移行する
専門家はOCR 2を「言語モデル駆動型ビジョンエンコーダー」と表現しています。これは、エンコーダーが基本的な視覚的特徴を抽出するだけでなく、空間関係と構造情報に重点を置いていることを意味します。
結果:
OmniDocBench v1.5プロフェッショナルテストにおいて、OCR 2は91.09というスコアを達成しました。これは前バージョンから3.73ポイントの向上です。この進歩は主に、読み取り順序の精度と複雑なレイアウトの処理において顕著でした。
DeepSeek OCR 2の使い方:3つの高速導入方法
DeepSeekはHugging Faceのモデル重みを公開しました。制作や研究目的でモデルにアクセスするには、以下の3つの方法があります。
方法1: FastFine-Tuning経由 怠惰な(推奨)
Unsloth は OCR 2 用に最適化されており、メモリ使用量を大幅に削減します。
from unsloth import FastVisionModel import torch # モデルをロードします model, tokenizer = FastVisionModel.from_pretrained( "unsloth/DeepSeek-OCR-2", load_in_4bit = True, # メモリを節約するために4ビット量子化を使用します ) # プロンプトテンプレート prompt = " \n<|grounding|>このドキュメントを Markdown に変換し、すべての表を抽出してください。"方法2: vLLMによる高性能推論
これは、一度に多数のリクエストを処理する必要がある組織にとって最適な選択肢です。
- 設定: DeepSeekでは、
温度最も一貫した結果を得るには 0.0 に設定します。 - 言語サポート: プロンプトでターゲット言語を指定できます。100以上の言語をサポートしています。
方法3:標準的なハグフェイストランスフォーマー
柔軟性を最大限に高めるには、標準ライブラリを使用します。
- 要件をインストールします:
pip トランスフォーマーのインストール einops addict easydict. - モデルをロードします。
AutoModel.from_pretrained("deepseek-ai/DeepSeek-OCR-2", trust_remote_code=True).
ヒント: 傾いたスキャンを処理する場合、画像を 0.5 度回転させてまっすぐにすることで、モデルがさらに優れた結果を生成できるようになります。
AI業界を長年観察してきた経験から、DeepSeekはコアアルゴリズムの最適化において常に先駆者として活動してきました。私は、彼らの 最初のOCRモデル 2025年10月にはすでに効率性向上のためにトークン圧縮を採用していました。
OCR 2は単なるパフォーマンスのアップデートではありません。AIが視覚ロジックを処理する方法に根本的な変化をもたらします。視覚エンコーディングに言語モデルアーキテクチャを用いることで、DeepSeekはAIが複雑なデータを理解する深度を向上させました。これらの取り組みは、AIの高い先進性を示すものだと私は考えています。基礎レベルで情報を整理するこの手法により、AIは人間の論理に近い方法で読み取ることができ、将来の正確なデータ抽出のための新たな基準を提供します。


